Serverless – wo ohne mehr ist

 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
Wir sind immer wieder erstaunt, welche Wege Nutzer:innen mit Elasticsearch® finden, um Datenprobleme zu lösen. Die Fakten sprechen für sich: über 4 Milliarden Downloads, 70.000 Commits, 1.800 Beitragende sowie Community-Feedback aus der ganzen Welt. Die große Rolle, die Elastic® in den verschiedensten Anwendungsfällen spielt, hat uns veranlasst, Komplexitäten abzubauen: Wir haben es einfacher gemacht, die Suche zu nutzen und die Vorteile, die unsere Lösungen bieten, voll auszuschöpfen. Deshalb freuen wir uns, Ihnen unsere neue Serverless-Architektur vorstellen zu können, die die Möglichkeiten von Elasticsearch erweitert. Diese neue Architektur strafft die operativen Zuständigkeiten, erweitert die bekannte High-Speed-Performance von Elasticsearch auf skalierbare Objektspeicher und rationalisiert Workflows mit speziell entwickelten Produkten für Search, Observability und Security. Dies macht es möglich, Elastic auf ganze neue Art und Weise mit den vorhandenen On-Premises- und Elastic Cloud-Deployments zu nutzen.
Sie importieren Ihre Daten – den Rest erledigt Serverless
Eine Aufgabe für die nächste Zukunft wird es sein, die User Experience zu vereinfachen, ohne dass darunter die Performance leidet. Während viele Elastic-Nutzer:innen die volle Kontrolle über die Bereitstellung und Skalierung behalten möchten, gibt es doch auch andere, die sich weniger Komplexität wünschen. SOC-Analysts sehen ihre Aufgabe nicht in erster Linie darin, Shards für eine bessere Bedrohungserkennung zu skalieren, sondern für den Schutz ihrer Organisationen zu sorgen. Entwickler:innen wollen sich nicht mit der Optimierung der Infrastruktur beschäftigen, um die Suche zu beschleunigen, sondern Suchanwendungen entwickeln. Und das oberste Ziel von SREs ist es nicht, an Konfigurationen herumzuschrauben, um die Ausfallzeiten zu minimieren, sondern für eine maximale Verfügbarkeit zu sorgen. Auch wenn wir Spaß daran haben, Cluster zu verwalten, muss das noch lange nicht für Sie gelten! Die Serverless-Architektur von Elastic nimmt Ihnen die operative Verantwortung ab, d. h., Sie müssen sich nicht mehr um das Verwalten von Clustern, das Konfigurieren von Shards, das Skalieren und das Einrichten von ILM kümmern. Sie müssen lediglich Ihre Daten und Suchanfragen liefern – das Skalieren und Verwalten übernimmt die Plattform.
Sind Sie es leid, immer wieder zu hören, dass Sie keine schnellere Skalierbarkeit und längeren Datenaufbewahrungsfristen bekommen können, weil das zu teuer ist und die Komplexität erhöhen würde? Damit ist jetzt Schluss! Bei vielen Workloads sind Skalierbarkeit und Geschwindigkeit gleichermaßen wichtig – sei es bei der Untersuchung von Bedrohungen wie SolarWinds mit ihrer langen Verweildauer, bei der Suche nach der Ursache des Ausfalls Hunderter Dienste oder bei der Verwendung der Vektorsuche, um Workloads mit generativer KI durch Retrieval-Augmented Generation (RAG) zu unterstützen.
Deshalb basiert unsere Serverless-Architektur auf einem neu konzipierten und neu gestalteten Elasticsearch, das die Rechenleistung vollständig vom Speicher entkoppelt und auf Objektspeicher setzt. Cloud-Objektspeicher bieten kosteneffiziente Skalierbarkeit, bringen aber Latenzprobleme mit sich, die neue Herangehensweisen zur Aufrechterhaltung der Geschwindigkeit erfordern. Aber dank unserer langjährigen Erfahrungen bei der Optimierung von Elasticsearch- und Lucene-Indexdatenstrukturen für ein effizientes Caching, kombiniert mit einer verbesserten Suchanfragenparallelisierung, konnten wir diese Latenzprobleme lösen. Integrierte Steuerungsmöglichkeiten für die optimale Balance zwischen Geschwindigkeit und Kosten sorgen dafür, dass Sie sowohl von Geschwindigkeit als auch von Skalierbarkeit profitieren.
