Dimensionamiento de arquitecturas calientes-tibias para logging y métricas en Elasticsearch Service en Elastic Cloud
¿Quieres saber más sobre las diferencias entre Amazon Elasticsearch Service y nuestro Elasticsearch Service oficial? Visita nuestra página comparativa AWS Elasticsearch.
¡Vivimos tiempos emocionantes! Recientemente, Elasticsearch Service en Elastic Cloud agregó soporte para una amplia gama de opciones de hardware y plantillas de despliegue, lo que lo hace perfecto para el manejo eficiente de las cargas de trabajo relacionadas con logging y métricas. Toda esta nueva flexibilidad permite elegir entre muchas opciones. Seleccionar la arquitectura más apropiada para tu caso de uso y estimar el tamaño del cluster requerido puede ser complicado. No te preocupes. ¡Estamos aquí para ayudarte!
Este blog te enseñará la diferencia entre las diferentes arquitecturas que se usan comúnmente para los casos de uso de logging y métricas, y cuándo usarlas. También te brindará una guía para saber cómo dimensionar y administrar tu cluster para que puedas aprovecharlo al máximo.
¿Cuáles son las arquitecturas disponibles para mi cluster de logging?
En el cluster de Elasticsearch más simple, todos los nodos de datos tienen las mismas especificaciones y manejan todos los roles. A medida que este tipo de cluster crece, con frecuencia se agregan nodos para tareas específicas, por ejemplo, nodos maestros dedicados, de ingesta y de Machine Learning. Esto quita carga de los nodos de datos y les permite operar de forma más eficiente. En este tipo de cluster, todos los nodos de datos comparten las cargas de indexación y de búsqueda de forma pareja, y como tienen las mismas especificaciones, con frecuencia nos referimos a esto como arquitectura de cluster homogénea o uniforme.
Otra arquitectura muy popular, especialmente cuando se trabaja con datos basados en tiempo, como logs y métricas, es la que denominamos arquitectura caliente-tibia. Esto se basa en el principio de que los datos suelen ser inmutables y pueden indexarse en índices basados en tiempo. Entonces, cada índice contiene datos que cubren un período de tiempo específico, lo que posibilita administrar la retención y el ciclo de vida de los datos mediante la eliminación de índices completos. Esta arquitectura tiene dos tipos diferentes de nodos de datos con perfiles de hardware diferentes: nodos de datos “calientes” y “tibios”.
Los nodos de datos calientes contienen todos los índices más recientes y, por lo tanto, administran toda la carga de indexación en el cluster. Como los datos más recientes también son normalmente los buscados con más frecuencia, estos nodos tienden a estar muy ocupados. Indexar en Elasticsearch puede ser muy exigente en cuanto a CPU y E/S, y la carga de búsqueda extra implica que estos nodos deben ser poderosos y contar con un almacenamiento muy rápido. Esto generalmente se traduce en SSD locales de conexión directa.
Los nodos tibios, por otro lado, están optimizados para manejar almacenamiento a largo plazo de índices de solo lectura en el cluster de manera rentable. Generalmente están equipados con buenas cantidades de RAM y CPU, pero, en general, usan discos giratorios locales de conexión directa o SAN en lugar de SSD. Una vez que los índices del nodo caliente exceden el período de retención para esos nodos y ya no se indexan, deben ser reubicados en los nodos tibios.
Es importante resaltar que mover datos del nodo caliente al tibio no necesariamente significa que este será más lento en la búsqueda. Como estos nodos no manejan ninguna indexación de recursos intensivos, con frecuencia funcionan de forma eficiente en las búsquedas en comparación con datos más antiguos en latencias bajas, sin necesidad de usar un almacenamiento basado en SSD.
Como los nodos de datos en esta arquitectura son muy especializados y pueden soportar cargas altas, se recomienda usar nodos dedicados maestros, de ingesta, de Machine Learning y de coordinación.
¿Qué arquitectura debería seleccionar?
Para muchos casos de uso, cualquiera de estas arquitecturas funcionará bien, y no siempre está claro cuál seleccionar. Sin embargo, existen algunas condiciones y limitaciones que hacen que una arquitectura sea más adecuada que la otra.
El tipo de almacenamiento disponible para el cluster es un factor importante a considerar. Como la arquitectura caliente-tibia requiere de un almacenamiento muy rápido para los nodos calientes, no es adecuada si el cluster se limita al uso de almacenamiento más lento. En este caso, es mejor usar una arquitectura uniforme y distribuir la indexación y la búsqueda en tantos nodos como sea posible.
