L'informatique sans serveur pour plus de services

 Share on Twitter
Share on TwitterPartager sur Twitter

 Share on LinkedIn
Share on LinkedInPartager sur LinkedIn

 Share on Facebook
Share on FacebookPartager sur Facebook

 Share by Email
Share by EmailPartage par e-mail

 Print this page
Print this pageImprimer
Nous sommes toujours impressionnés par les différentes façons dont les gens se servent d'Elasticsearch® pour résoudre les plus grands défis auxquels ils sont confrontés avec les données. Les chiffres sont parlants : plus de 4 milliards de téléchargements, 70 000 validations, 1 800 contributeurs, sans compter les commentaires de notre communauté mondiale. Le rôle joué par Elastic® dans de nombreux cas d'utilisation nous a conduits à simplifier les choses, pour qu'il soit plus facile de faire des recherches et de tirer le meilleur parti de nos solutions. C'est pourquoi nous sommes très enthousiastes à l'idée de décupler les possibilités d'Elasticsearch avec une nouvelle architecture sans serveur. Cette architecture rationalise les responsabilités opérationnelles, étend les performances de vitesse qui font la réputation d'Elasticsearch aux services de stockage d'objets scalables et simplifie les workflows avec des expériences produit spécialement conçues pour la recherche, l'observabilité et la sécurité. C'est une manière innovante d'utiliser Elastic en parallèle de nos déploiements existants sur site et dans Elastic Cloud.
Regroupez vos données, et l'informatique sans serveur fera le reste
Pour la décennie à venir, nous estimons qu'il est nécessaire de proposer une expérience utilisateur plus simple, avec des performances toujours aussi efficaces. Nous savons que de nombreux Elasticiens veulent exercer un contrôle total sur le déploiement et la scalabilité, mais nous avons aussi que d'autres préfèrent la simplicité. Par exemple, les analystes du centre opérationnel de sécurité veulent protéger leurs organisations, pas avoir à scaler des partitions pour bénéficier d'une meilleure détection des menaces. Les développeurs veulent créer des applications de recherche, pas avoir à ajuster l'infrastructure pour accélérer les requêtes. Les ingénieurs SRE veulent garantir la fiabilité en ligne, pas avoir à définir des configurations pour limiter les indisponibilités. Nous, nous aimons gérer les clusters, mais ça n'est pas forcément votre cas ! Et c'est pour ça que nous sommes là. L'architecture sans serveur d'Elastic supprime la responsabilité opérationnelle. Vous n'avez plus qu'à dire au revoir à la gestion des clusters, la configuration des partitions, le scaling et la configuration de la gestion du cycle de vie des index. Regroupez tout simplement vos données et vos requêtes, et la plateforme se chargera du scaling et de la gestion.
Vous en avez marre qu'on vous dise que vous ne pouvez pas scaler plus rapidement tout en conservant vos données plus longtemps, et en même temps équilibrer vos coûts et réduire la complexité ? Tant mieux. Parce que c'est ce que nous proposons. Pour de nombreuses charges de travail, le scaling et la vitesse comptent. Vous pouvez par exemple devoir examiner des menaces comme SolarWinds, dont la détection prend du temps, ou identifier la cause première d'un dysfonctionnement sur des centaines de services, ou encore utiliser la recherche vectorielle pour optimiser des charges de travail d'IA générative avec la génération augmentée de récupération.
C'est pour toutes ces raisons que notre architecture sans serveur se base sur une version revue et repensée d'Elasticsearch, qui sépare entièrement le calcul et le stockage, et qui s'appuie sur le stockage d'objets. Les services cloud de stockage d'objets proposent une scalabilité économique, mais sont souvent plus lents, ce qui nécessite d'appliquer de nouvelles techniques pour les accélérer. Heureusement, nous pouvons compter sur nos années d'expérience pour pallier ce problème de latence, en mettant à profit ce que nous avons appris en optimisant Elasticsearch et les structures de données des index Lucene pour une mise en cache plus efficace, ainsi qu'en améliorant la parallélisation des temps de requête. Ce que nous voulons dire, c'est que vous pouvez bénéficier à la fois de la vitesse et du scaling grâce à des contrôles intégrés qui vous permettent d'équilibrer la vitesse et les coûts.
Une nouvelle architecture Elastic pour le futur
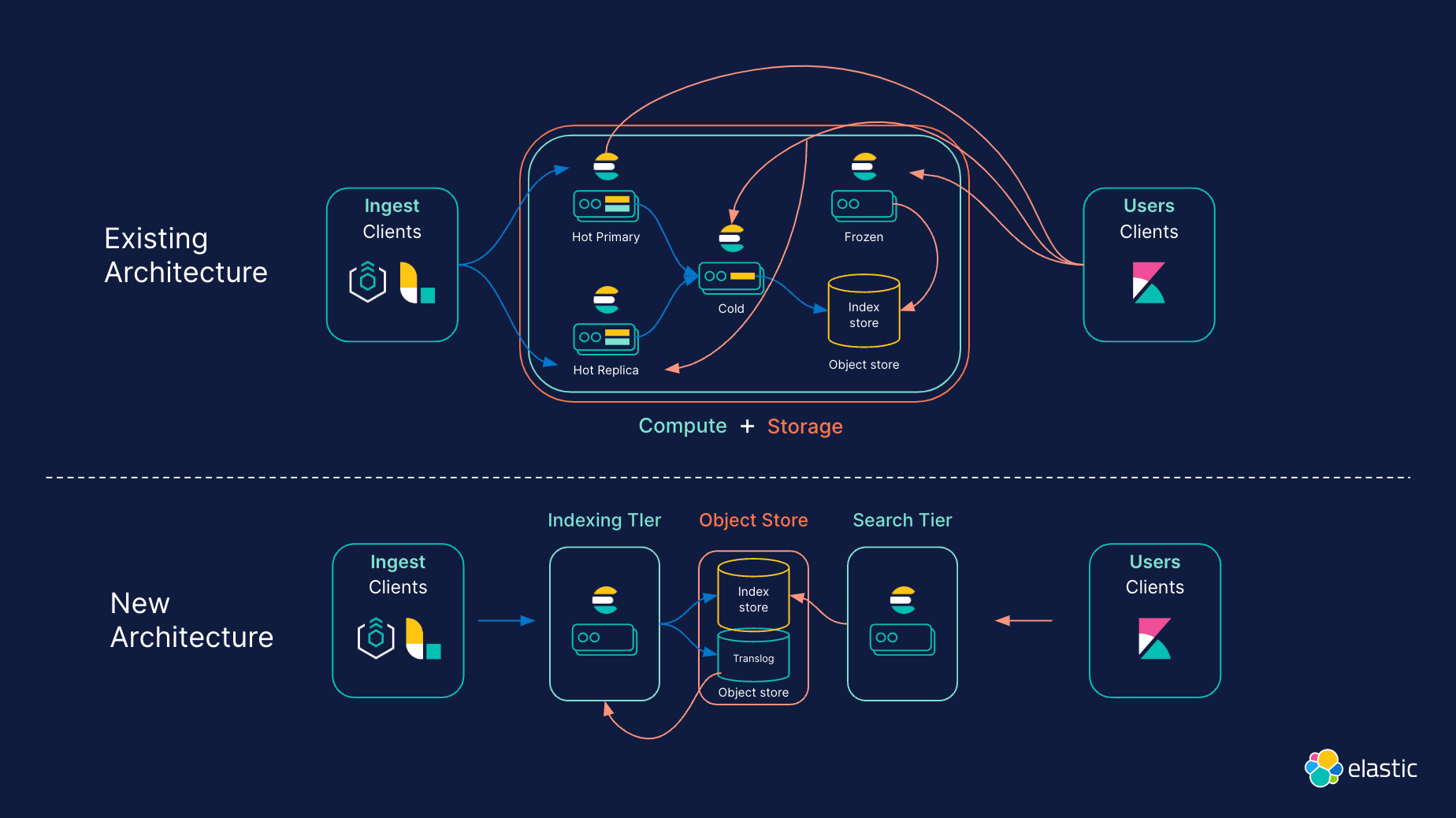
La nouvelle architecture sans serveur d'Elastic constitue un remaniement significatif de la conception d'Elasticsearch. Elle a été imaginée pour tirer parti des services cloud-native les plus récents et pour offrir des expériences produit optimisées, sans prise de tête. Elle fournit la capacité de stockage d'un lac de données, avec la rapidité de recherche qui fait la réputation d'Elasticsearch, tout en offrant une simplicité opérationnelle inégalée avec une gestion et un scaling des clusters sans intervention. Cette architecture s'appuie sur quatre principes de base :
- Une séparation du calcul et du stockage
- Une séparation de la recherche et des niveaux d'indexation
- Un stockage d'objets peu coûteux comme système d'enregistrement
- Une faible latence des requêtes
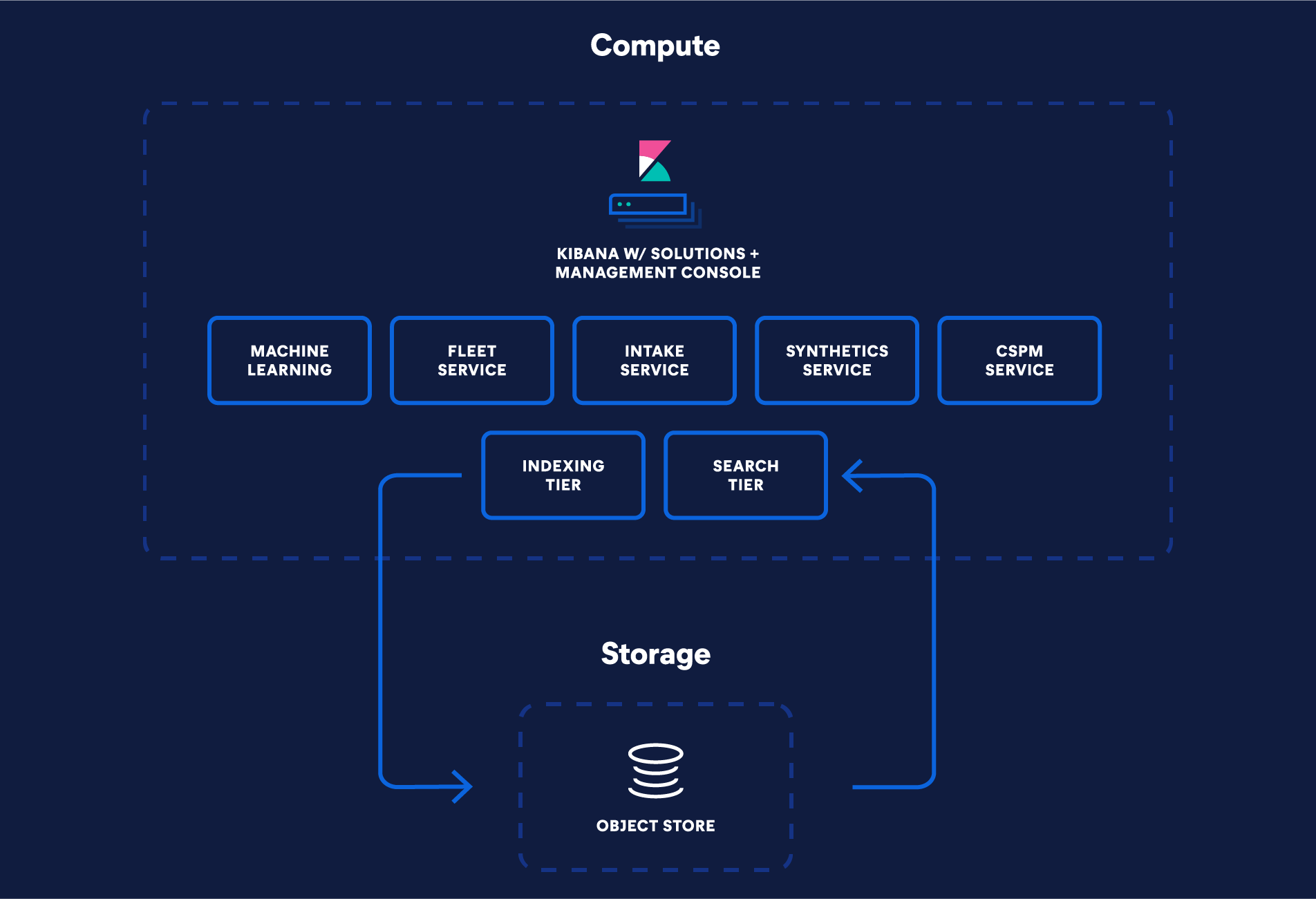
Un stockage et un calcul totalement distincts
Pour simplifier la topologie des clusters, le calcul et le stockage sont désormais totalement distincts. Actuellement, Elasticsearch propose différents niveaux de données (hot, warm, cold et frozen) pour mieux aligner les données sur les exigences matérielles. Dans l'architecture sans serveur, ces niveaux de données deviennent inutiles, puisque le stockage et le calcul sont séparés. Les opérations sont donc plus simples. Par exemple, l'architecture sans