Eine neue Elastic-Architektur für morgen
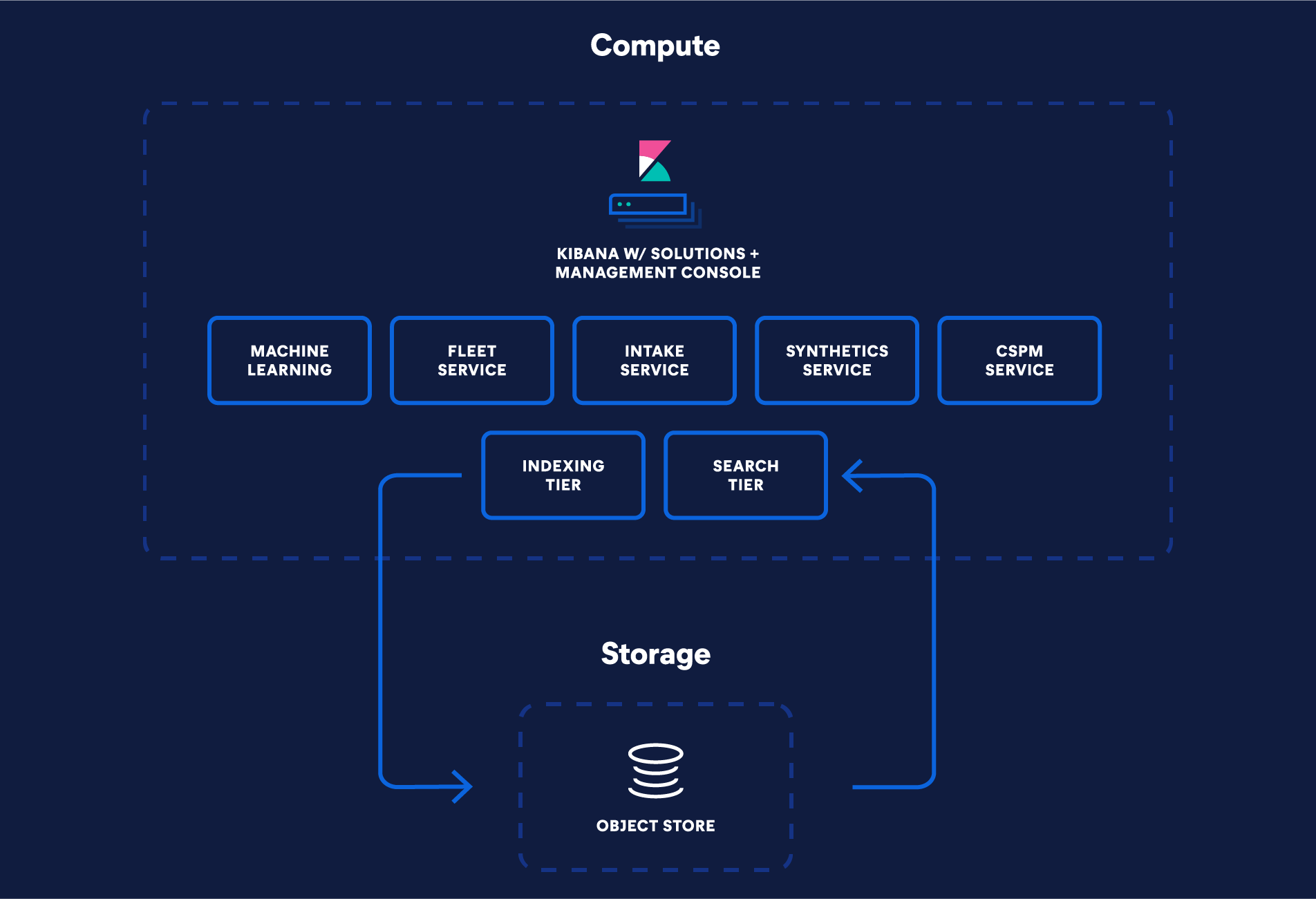
Die neue Serverless-Architektur von Elastic ist das Ergebnis einer größeren Überarbeitung von Elasticsearch. Ziel dieser Überarbeitung war es, die Vorteile der neuesten cloudnativen Dienste nutzbar zu machen, die Nutzerfreundlichkeit zu optimieren und die Verwaltung zu vereinfachen. Die Serverless-Architektur kombiniert die Speicherkapazität eines Data Lake mit der Elasticsearch-eigenen Suche-Performance und operativer Einfachheit ohne Aufwand bei der Cluster-Verwaltung und Skalierung. Die Architektur stützt sich auf vier Grundprinzipien:
- Entkopplung von Rechenleistung und Speicherung
- separate Tiers für Indexierung und Suche
- Objektspeicher als kostengünstige SOR-Lösung
- geringe Latenz bei der Suche
Vollständige Entkopplung von Rechenleistung und Speicherung
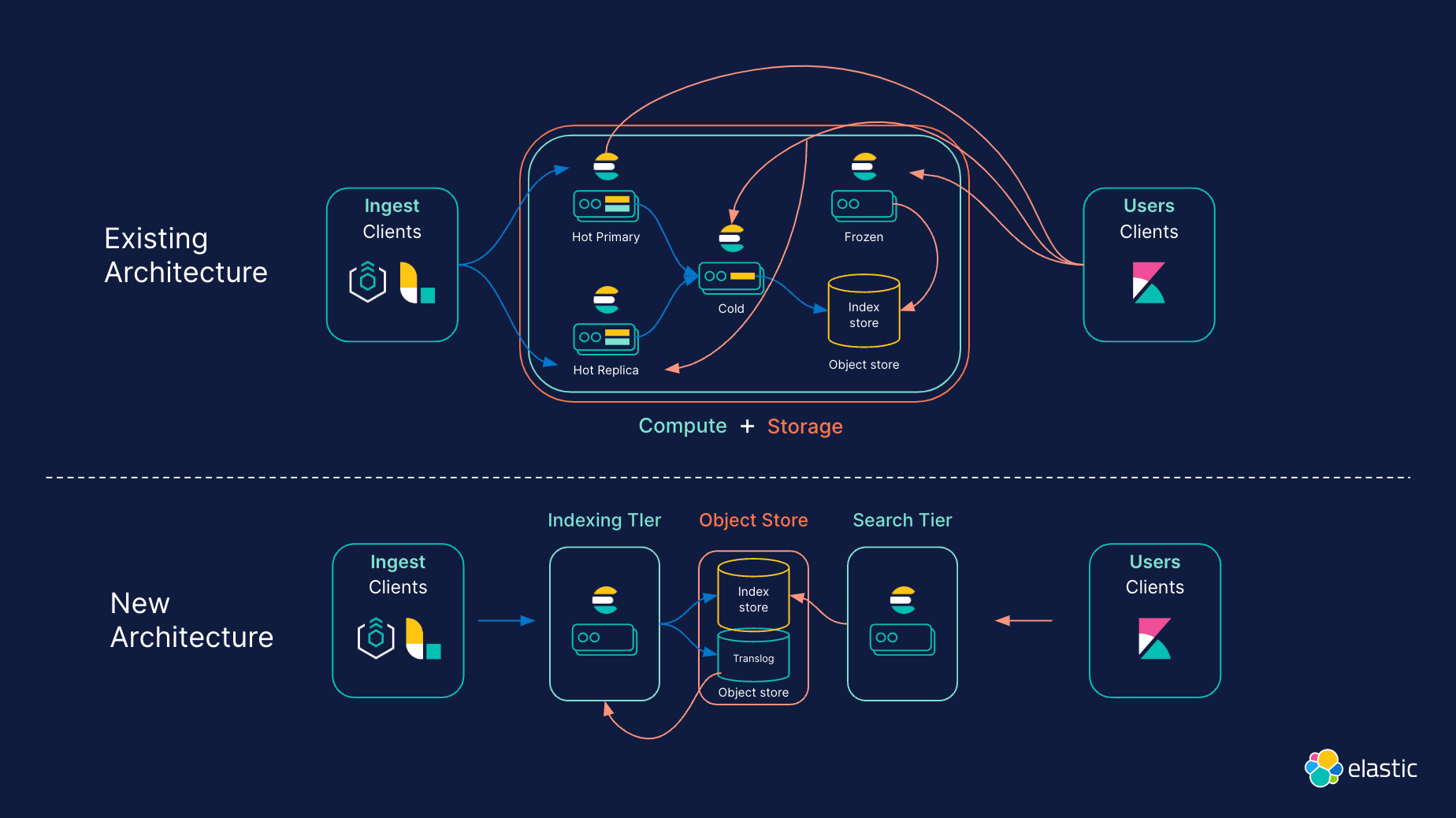
