KI-gestützte Suche für Ihre Anwendungen
Die Elasticsearch Relevance Engine™ (ESRE) wurde speziell für KI-gestützte Suchanwendungen entwickelt. Mit ESRE können Sie semantische Suchfunktionen mit überragender Relevanz sofort (ohne fachspezifische Anpassung) einsetzen, eigene LLMs (Large Language Models) integrieren, hybride Sucherlebnisse implementieren und externe oder eigene Transformationsmodelle nutzen.

Sehen Sie sich an, wie einfach sich die Elasticsearch Relevance Engine einrichten lässt.
„Quick Start“-Video ansehenNutzen Sie ESRE, um komplexe RAG-basierte Anwendungen zu erstellen.
Für Schulung registrierenNutzen Sie beim Einsatz von GKI-Modellen private, interne Daten als Kontext, um Nutzer:innen aktuelle und zuverlässige Antworten auf ihre Fragen zu geben.
Video ansehenKI für alle Entwickler:innen
Bessere Suche mit KI
Versehen Sie Ihre Anwendung mithilfe von ESRE mit erweiterten KI-Relevanzfunktionen – ganz ohne Vorkenntnisse. ESRE bietet sowohl für Anfänger als auch für alte KI-Hasen eine Vielzahl nützlicher Funktionen. Mit den Funktionen in ESRE können Sie ganz nach Gusto und mit großer Flexibilität Suchanwendungen bereitstellen, die Machine Learning und generative KI nutzen.



Elasticsearch Relevance Engine
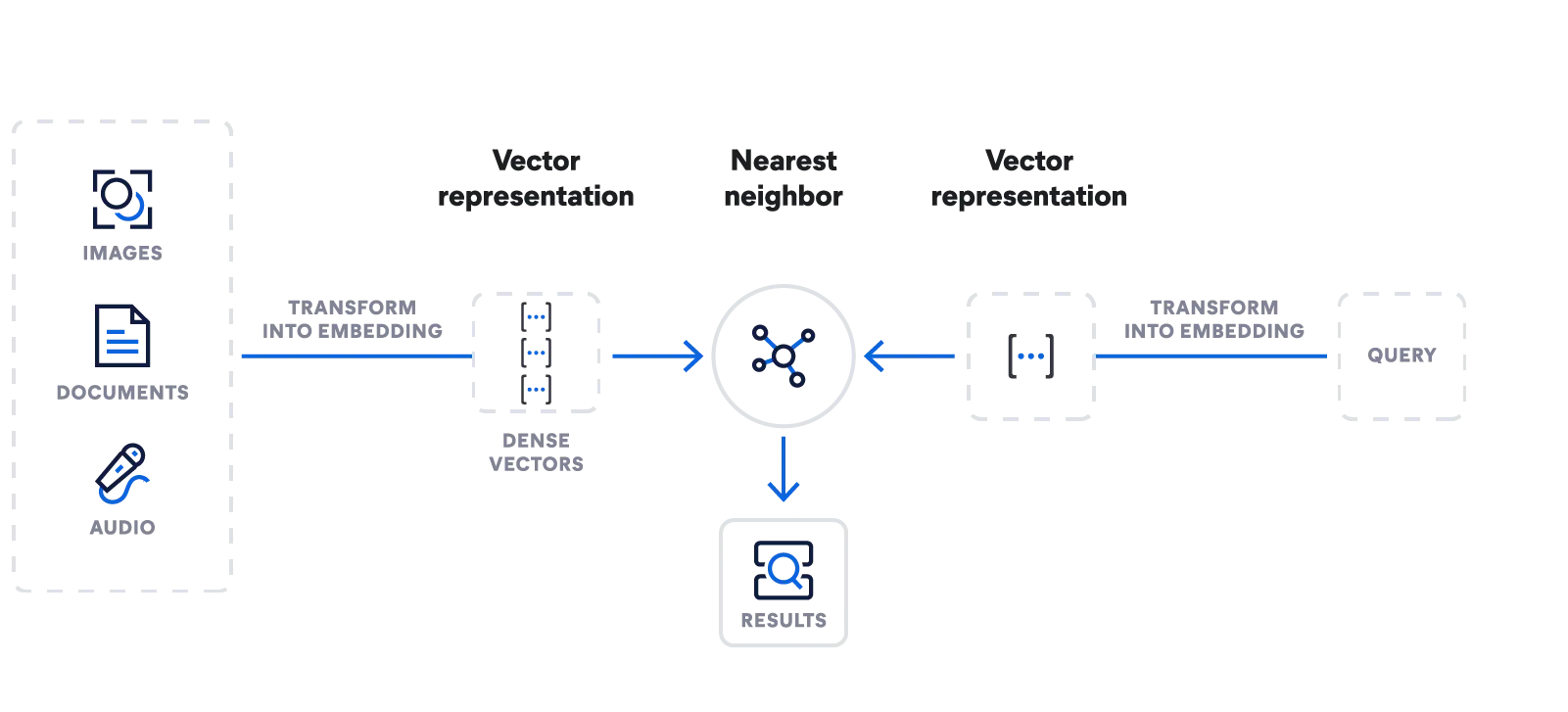
Elasticsearch – All-in-one-Kraftwerk für die Vektorsuche
Erstellen Sie Einbettungen. Speichern, durchsuchen und verwalten Sie Vektoren. Erstellen Sie semantische Suchanwendungen mit dem Learned Sparse Encoder Machine-Learning-Modell von Elastic. Ingestieren Sie Datentypen jeder Art. Sorgen Sie für die Unterstützung dynamischer LLMs.