Los clusters uniformes con frecuencia tienen soporte de discos giratorios locales o SAN de conexión directa como almacenamiento en bloque, aunque las SSD sean cada día más comunes. Es posible que un almacenamiento más lento no pueda brindar soporte a tasas de indexación muy altas, especialmente cuando también hay búsquedas simultáneas, por lo que puede tomar mucho tiempo llenar el espacio en disco disponible. Por lo tanto, mantener grandes volúmenes de datos por nodo puede ser posible solo si cuentas con un período de retención razonablemente largo.
Si el caso de uso estipula un período de retención muy corto, por ejemplo, de menos de 10 días, los datos no quedarán en espera en el disco por mucho tiempo una vez que se indexen. Esto requiere de un almacenamiento eficiente. Una arquitectura caliente-tibia puede funcionar, pero un cluster uniforme con solo nodos de datos calientes puede ser mejor y más fácil de gestionar.
¿Cuánto almacenamiento necesito?
Uno de los puntos principales al dimensionar un cluster para un caso de uso de logging o métricas es la cantidad de almacenamiento. La proporción entre el volumen de datos sin procesar y la cantidad de espacio que ocupará en el disco una vez que esté indexado y replicado en Elasticsearch dependerá en gran medida del tipo de datos y cómo se indexen. El diagrama a continuación muestra las diferentes etapas por las que pasan los datos durante la indexación.
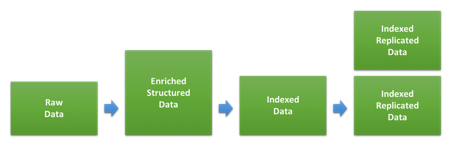
El primer paso involucra transformar los datos sin procesar en los documentos JSON que indexaremos en Elasticsearch. La medida en que esto cambie el tamaño de los datos dependerá del formato original y la estructura agregada, así como también de la cantidad de datos agregados en varios tipos de enriquecimiento. Esto puede diferir de manera significativa para diferentes tipos de datos. Si tus logs ya están en formato JSON y no agregas datos adicionales, es posible que el tamaño no cambie. Si, por el contrario, tienes logs de acceso web basados en texto, la estructura agregada y la información sobre el agente de usuario y la ubicación pueden ser considerablemente mayores.
Una vez que indexemos estos datos en Elasticsearch, la configuración y el mapeo de indexación usados determinarán cuánto espacio ocuparán en el disco. Los mapeos dinámicos predeterminados aplicados por Elasticsearch suelen estar diseñados para favorecer la flexibilidad en lugar del tamaño de almacenamiento optimizado en el disco, por lo que puedes ahorrar espacio en disco optimizando los mapeos que usas mediante plantillas de indexación personalizadas. Puedes encontrar más información sobre esto en la documentación de ajustes.
Para estimar cuánto espacio en disco ocupará un tipo específico de datos en tu cluster, indexa una cantidad de datos lo suficientemente grande como para asegurarte de que alcances el tamaño de shard que es probable que uses en producción. Las pruebas con volúmenes de datos muy pequeños son un error bastante común que puede dar resultados imprecisos.
¿Cómo logro un balance entre ingesta y búsqueda?
La primera evaluación comparativa que los usuarios realizan cuando dimensionan un cluster con frecuencia es determinar el rendimiento máximo de indexación del cluster. Después de todo, es una evaluación fácil de programar y ejecutar, y los resultados también pueden usarse para determinar cuánto espacio ocuparán los datos en el disco.
Una vez que se han ajustado los procesos de cluster e ingesta y que hemos identificado la tasa de indexación máxima que podemos sostener, podemos calcular cuánto tiempo llevará completar el disco de nodos de datos si continuamos indexando con un rendimiento máximo. Esto nos indicará cuál sería el período de retención mínimo para el tipo de nodo suponiendo que queremos maximizar el uso del espacio en disco disponible.
Puede parecer tentador usar esto directamente para determinar el tamaño necesario, pero eso no dejaría espacio suficiente para la búsqueda, ya que todos los recursos del sistema se estarían usando para la indexación. Después de todo, la mayoría de los usuarios almacenan datos en Elasticsearch para poder realizar una búsqueda en algún momento y esperan un buen desempeño al hacerlo.
¿Cuánto espacio libre necesitamos dejar para la búsqueda? Es una pregunta difícil para brindar una respuesta genérica, ya que depende en gran medida de la cantidad y la naturaleza de las búsquedas que se esperan, así como también de las latencias que esperan los usuarios. La mejor forma de determinarlo es llevar a cabo una evaluación comparativa para simular los niveles realistas de búsqueda en diferentes volúmenes de datos y proporciones de indexación, según se describe en esta conversación Elastic{ON} sobre el dimensionamiento de cluster cuantitativo y en este seminario web sobre evaluación comparativa y dimensionamiento de cluster mediante Rally.