Zur Optimierung der Cluster-Topologie sind Rechenleistung (Compute) und Speicherung (Storage) jetzt vollständig entkoppelt. Um Daten- und Hardwareanforderungen besser in Einklang zu bringen, gibt es bei Elasticsearch verschiedene Daten-Tiers („heiß“, „warm“, „kalt“ und „eingefroren“). In der Serverless-Architektur sind Daten-Tiers durch die Entkopplung von Rechenleistung und Speicherung überflüssig, was den Betrieb vereinfacht. Bei Serverless wird beispielsweise die Tier für „heiße“ Daten mit der Tier für „eingefrorene“ Daten zusammengeführt: In den Indizes der Tier für „gefrorene“ Daten können große Mengen von weniger häufig abgefragten Daten gespeichert werden, aber ähnlich wie bei der Tier für „heiße“ Daten können diese Daten jederzeit aktualisiert und schnell abgefragt werden.
Darüber hinaus gibt es einfache Steuermöglichkeiten, mit denen sich das richtige Verhältnis zwischen Search-Performance und Speicherkosteneffizienz einstellen lässt. Dadurch können Workloads unabhängig voneinander schnell und zuverlässig skaliert werden, ohne dass dies auf Kosten der Performance geht.
Separate Tiers für Indexierung und Suche
Anstatt sich bei der Verwaltung von Workloads auf primäre und Replikat-Instanzen zu verlassen, unterstützt die Serverless-Architektur von Elastic eigenständige Indexierungs- und Suche-Tiers. Durch diese Separierung können Workloads unabhängig voneinander skaliert werden, wobei für jeden Anwendungsfall Hardware ausgewählt und optimiert werden kann.
Darüber hinaus wird mit diesem Ansatz das Problem der gegenseitigen Beeinflussung von Suche- und Indexierungs-Workloads wirksam gelöst. Dies erleichtert die Optimierung der Performance und der Ausgaben, gleich bei welchem Suche-Anwendungsfall und bei welcher Workload. Diese Eigenschaft ist wichtig für Nutzer:innen, bei denen viele Logdaten anfallen bzw. die sich um die Security kümmern und die verhindern möchten, dass die Indexierung durch umfangreiche Suchvorgänge gestört wird, sowie für Suchende, die die Indexierung mit zusätzlichen Funktionen anreichern, um die Relevanz und Geschwindigkeit der Suche zu verbessern, ohne dass darunter die Performance leidet.
