



This Week in Elasticsearch and Apache Lucene - 2019-10-28
Elasticsearch Highlights
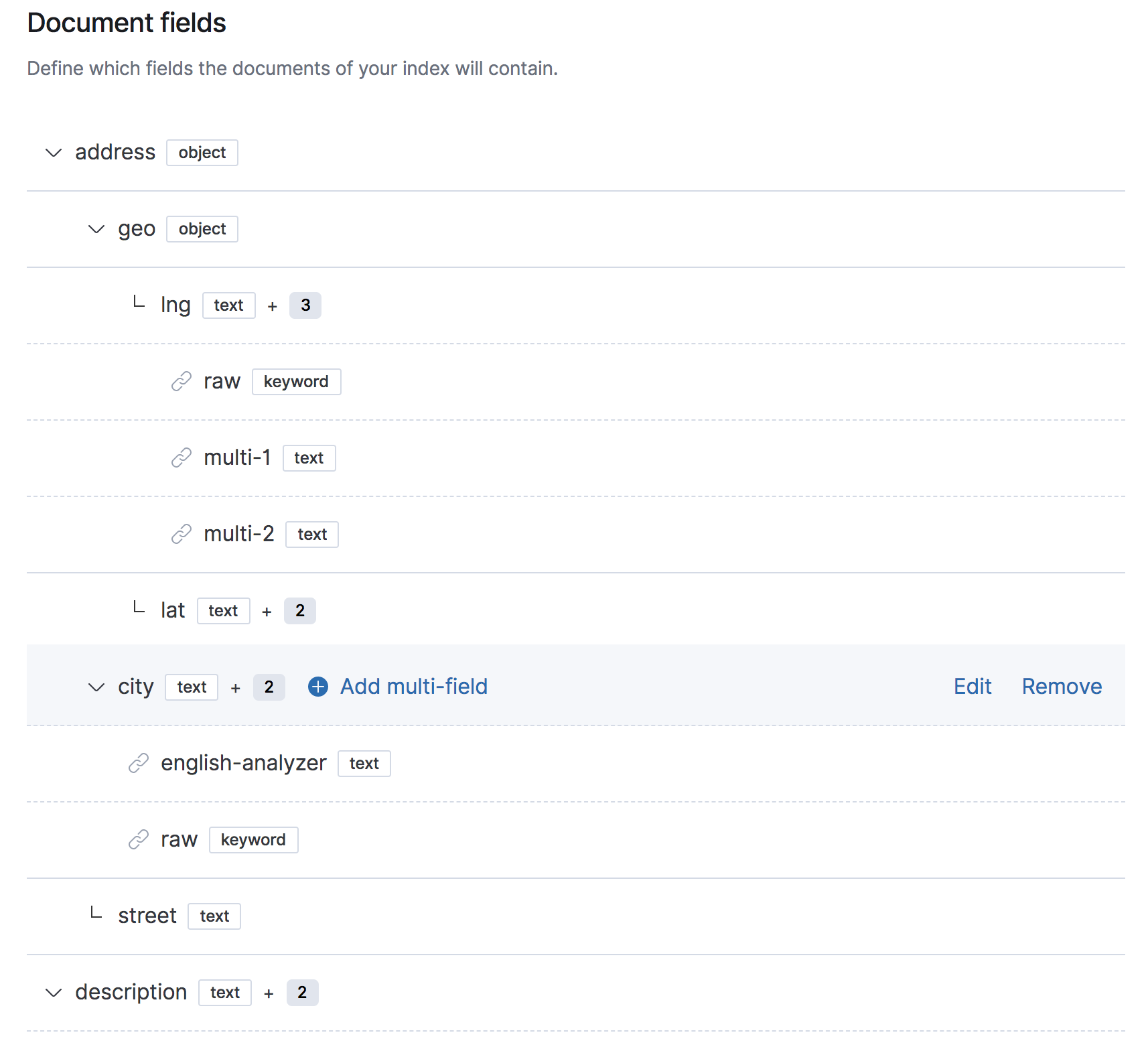
Forging ahead with the Mappings Editor
We have given the core of the mappings editor some great UI/UX improvements. The core is responsible for adding, editing and removing fields to the document. For each field a "name" and a "type" can be specified. The core is also responsible for managing "nested" fields and "multi-fields". These changes are living in the Mappings Editor feature branch at the moment #47562
Next up we are working on the parameters form for each type, starting with "text", "keyword" and “numeric".