Codebeispiele
Vektorsuche erstellen
Mit nur einer einzigen API können Sie ein Einbettungsmodell importieren, Einbettungen generieren und umfangreiche Suchabfragen mit der Suche nach dem geschätzten nächsten Nachbarn schreiben.
docker run -it --rm elastic/eland \
eland_import_hub_model \
--cloud-id $CLOUD_ID \
-u <username> -p <password> \
--hub-model-id sentence-transformers/msmarco-MiniLM-L-12-v3 \
--task-type text_embedding \
--startFrequently asked questions
What is Elasticsearch Relevance Engine?
What is Elasticsearch Relevance Engine?
Elasticsearch Relevance Engine is a set of features that help developers build AI search applications and includes:
- Industry leading advanced relevance ranking features, including traditional keyword search with BM25, a foundation of relevant, hybrid search for all domains.
- Full vector database capabilities – including the ability to create embeddings, in addition to storage and retrieval of vectors.
- Elastic Learned Sparse Encoder – our new machine learning model for semantic search across a range of domains Hybrid ranking (RRF) for pairing vector and textual search capabilities for optimal search relevance across a variety of domains.
- Support to integrate 3rd-party transformer models such as OpenAI GPT-3 and 4 via APIs
- A full suite of data ingestion tools such as database connectors, 3rd-party data integrations, web crawler, and APIs to create custom connectors
- Developer tools to build search applications across all types of data: text, images, time-series, geo, multimedia, and more.
What can I build with Elasticsearch Relevance Engine?
What can I build with Elasticsearch Relevance Engine?
Elasticsearch is a leading search technology for websites (like ecommerce product and discovery) and internal information (such as customer success knowledge bases and enterprise search). With ESRE, we're providing a toolkit to build AI powered search experiences. Enable users to express their queries in natural language, in the form of a question or a description of the kind of information they seek. Combine this natural language capability with Generative AI to further enhance these models’ abilities with context from your own, private or proprietary data.
Are Elasticsearch and Elasticsearch Relevance Engine the same thing?
Are Elasticsearch and Elasticsearch Relevance Engine the same thing?
Yes, capabilities included with Elasticsearch Relevance Engine are designed and integrated at the _search api within Elasticsearch. Developers can use the Elastic API or familiar tools, such as Kibana, to interact with capabilities that make up Elasticsearch Relevance Engine together with Elasticsearch for a seamless experience..
What is Elastic Learned Sparse Encoder?
What is Elastic Learned Sparse Encoder?
Elastic Learned Sparse Encoder is a model built by Elastic for high relevance semantic search across a variety of domains. Currently, an English-only machine learning model, it captures the relationships between meanings and words for information retrieval. Interested in benchmark tests with our new retrieval model? Read this blog to learn more.
What is a transformer, and is Elastic Learned Sparse Encoder a transformer model?
What is a transformer, and is Elastic Learned Sparse Encoder a transformer model?
A transformer is a deep neural network architecture which serves as the basis for LLMs. Transformers consist of various components and can be composed of encoders, decoders and many “deep” neural network layers with many millions (or even billions) of parameters. They are typically trained on very large corpora of text like data on the Internet, and can be fine-tuned to perform a variety of NLP tasks. Our new retrieval model uses a transformer architecture but consists only of an encoder designed specifically for semantic search across a wide variety of domains.
How do I get started with Elasticsearch Relevance Engine? Do I need to purchase Elasticsearch Relevance Engine separately?
How do I get started with Elasticsearch Relevance Engine? Do I need to purchase Elasticsearch Relevance Engine separately?
All of Elasticsearch Relevance Engine’s capabilities come with Elastic Enterprise Search Platinum and Enterprise plans, as part of the 8.8 release. You can easily get started with embeddings and vector search, and try out the retrieval model model. Check out a demo of Elastic Learned Sparse Encoder's capabilities. If you have an Elasticsearch license, Elasticsearch Relevance Engine is included as part of your purchase.