Nutzung kostengünstiger Objektspeicher
Für bessere Skalierbarkeit und geringere Speicherkosten setzt die Serverless-Architektur auf kostengünstige Objektspeicher. Durch die Nutzung von Objektspeichern zur Sicherstellung der Persistenz muss Elasticsearch die Indexierungsvorgänge nicht mehr auf eine oder mehrere Replikate replizieren, um die Dauerhaftigkeit zu gewährleisten. Das Ergebnis sind geringere Indexierungskosten und weniger Datenduplizierung. Stattdessen werden die Segmente durch die Objektspeicher persistiert und repliziert, was in verschiedenen Bereichen für mehr Effizienz sorgt. So sinken beispielsweise die Speicherkosten für die Indexierungs-Tier, weil weniger Daten auf lokalen Datenträgern gespeichert werden. Die Serverless-Architektur indiziert direkt in den Objektspeicher, sodass nur ein Bruchteil der Daten als lokale Daten aufbewahrt wird. In den Fällen, wo nur Daten „angehängt“ werden, müssen nur bestimmte Metadaten für die Indexierung aufbewahrt werden, was den für die Indexierung erforderlichen lokalen Speicherplatz erheblich reduziert.
Suchanfragen mit geringer Latenz – auch bei großen Datenbeständen
Objektspeicher können zwar große Datenmengen speichern, sind aber nicht gerade für ihre Geschwindigkeit oder geringe Latenz bekannt. Wie schafft es Elastic da, trotz der Nutzung von Objektspeichern so eine gute Search-Performance zu liefern? Nun, wir haben mehrere neue Funktionen eingeführt, die für eine schnelle Performance sorgen. Die Suchanfragenparallelisierung auf Segmentebene reduziert die Latenz beim Abrufen von Daten aus dem Objektspeicher. Das ermöglicht es in den Fällen, in denen sich die Daten nicht im lokalen Cache befinden, eine größere Menge von Anforderungen schnell an Objektspeicher wie S3 zu senden. Auch das Caching ist „smarter“ geworden, denn Lucene-Indexformate lassen sich jetzt wiederverwenden und für jeden Datentyp kann das optimale Format genutzt werden. Dies sind nur einige der neuen Funktionen, die zu erheblichen Verbesserungen bei der Performance sowohl in der Objektspeicher- als auch in der Caching-Schicht führen.
Speziell für Serverless entwickelte Produkte für intelligenteres Arbeiten
Wir nutzen diese Gelegenheit auch dafür, eigene Produkte für Search, Observability und Security zu entwickeln, die speziell auf die Serverless-Architektur abgestimmt sind. Ziel dabei ist, die speziellen Anforderungen eines jeden Workflows durch eine optimierte User Experience zu optimieren. Dazu gehören ein schnelleres und kontinuierliches Onboarding, eine engere Integration von Funktionen und die Optimierung eigener Schnittstellen für die einzelnen Anwendungsfälle. Hier ein paar Highlights für jedes dieser Produkte:
- Search: Zentraler Punkt des Serverless-Ansatzes für die Suche ist, dass Entwickler:innen schnell und einfach eigene außergewöhnliche Sucherlebnisse entwickeln können. APIs stehen dabei an vorderster Stelle. Dazu kommen einfache Möglichkeiten, Daten zu ingestieren und in Elasticsearch zu importieren. Diese Pipelines wurden so vereinfacht, dass Aufgaben wie z. B. die Transformation schnell erledigt werden können. Neben der Bereitstellung einer ausführlichen Inline-Dokumentation wurden neue Sprach-Clients für Java, .NET, Python und andere Sprachen entwickelt, um die anfängliche Lernkurve und die für die Ausführung von Aufgaben erforderlichen Schritte zu reduzieren und es Entwickler:innen so durch ein optimiertes Nutzungserlebnis zu ermöglichen, schneller zum Ziel zu kommen.
