Try it out
editTry it out
editWhen the model is deployed on at least one node in the cluster, you can begin to perform inference. Inference is a machine learning feature that enables you to use your trained models to perform NLP tasks (such as text extraction, classification, or embeddings) on incoming data.
The simplest method to test your model against new data is to use the Test model action in Kibana. You can either provide some input text or use a field of an existing index in your cluster to test the model:
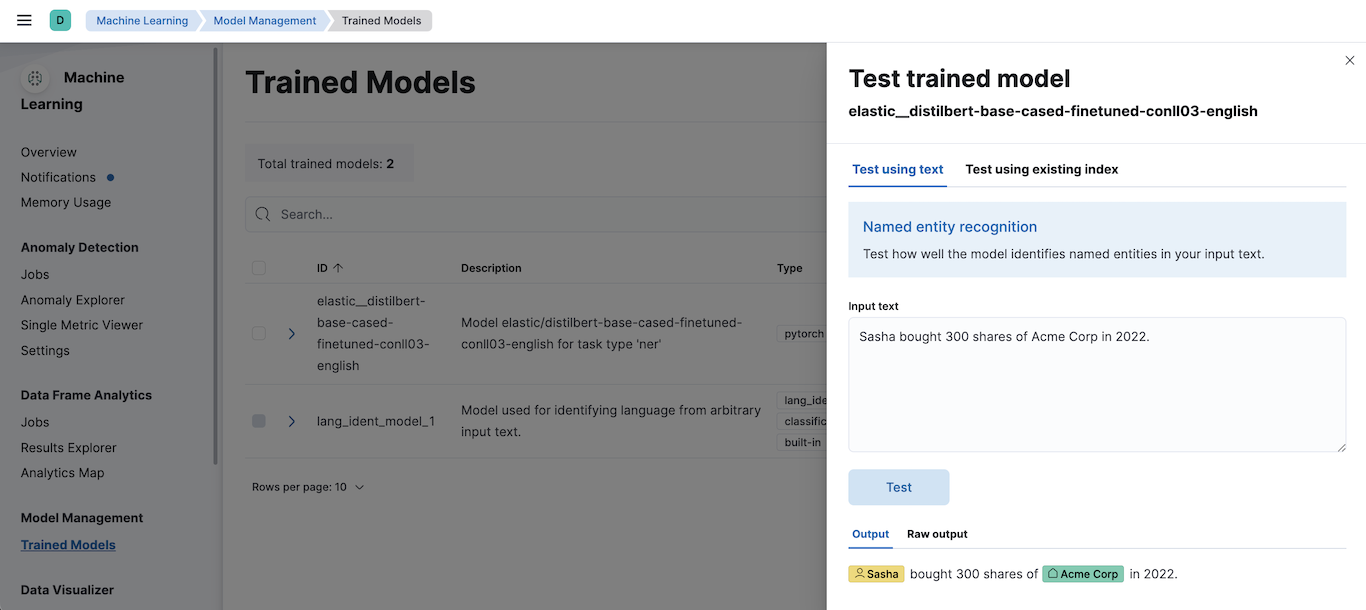
Alternatively, you can use the infer trained model API. For example, to try a named entity recognition task, provide some sample text:
POST /_ml/trained_models/elastic__distilbert-base-cased-finetuned-conll03-english/_infer
{
"docs":[{"text_field": "Sasha bought 300 shares of Acme Corp in 2022."}]
}
In this example, the response contains the annotated text output and the recognized entities:
{
"inference_results" : [
{
"predicted_value" : "[Sasha](PER&Sasha) bought 300 shares of [Acme Corp](ORG&Acme+Corp) in 2022.",
"entities" : [
{
"entity" : "Sasha",
"class_name" : "PER",
"class_probability" : 0.9953193407987492,
"start_pos" : 0,
"end_pos" : 5
},
{
"entity" : "Acme Corp",
"class_name" : "ORG",
"class_probability" : 0.9996392198381716,
"start_pos" : 27,
"end_pos" : 36
}
]
}
]
}
If you are satisfied with the results, you can add these NLP tasks in your ingestion pipelines.