Una vez que hemos determinado el tamaño de rendimiento máximo de indexación que podemos sostener mientras realizamos búsquedas para usuarios con un desempeño aceptable, podemos ajustar el período de retención esperado para que coincida con esta tasa de indexación reducida. Si indexamos a un ritmo más lento, puede demorar más completar los discos.
Este ajuste puede brindarnos la habilidad de manipular pequeños picos en el tráfico, pero generalmente asume una tasa de indexación bastante constante con el paso del tiempo. Si esperamos que nuestros niveles de tráfico experimenten picos y fluctúen durante el día, necesitaremos asumir que la tasa de indexación ajustada corresponde al nivel pico e incluso reducir aún más la tasa de indexación promedio que asumimos que cada nodo puede manejar. En caso de que las fluctuaciones sean predecibles y duren por períodos de tiempo extendidos, por ejemplo, durante las horas de trabajo, otra opción puede ser aumentar el tamaño de la zona caliente solo durante ese período.
¿Cómo uso todo este almacenamiento?
En arquitecturas calientes-tibias, se espera que los nodos tibios puedan contener grandes cantidades de datos. Esto también aplica a los nodos de datos en una arquitectura uniforme con un período de retención largo.
Cuánta data exactamente puedes guardar en un nodo suele depender de tu capacidad para administrar el uso de heap, que suele tornarse en el factor limitante principal para nodos densos. Cómo existen varias áreas que contribuyen al uso de heap en un cluster de Elasticsearch, por ejemplo, la indexación, la búsqueda, el caché, el estado del cluster, los datos de campo y la sobrecarga de shard, los resultados serán diferentes en los distintos casos de uso. La mejor forma de determinar con precisión cuáles son los límites para tu caso de uso es ejecutar una evaluación con base en datos realistas y patrones de búsqueda. Sin embargo, existen muchas mejores prácticas genéricas alrededor de los casos de uso de logging y métricas que te ayudarán a sacar el máximo provecho posible de tus nodos de datos.
Asegúrate de que los mapeos estén optimizados
Como se describió anteriormente, los mapeos usados para tus datos pueden afectar qué tan compacto es en el disco. También puede afectar la cantidad de datos de campo que usarás e impactar en el uso de heap. Si estás usando Filebeat module o módulos Logstash para analizar e ingestar tus datos, estos incluyen mapeos optimizados preestablecidos, y no necesitarás preocuparte tanto por este punto. Sin embargo, si estás analizando logs de clientes y confías ampliamente en la habilidad de Elasticsearch para mapear dinámicamente nuevos campos, continúa leyendo.
Cuando Elasticsearch mapea dinámicamente un texto, el comportamiento preestablecido es usar campos múltiples para mapear los datos tanto como texto, que puede usarse para una búsqueda de texto libre sin importar el caso, y como palabra clave, que se usa cuando se agregan datos en Kibana. Esta es una predeterminación importante, ya que brinda una flexibilidad óptima, pero la desventaja es que aumenta el tamaño de los índices en el disco y la cantidad de datos de campo usados. Por lo tanto, se recomienda optimizar los mapeos siempre que sea posible. Esto puede causar una diferencia significativa a medida que crece el volumen de datos.
Mantén los shards del mayor tamaño posible
Cada índice en Elasticsearch contiene uno o más shards, y cada uno incluye una sobrecarga que usa un poco del espacio de heap. Como se describe en este blog sobre sharding, los shards más pequeños tienen más sobrecarga por volumen de dato en comparación con los shards más grandes. Para minimizar el uso de heap en los nodos que van a mantener grandes cantidades de datos, es importante intentar mantener los shards del mayor tamaño posible. Una buena regla es mantener el tamaño promedio de shard para la retención a largo plazo entre 20 GB y 50 GB.
Como cada búsqueda o agregación se ejecuta con un único hilo por shard, la latencia de búsqueda mínima dependerá, en general, del tamaño del shard. Esto depende de los datos y las búsquedas, por lo que puede variar incluso entre índices dentro del mismo caso de uso. Para un volumen y un tipo de datos específicos, sin embargo, no es preciso afirmar que una cantidad mayor de shards menores se desempeñará mejor que un único shard mayor.
Es importante evaluar el efecto del tamaño de los shards para alcanzar un nivel óptimo con respecto al uso de búsqueda y la sobrecarga mínima.