Here’s the UI
Snapshot resilience
We merged a big change to the way shard-level snapshot metadata is handled. The master now keeps track of the state of each shard's metadata, which eliminates an issue where a data node could corrupt the repository or part of it as data nodes now only write new blobs (with unique ids) but never update or delete any blobs from the repository. Another effect of this change is that data nodes don't have to list out each shard-level directory to find the latest metadata generation as they used to do. This improves resiliency on S3 (due to it's eventually consistent nature) and reduces the cost of snapshotting an unchanged shard directory by 33% (we want to bring the cost for that down to zero in a follow-up). Since snapshotting unchanged shards can be a significant contributor to snapshot costs, for users that use rolling indices this change should visibly reduce their snapshot cost.
Vector Fields: path to GA
Today we have two types for vectors, dense_vector, which has a value for all dimensions, and sparse_vector, that keeps only the non-null dimensions. While sparse_vector could be useful in the future, we don't have a good enough sense of use cases/requirements around the current implementation to take it to GA, and we also don’t want to keep it as experimental, It would be a bit confusing if dense_vector were GA, but not sparse_vector. We haven’t seen any usage of sparse_vector, so we opened a PR to deprecate them in 7.6 and removing it in 8.0.
Diagnostic Trust Manager
We are always working on making security configuration issues easier to diagnose and triage. Tim V has been working on a Diagnostic Trust Manager; the idea here is that this manager wraps another Trust Manager, catches any failures, and provides logging around what went wrong. This work is early days, but here’s an example log message:
[2019-10-24T21:13:21,223][WARN ][o.e.c.s.DiagnosticTrustManager] [testDiagnosticTrustManagerForHostnameVerificationFailure] failed to establish trust with [SERVER] at [127.0.0.1]; the server provided a certificate with subject name [CN=not-this-host] and fingerprint [b46447f4e16b15a4770a8423884cb5afd31ad81f]; the certificate has subject alternative names [DNS:not.this.host]; the certificate is issued by [CN=Certificate Authority 1,OU=ssl-error-message-test,DC=elastic,DC=co] but the server did not provide a copy of the issuing certificate; the issuing certificate is trusted in this context with fingerprint [2d5980e0c909cfc9ab4a77ad11e1f7b951ee7e13]
Geo
We are proposing a new data structure for geo_shape doc values. Current approach is based on how we represent query data shapes by representing polygons and lines as an edge tree. The new approach uses the same tessellation strategy used for indexing shapes on the BKD tree where shapes are broken in triangles, lines and points. This approach might be more suitable in order to perform complex spatial operations with shapes but it might have a penalty on the size of those doc values. For example, one of the performance optimizations we can do with doc values is to use the query IndexOrDocValuesQuery that Lucene provides. In order to do that we should be able to compute the spatial relationship (disjoint, within, intersects) between the query shape and the doc value. This computation might be easier to perform with the approach based on geometry tessellation.
Apache Lucene
Off-heap BKD index
Our change to move the BKD index off-heap has been merged. In practice, the index will only be loaded off-heap when the index input is an instance of ByteBufferIndexInput (used by MmapDirectory) since other index inputs like the ones created by SimpleFSDirectory on NIOFSDirectory don't support efficient random-access. In order to leverage this change in Elasticsearch, we would need to change our default hybrid directory to open BKD trees with mmap.