- Observability: Observability in einem Serverless-Umfeld erlaubt es Site Reliability Engineers, sich auf das zu konzentrieren, was für sie wichtig ist: die Gewährleistung der Zuverlässigkeit ihrer Systeme und Anwendungen. Ein optimiertes Logdaten-Onboarding sorgt für ein einfaches Ingestieren von Daten, und Machine Learning-/AIOps-Funktionen helfen SREs, Verhaltensanomalien frühzeitig aufzudecken und den Ursachen schnell auf den Grund zu gehen – all dies ermöglicht eine deutlich kürzere „Time-to-Value“. Eine Kernkomponente ist der neue Managed Intake Service, der dafür sorgt, dass OpenTelemetry- und Elastic APM-Daten einfach akzeptiert, verarbeitet und indexiert werden können. Die Dienste basieren auf einer vollständig verwalteten Multi-Tenant-Architektur mit automatischer Skalierung, um den Anforderungen moderner cloudnativer Observability gerecht zu werden und die fortlaufende Zuverlässigkeit und Resilienz zu gewährleisten.
- Security: Security in Serverless-Umgebungen zeichnet sich durch ein neues kontinuierliches Onboarding aus, das Nutzer:innen durch die Schritte zum Ingestieren von Security-Logs, zum Aufrufen von Dashboards, zur Aktivierung von Erkennungsregeln und zur Untersuchung von Alerts führt. Ein integrierter „Progress-Tracker“ ist auf die Optimierung spezifischer Anwendungsfälle zugeschnitten, einschließlich Security Analytics/SIEM, Endpoint-Security und Cloud-Security. Die besonders auf Security ausgerichtete Navigation sorgt dafür, dass alle sicherheitsrelevanten Funktionen stets in greifbarer Nähe sind. In jedem Security-Projekt kommen Machine-Learning-Funktionen von Elastic Security zum Einsatz. So ist zum Beispiel eine ML-basierte Anomalieerkennung verfügbar, die in automatisierten Erkennungsregeln oder beim hypothesenbasierten Threat Hunting Verwendung findet. Für alle ingestierten Daten stehen für Untersuchungen und Erkundungen sowohl kuratierte als auch Ad-hoc-Funktionen zur Verfügung.
Interessiert? Geben Sie uns Bescheid!
Die Serverless-Architektur und ‑Produkte von Elastic bilden – neben unseren bestehenden Bereitstellungsoptionen – die Grundlage für eine Zukunft komplexer Daten- und Rechen-Workloads, die selbst bei großen historischen Datenbeständen ultraschnell Suchergebnisse liefern. Gleichzeitig bieten sie die einfachste Möglichkeit, alle Innovationen von Elasticsearch für Search, Observability und Security zu nutzen. Serverless löst die Versprechen hinsichtlich Einfachheit, Performance und Skalierbarkeit ein und bietet:
- Zielgerichtet entwickelte Nutzungserlebnisse: Schnelleres Arbeiten mit individuell entwickelten Produkten, die für Search, Security und Observability optimiert sind
- Reibungslosen Betrieb: Konzentration aufs Wesentliche ohne operative Verantwortung, also ohne die Notwendigkeit, Backend-Infrastruktur zu verwalten, Kapazitäten zu planen, Upgrades durchzuführen oder Daten zu skalieren
- Skalierbare entkoppelte Architektur: Workloads werden automatisch, zuverlässig und unabhängig voneinander skaliert. Auf Änderungen beim Bedarf kann in Echtzeit reagiert werden, die Latenz wird minimiert und Antworten kommen schnellstmöglich.
- Schnelle Entwicklung und Bereitstellung: Dank Datenspeicherung in schnellen, kostengünstigen Objektspeichern können Sie sofort loslegen und schnell wachsen, ohne langfristig die Fähigkeit zu verlieren, Ihre Datenbestände abzufragen. Steuerungsmöglichkeiten zur Verwaltung von Performance und Ausgaben vereinfachen das Skalieren.
Werden Sie Teil unserer Serverless-Vision und probieren Sie dieses Angebot vor allen anderen aus – beantragen Sie hier Ihren „Early-Access“-Zugang.
Die Entscheidung über die Veröffentlichung von Features oder Leistungsmerkmalen, die in diesem Blogpost beschrieben werden, oder über den Zeitpunkt ihrer Veröffentlichung liegt allein bei Elastic. Möglicherweise werden aktuell nicht verfügbare Features oder Funktionen nicht rechtzeitig oder gar nicht bereitgestellt.
Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken