Deploy the model in your cluster
editDeploy the model in your cluster
editAfter you import the model and vocabulary, you can use Kibana to view and manage their deployment across your cluster under Machine Learning > Model Management. Alternatively, you can use the start trained model deployment API.
You can deploy a model multiple times by assigning a unique deployment ID when starting the deployment. It enables you to have dedicated deployments for different purposes, such as search and ingest. By doing so, you ensure that the search speed remains unaffected by ingest workloads, and vice versa. Having separate deployments for search and ingest mitigates performance issues resulting from interactions between the two, which can be hard to diagnose.
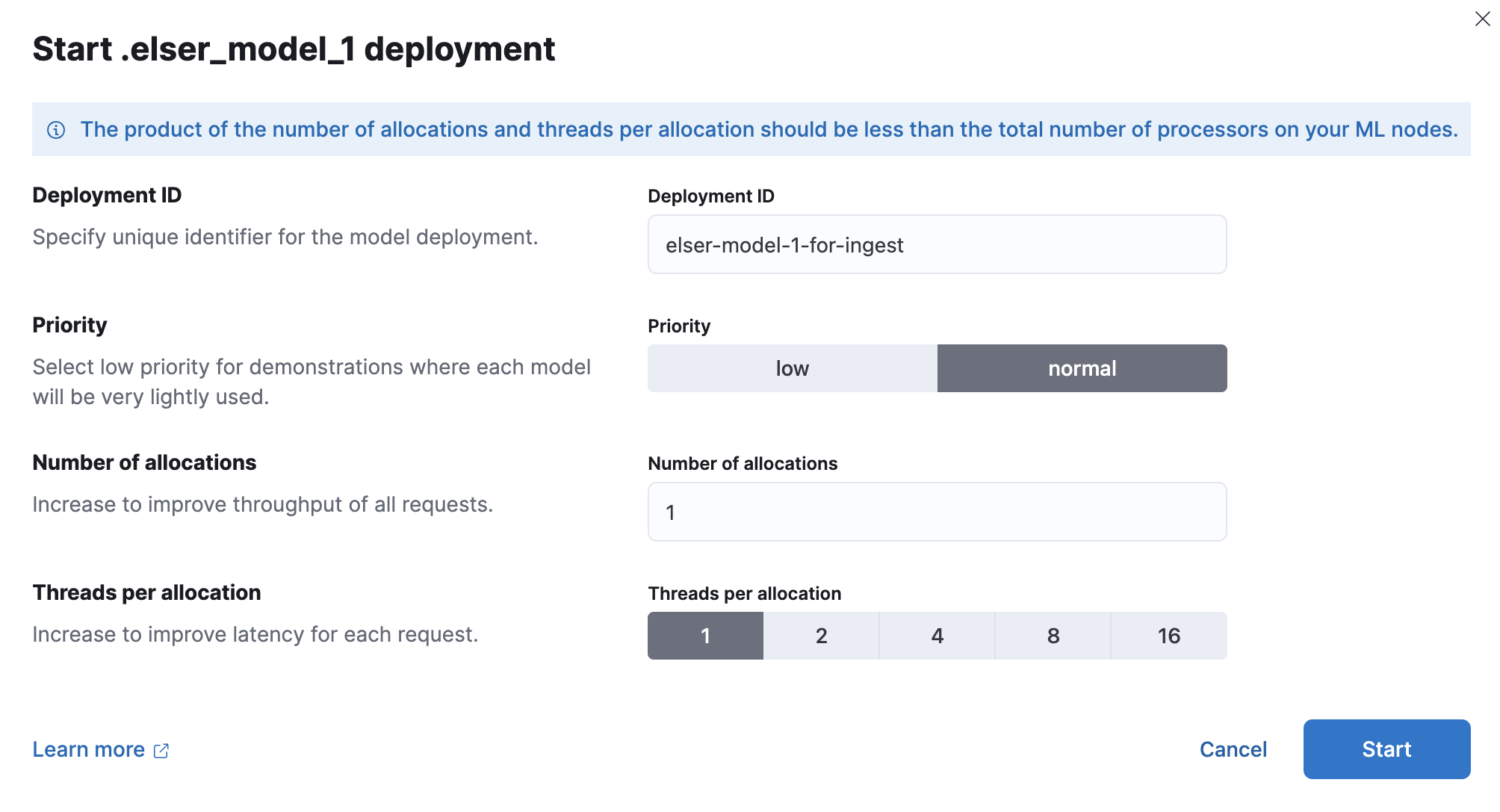
It is recommended to fine-tune each deployment based on its specific purpose. To improve ingest performance, increase throughput by adding more allocations to the deployment. For improved search speed, increase the number of threads per allocation.
Since eland uses APIs to deploy the models, you cannot see the models in Kibana until the saved objects are synchronized. You can follow the prompts in Kibana, wait for automatic synchronization, or use the sync machine learning saved objects API.
When you deploy the model, its allocations are distributed across available machine learning nodes. Model allocations are independent units of work for NLP tasks. To influence model performance, you can configure the number of allocations and the number of threads used by each allocation of your deployment.
If your deployed trained model has only one allocation, it’s likely that you will experience downtime in the service your trained model performs. You can reduce or eliminate downtime by adding more allocations to your trained models.
Throughput can be scaled by adding more allocations to the deployment; it
increases the number of inference requests that can be performed in parallel. All
allocations assigned to a node share the same copy of the model in memory. The
model is loaded into memory in a native process that encapsulates libtorch,
which is the underlying machine learning library of PyTorch. The number of allocations
setting affects the amount of model allocations across all the machine learning nodes. Model
allocations are distributed in such a way that the total number of used threads
does not exceed the allocated processors of a node.
The threads per allocation setting affects the number of threads used by each model allocation during inference. Increasing the number of threads generally increases the speed of inference requests. The value of this setting must not exceed the number of available allocated processors per node.
You can view the allocation status in Kibana or by using the
get trained model stats API. If you to
change the number of allocations, you can use the
update trained model stats API after
the allocation status is started.
Request queues and search priority
editEach allocation of a model deployment has a dedicated queue to buffer inference
requests. The size of this queue is determined by the queue_capacity parameter
in the
start trained model deployment API.
When the queue reaches its maximum capacity, new requests are declined until
some of the queued requests are processed, creating available capacity once
again. When multiple ingest pipelines reference the same deployment, the queue
can fill up, resulting in rejected requests. Consider using dedicated
deployments to prevent this situation.
Inference requests originating from search, such as the
text_expansion query, have a higher
priority compared to non-search requests. The inference ingest processor generates
normal priority requests. If both a search query and an ingest processor use the
same deployment, the search requests with higher priority skip ahead in the
queue for processing before the lower priority ingest requests. This
prioritization accelerates search responses while potentially slowing down
ingest where response time is less critical.