Ajuste para volumen de almacenamiento
Comprimir de manera eficiente la fuente JSON puede tener un impacto significativo en la cantidad de espacio ocupado por tus datos en el disco. Por defecto, Elasticsearch comprime estos datos usando un algoritmo de compresión configurado para crear un balance entre almacenamiento y velocidad de indexación, pero también ofrece una alternativa más agresiva: el códec best_compression.
Esto se puede especificar para todos los nuevos índices, pero incluye una penalidad de desempeño de entre el 5 y el 10 % durante la indexación. La ganancia de espacio en disco puede ser significativa, por lo que puede valer la pena.
Si has seguido el consejo de la sección anterior y estás forzando la fusión de los índices, también cuentas con la opción de aplicar la compresión mejorada justo antes de la operación de fusión forzada.
Evita cargas innecesarias
La última contribución para el uso de heap que vamos a discutir aquí es el manejo de las solicitudes. Todas las solicitudes que se envían a Elasticsearch se coordinan en el nodo al que llegan. Después, la tarea de divide y se distribuye hacia donde residen los datos. Esto aplica tanto a la indexación como a la búsqueda.
El análisis y la coordinación de la solicitud, y la respuesta pueden resultar en un uso de heap significativo. Asegúrese de que los nodos que trabajan como nodos de coordinación o de indexación cuentan con suficiente espacio libre de heap para poder manejar esta situación.
En el caso de los nodos ajustados para un almacenamiento de datos a largo plazo, a menudo tiene sentido dejarlos trabajar como nodos de datos dedicados y minimizar cualquier trabajo adicional que necesiten realizar. Direccionar las consultas a los nodos calientes o a nodos solo de coordinación dedicados puede ayudar a lograrlo.
¿Cómo aplico esto a mi despliegue de Elasticsearch Service?
Elasticsearch Service está actualmente disponible en AWS y GCP, y aunque están disponibles las mismas configuraciones de instancia y las mismas plantillas de despliegue en ambas plataformas, la especificación es un poco diferente. En esta sección, veremos las diferentes configuraciones de instancia y cómo se adaptan a las arquitecturas que discutimos previamente. También analizaremos cómo podemos estimar el tamaño del cluster necesario para brindar soporte a un caso de uso de ejemplo.
Configuraciones de instancia disponibles
Tradicionalmente, Elasticsearch Service ha ofrecido nodos de Elasticsearch con el respaldo del almacenamiento SSD rápido. Se los denomina nodos highio y tienen un desempeño de I/O excelente. Esto los convierte en una opción adecuada como nodos calientes en una arquitectura caliente-tibia, pero también se pueden usar como nodos de datos en una arquitectura uniforme. Esto se recomienda con frecuencia si tienes un período de retención corto que requiere un almacenamiento eficiente.
En AWS y GCP, los nodos highio tienen una proporción de disco a RAM de 30:1, por lo que por cada 1 gb de RAM, hay 30 gb de almacenamiento disponible. Los tamaños de nodo disponibles en AWS son 1 gb, 2 gb, 4 gb, 8 gb, 15 gb, 29 gb y 58 gb, mientras que en GCP, los nodos están disponibles en tamaños de 1 gb, 2 gb, 4 gb, 8 gb, 16 gb, 32 gb y 64 gb.
Otro tipo de nodo que se ha introducido recientemente en Elastic Cloud es el nodo highstorage de almacenamiento optimizado. Estos cuentan con grandes volúmenes de almacenamiento más lento y tienen una proporción de disco a RAM de 100:1. Un nodo highstorage de 64 gb en GCP incluye más de 6.2 tb de almacenamiento, mientras que un nodo de 58 gb en AWS soporta 5.6 tb. Estos tipos de nodos están disponibles en los mismos tamaños de RAM que los nodos highio en la respectiva plataforma.
Estos nodos suelen usarse como nodos tibios en una arquitectura caliente-tibia. Las evaluaciones en nodos highstorage han demostrado que este tipo de nodo en GCP tiene una ventaja de rendimiento significativa en comparación con AWS, incluso después de tener en cuenta la diferencia de tamaño.
Uso de 2 o 3 zonas de disponibilidad
En la mayoría de las regiones, cuentas con la opción de elegir ejecutar en 2 o 3 zonas de disponibilidad, y puedes elegir diferentes cantidades de zonas por zona en el cluster. Cuando eliges quedarte con una cantidad fija de zonas de disponibilidad, los tamaños de cluster disponibles aumentan cerca del doble de tamaño, por lo menos para los clusters más pequeños. Si estás dispuesto a usar entre 2 o 3 zonas de disponibilidad, puedes dimensionar en pasos más pequeños, ya que pasar de 2 a 3 zonas de disponibilidad con el mismo tamaño de nodo aumenta la capacidad solo en un 50 %.
Ejemplo de dimensionado: Arquitectura caliente-tibia
En este ejemplo, veremos un cluster caliente-tibio que puede manejar la ingesta de 100 gb de logs de acceso web sin procesar por día con un período de retención de 30 días. Compararemos el despliegue de esto con Elastic Cloud en AWS y GCP.
Ten en cuenta que los datos usados aquí son solo un ejemplo, y es muy probable que tu caso de uso sea diferente.
Paso 1: Estimación del volumen de datos total
Para este ejemplo, asumimos que los datos se ingestan usando Filebeat modules y que, por lo tanto, los mapeos están optimizados. Nos quedamos con un único tipo de datos para simplificar este ejemplo. Durante las evaluaciones de indexación, hemos visto que la proporción entre el tamaño de los datos sin procesar y el tamaño indexado en el disco es de alrededor de 1.1, por lo que se estima que 100 gb de datos sin procesar resultan en 110 gb de datos indexados en el disco. Una vez que se agrega la réplica, eso se duplica a 220 gb.
Durante 30 días, eso da un total indexado y un volumen de datos replicados de 6600 gb que el cluster en conjunto deberá manejar.
Este ejemplo asume que se usa 1 shard de réplica en todas las zonas, lo que se considera como mejor práctica para desempeño y disponibilidad.
Paso 2: Tamaño de los nodos calientes
Hemos realizado algunas evaluaciones de indexación máxima de nodos calientes con este conjunto de datos, y hemos notado que se necesitan alrededor de 3.5 días para que los discos en nodos highio se completen en AWS y GCP.
Para dejar espacio libre para la búsqueda y para algunos picos en el tráfico, asumiremos que solo podemos sostener la indexación a no más del 50 % del nivel máximo. Si queremos usar el almacenamiento disponible en estos nodos en su totalidad, necesitaremos indexar en el nodo durante un período de tiempo mayor, y, por lo tanto, necesitaremos ajustar el período de retención en estos nodos de manera acorde.
Elasticsearch también necesita algo de espacio en disco libre para trabajar con eficiencia, por lo que, para no excederse de las marcas de agua del disco asumiremos que se necesita un espacio adicional de protección de un 15 %. Esto se muestra en la columna Espacio en disco necesario que se muestra a continuación. Según esta información, podemos determinar la cantidad total de RAM necesaria para cada proveedor.
| Plataforma | Proporción disco:RAM | Días para completar | Retención efectiva (días) | Volumen de datos contenido (gb) | Espacio en disco necesario (gb) | RAM requerida (gb) | Especificación de zona |
| AWS | 30:1 | 3.5 | 7 | 1440 | 1656 | 56 | 29 GB, 2AZ |
| GCP | 30:1 | 3.5 | 7 | 1440 | 1656 | 56 | 32 GB, 2AZ |
Paso 3: Tamaño de nodos tibios
Los datos que exceden el período de retención en los nodos calientes serán reubicados en los nodos tibios. Podemos estimar el tamaño necesario calculando la cantidad de datos que estos nodos necesitan contener, teniendo en cuenta el espacio libre de las marcas de agua.
| Plataforma | Proporción disco:RAM | Retención efectiva (días) | Volumen de datos contenido (gb) | Espacio en disco necesario (gb) | RAM requerida (gb) | Especificación de zona |
| AWS | 100:1 | 23 | 5060 | 5819 | 58 | 29 GB, 2AZ |
| GCP | 100:1 | 23 | 5060 | 5819 | 58 | 32 GB, 2AZ |
Paso 4: Agregar tipos de nodo adicionales
Además de los nodos de datos, también solemos necesitar 3 nodos maestros dedicados para que el cluster sea más resistente y esté altamente disponible. Como estos no tienen tráfico, pueden ser bastante pequeños. Inicialmente, destinar nodos de 1 gb a 2 gb en 3 zonas de disponibilidad es un buen tamaño para comenzar. Después, escalar esos nodos hasta 16 gb en 3 zonas de disponibilidad a medida que el tamaño del cluster administrado crezca.
¿Qué sigue?
Si aún no lo has hecho, activa tu prueba gratuita de Elasticsearch Service durante 14 días y pruébalo. Comprueba qué fácil es configurarlo y administrarlo. Si tienes alguna pregunta o quieres algún consejo adicional sobre cómo dimensionar Elasticsearch Service en Elastic Cloud, comunícate con nosotros directamente o contáctanos a través de nuestro foro de debate público.