SIMD-based decoding of postings
For space-efficiency reasons, postings don't record doc IDs as 32-bit integers. Instead, doc IDs are delta-encoded to make them smaller, grouped into blocks of 128 deltas and then encoded on just as many bits are required. Our current decoding logic is a bit naive and only processes one doc ID at a time. Yet it is possible to use SIMD instructions to decode multiple values at once and make decoding more efficient. Java doesn't expose the ability to use SIMD instructions directly, but its C2 compiler is able to recognize some access patterns that can be vectorized. It doesn't give the same flexibility as one would have when writing C code, but it is still possible to exploit these patterns that the JVM recognizes to make decoding faster. We have a prototype that decodes 128 packed integers from a ByteBuffer about 2x faster than the current implementation, which translates to a 0-10% speedup on the queries that we run in our nightly benchmarks. This is unfortunately proving challenging to integrate API-wise as it requires the addition of new APIs to DataInput to more efficiently read longs.
Other
- We should be able to make doc-value terms queries more efficient by optimizing the lookup logic for the case that it is called over a sorted sequence of terms.
- We have an open pull request to implement selection via the median of medians algorithm.
- We disabled caching on GlobalOrdinalsWithScoreQuery, since it is a memory-intensive query that doesn't make sense to cache.
Changes in Elasticsearch
Changes in 8.0:
- Update docker-compose.yml to fix bootstrap check error #47650
- Remove type filter from GetMappings API #47364
- Update docker.asciidoc #47651
Changes in 7.6:
- Change grok watch dog to be Matcher based instead of thread based. #48346
- Add a deprecation warning regarding allocation awareness in search request #48351
- Correct rewritting of script_score query #48425
- Do not throw errors on unknown types in SearchAfterBuilder #48147
- Geo: improve handling of out of bounds points in linestrings #47939
- Deprecate the sparse_vector field type. #48315
- Track Shard-Snapshot Index Generation at Repository Root #46250
- [Java.time] Calculate week of a year with ISO rules #48209
- Use MultiFileTransfer in CCR remote recovery #44514
- Don't build packages on non Linux #48246
- update ingest-user-agent regexes.yml #47807
- Quieter logging from the DiskThresholdMonitor #48115
Changes in 7.5:
- Add a packagingTask for every os project #48400
- [Transform] do not fail checkpoint creation due to global checkpoint mismatch #48423
- Add populate_user_metadata in OIDC realm #48357
- Ensure SLM stats does not block an in-place upgrade from 7.4 #48367
- Read build and runtime java from properties file #48355
- SearchSlowLog uses a non thread-safe object to escape json #48363
- Add 'javadoc' task to CI lifecycle check tasks #48214
- [Docs] Fix testing docs regarding --debug-jvm #48293
- Switch to debug with server=n #48188
- Fix security origin for TokenService#findActiveTokensFor... #47418
- Increase timeout for yml tests #48237
- Fix download of 6.x rpm and deb packages #48228
Changes in 7.4:
- Change policy_id to list type in slm.get_lifecycle #47766
- Lucene#asSequentialBits gets the leadCost backwards. #48335
- SQL: add "format" for "full" date range queries #48073
- fix incorrect comparison #48208
Changes in 7.3:
- [7.4] [DOCS] Extends analyzed.fields description in DFA resources #48306
Changes in 6.8:
- Download jdk to a temp file to make sure retries work #48249
- Do not reference values for filtered settings #48066
- Relative paths, jornalctl in additional logs #48276
- Handle negative free disk space in deciders #48392
- [DOCS] 6.8.4 release notes #48360
- Cleanup Concurrent RepositoryData Loading #48329
- Always publish a build scan in CI #48348
- Use an env var for the classpath of jar hell task #48240
- Fix link to GCP upload in build scans #48248
- Close query cache on index service creation failure #48230
- Create an upload report once the build completes #47642