serveur fusionne les niveaux hot et frozen : les index du niveau frozen peuvent stocker de grands volumes de données moins consultées, mais tout comme dans le niveau hot, ces données peuvent être mises à jour et interrogées rapidement à tout moment.
En outre, des contrôles simples permettent d'équilibrer les performances de recherche et les coûts de stockage avec efficacité. Il est donc possible de scaler n'importe quelle charge de travail de façon indépendante, avec rapidité et fiabilité, sans sacrifier les performances.
Séparation des niveaux d'indexation et de recherche
Plutôt que de s'appuyer sur des instances primaires et des répliques pour gérer les nombreuses charges de travail, l'architecture sans serveur d'Elastic prend en charge des niveaux d'indexation et de recherche distincts. Concrètement, qu'est-ce que cette séparation implique ? Que les charges de travail puissent être scalées en toute indépendance, et que le matériel puisse être sélectionné et optimisé pour chaque cas d'utilisation.
De plus, cette approche résout efficacement le problème persistant d'interférences entre les charges de travail de recherche et d'indexation. Il est donc plus simple d'optimiser à la fois les performances et les coûts, quel que soit le cas d'utilisation ou la charge de travail de recherche. Cette propriété est importante pour les utilisateurs de logging et de sécurité qui gèrent d'énormes volumes de données et qui veulent empêcher que de lourdes recherches ne viennent empiéter sur les opérations d'indexation, ainsi que pour les utilisateurs de recherche qui souhaitent utiliser des fonctionnalités d'indexation conséquentes pour optimiser la pertinence et la recherche, sans nuire à leurs performances de recherche.
Un stockage d'objets économique
L'architecture sans serveur s'appuie sur un stockage d'objets peu coûteux qui permet une plus grande scalabilité, tout en réduisant les coûts de stockage. En s'appuyant sur un stockage d'objets pour conserver les données, Elasticsearch n'a plus besoin de reproduire les opérations d'indexation sur une ou plusieurs répliques aux fins de durabilité, ce qui réduit les coûts d'indexation et rend inutile la duplication des données. À la place, les segments sont conservés et répliqués sur le stockage d'objets. Cette approche permet des gains d'efficacité. Par exemple, les dépenses de stockage pour le niveau d'indexation sont réduites grâce à la diminution des données stockées sur les disques locaux. L'architecture sans serveur procède à une indexation directe sur le stockage d'objets. De ce fait, seule une fraction des données est conservée en local. Pour les scénarios impliquant uniquement des ajouts, il n'est nécessaire de conserver que certaines métadonnées spécifiques pour l'indexation. Le stockage local s'en trouve donc grandement réduit.
Des requêtes à faible latence à grande échelle
Les stockages d'objets sont réputés pour les volumes de données massifs qu'ils peuvent prendre en charge, mais pas pour leur vitesse ou leur faible latence. Alors, comment fait Elastic pour utiliser le stockage d'objets et assurer des performances de requête optimales ? Nous avons introduit de nouvelles capacités pour offrir des performances rapides. La parallélisation des requêtes au niveau des segments réduit la latence lors de la récupération des données à partir du stockage d'objets. Il est donc possible de placer rapidement un plus grand nombre de requêtes dans des stockages d'objets, comme S3, lorsque les données ne se trouvent pas dans le cache local. La mise en cache est également devenue "plus intelligente", grâce à la réutilisation et à l'exploitation des formats d'index Lucene optimaux pour chaque type de données. Ce ne sont là que quelques-unes de ces nouvelles capacités. Et grâce à elles, nous bénéficions d'améliorations significatives en termes de performances, aussi bien pour la couche du stockage d'objets que celle de la mise en cache.
Travaillez plus intelligemment avec des produits spécialement conçus sur une architecture sans serveur
Nous profitons également de cette opportunité pour concevoir des produits personnalisés pour la recherche, l'observabilité et la sécurité sur une architecture sans serveur. Le but de ces produits est de s'adapter aux besoins uniques de chaque workflow tout en proposant une expérience utilisateur rationalisée. Cela passe par une prise en main plus rapide et continue, une intégration plus étroite des capacités et une optimisation des interfaces personnalisées pour les tâches de chaque cas d'utilisation. Voici les avantages pour chaque produit :
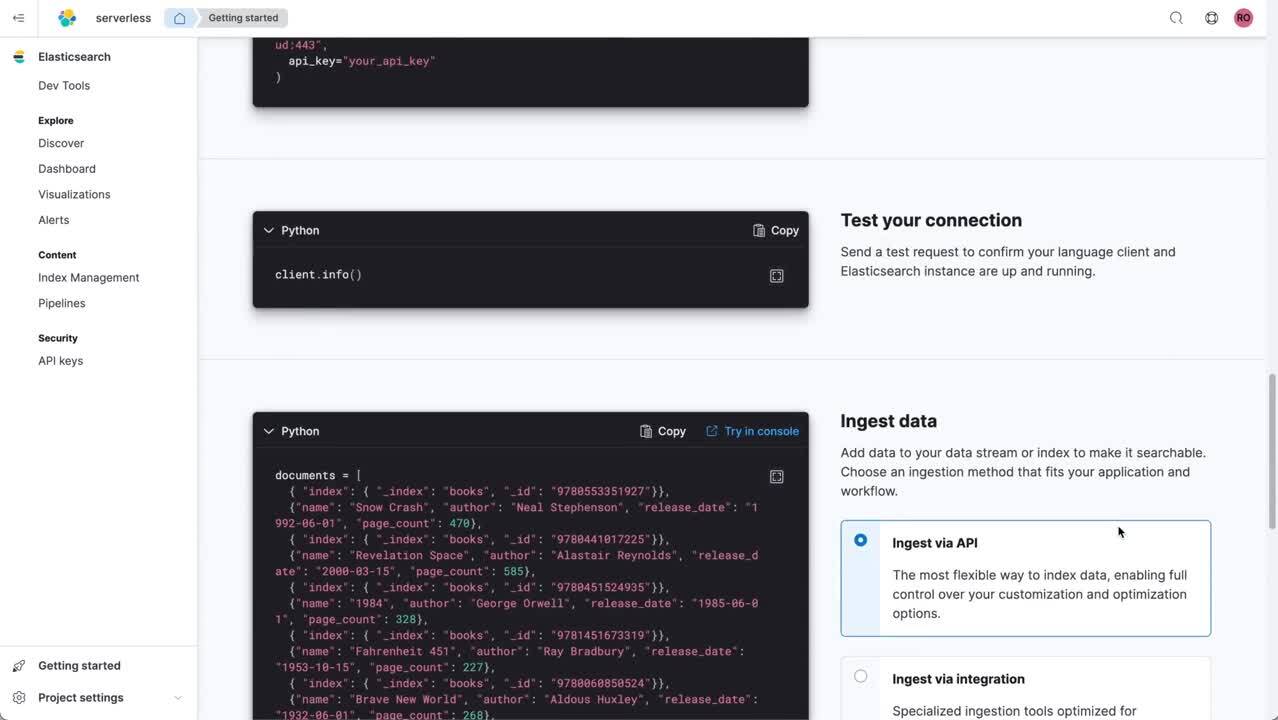
- Recherche : l'expérience de recherche sans serveur a pour but de permettre aux développeurs de créer des expériences de recherche exceptionnelles avec rapidité et facilité. Les API jouent un rôle clé, tandis que l'ingestion et le rassemblement des données dans Elasticsearch se font avec facilité. Ces pipelines ont été simplifiés pour pouvoir exécuter rapidement différentes tâches, notamment une transformation. De nouveaux clients de langage, comme Java, .NET et Python, ont été créés pour réduire la courbe d'apprentissage initiale et le nombre d'étapes requises pour achever les tâches, avec la documentation correspondante. Mis bout à bout, ces éléments simplifient l'expérience des développeurs pour leur permettre de générer de la valeur plus rapidement.
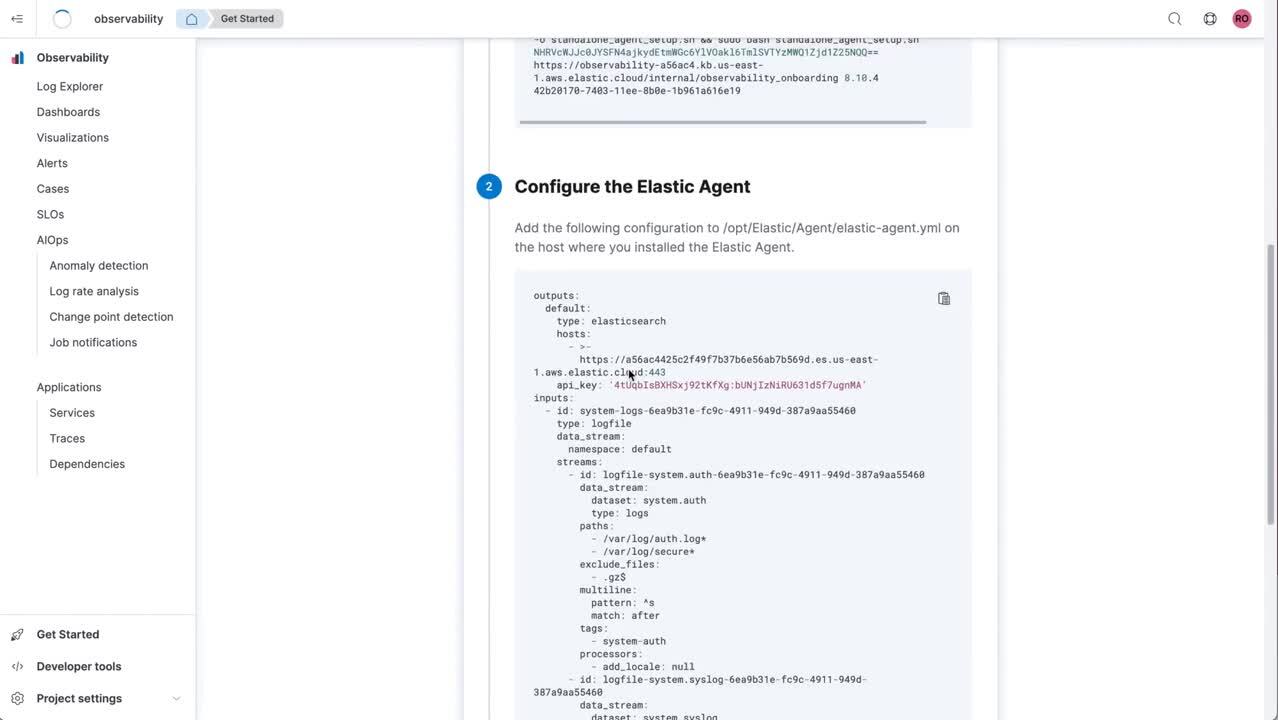
- Observabilité : sur une architecture sans serveur, l'observabilité permet aux ingénieurs de se concentrer sur ce qui compte vraiment pour eux : assurer la fiabilité de leurs systèmes et de leurs applications. La rentabilité est un principe clé : qui dit rationalisation du regroupement des logs, dit simplification du processus d'ingestion des données. En parallèle, le Machine Learning et l'AIOps aident les ingénieurs SRE à repérer rapidement les comportements anormaux et à en identifier la cause première. Autre composant important : le nouveau service d'ingestion géré, qui facilite l'acceptation, le traitement et l'indexation des données d'OpenTelemetry et d'Elastic APM. Les services sont adossés à une architecture mutualisée qui scale automatiquement pour répondre aux besoins de l'observabilité cloud-native moderne et qui est entièrement gérée afin d'assurer une fiabilité et une résilience permanentes.
- Sécurité : sur une architecture sans serveur, la sécurité est axée autour d'une nouvelle intégration continue qui guide les utilisateurs pour l'ingestion des logs de sécurité, la consultation des tableaux de bord, la mise en place de règles de détection et l'examen d'alertes. Un outil intégré de suivi de la progression est conçu pour optimiser des cas d'utilisation spécifiques, parmi lesquels l'analyse de la sécurité, le SIEM, la sécurité aux points de terminaison et la sécurité du cloud. Grâce à une navigation axée sur la sécurité, toutes les fonctions en lien avec la sécurité sont regroupées. Les capacités de Machine Learning d'Elastic Security sont activées dans chaque projet de sécurité. Par exemple, une fonctionnalité de détection des anomalies par ML est disponible et peut être utilisée dans les règles de détection automatisées ou pour traquer des menaces en fonction d'hypothèses. Quant aux données ingérées, elles peuvent toutes faire l'objet d'une analyse ou d'une exploration organisée ou ad hoc.
Envie de tester ?
Venant compléter nos options de déploiement existantes, l'architecture et les produits sans serveur établissent un socle pour permettre aux charges de travail complexes des données et du calcul de proposer des recherches ultra-rapides, même sur de gros volumes de données historiques. Le tout, en profitant de toutes les innovations d'Elasticsearch pour la recherche, l'observabilité et la sécurité de façon simplissime. Ce socle concrétise notre vision de la simplicité, des performances et de la scalabilité en proposant :
- Des expériences produit spécialement conçues : travaillez plus rapidement avec des produits optimisés spécialement conçus pour la recherche, la sécurité et l'observabilité.
- Des opérations sans prise de tête : finies, les responsabilités opérationnelles. Vous n'avez plus besoin de gérer l'infrastructure back-end, de planifier les capacités, d'effectuer les mises à niveau ou encore de scaler les données.
- Une architecture découplée scalable : scalez les charges de travail de manière automatique, fiable et indépendante. Répondez en temps réel à l'évolution de la demande et limitez la latence, pour intervenir le plus rapidement possible.
- Un développement et une livraison rapides : soyez opérationnel immédiatement et scalez facilement avec un stockage d'objets rapide et économique qui vous permet de conserver vos données à long terme et de les interroger quand vous le souhaitez. Gérez les performances et les coûts grâce à des contrôles simplissimes.
Cette approche sans serveur vous tente ? Rejoignez-nous et testez-la avant tout le monde. Cliquez ici pour la découvrir dès maintenant.
La publication et la date de publication de toute fonctionnalité ou fonction décrite dans le présent article restent à la seule discrétion d'Elastic. Toute fonctionnalité ou fonction qui n'est actuellement pas disponible peut ne pas être livrée à temps ou ne pas être livrée du tout.
Partager
- Share on Twitter
Partager sur Twitter
- Share on LinkedIn
Partager sur LinkedIn
- Share on Facebook
Partager sur Facebook
- Share by Email
Partage par e-mail
- Print this page
Imprimer