Handling delayed data
editHandling delayed data
editDelayed data are documents that are indexed late. That is to say, it is data related to a time that your datafeed has already processed and it is therefore never analyzed by your anomaly detection job.
When you create a datafeed, you can specify a
query_delay setting.
This setting enables the datafeed to wait for some time past real-time, which
means any "late" data in this period is fully indexed before the datafeed tries
to gather it. However, if the setting is set too low, the datafeed may query for
data before it has been indexed and consequently miss that document. Conversely,
if it is set too high, analysis drifts farther away from real-time. The balance
that is struck depends upon each use case and the environmental factors of the
cluster.
Why worry about delayed data?
editIf data are delayed randomly (and consequently are missing from analysis), the
results of certain types of functions are not really affected. In these
situations, it all comes out okay in the end as the delayed data is distributed
randomly. An example would be a mean metric for a field in a large collection
of data. In this case, checking for delayed data may not provide much benefit.
If data are consistently delayed, however, anomaly detection jobs with a low_count
function may provide false positives. In this situation, it would be useful to
see if data comes in after an anomaly is recorded so that you can determine a
next course of action.
How do we detect delayed data?
editIn addition to the query_delay field, there is a delayed data check config,
which enables you to configure the datafeed to look in the past for delayed data.
Every 15 minutes or every check_window, whichever is smaller, the datafeed
triggers a document search over the configured indices. This search looks over a
time span with a length of check_window ending with the latest finalized bucket.
That time span is partitioned into buckets, whose length equals the bucket span
of the associated anomaly detection job. The doc_count of those buckets are then
compared with the job’s finalized analysis buckets to see whether any data has
arrived since the analysis. If there is indeed missing data due to their ingest
delay, the end user is notified. For example, you can see annotations in Kibana
for the periods where these delays occur:
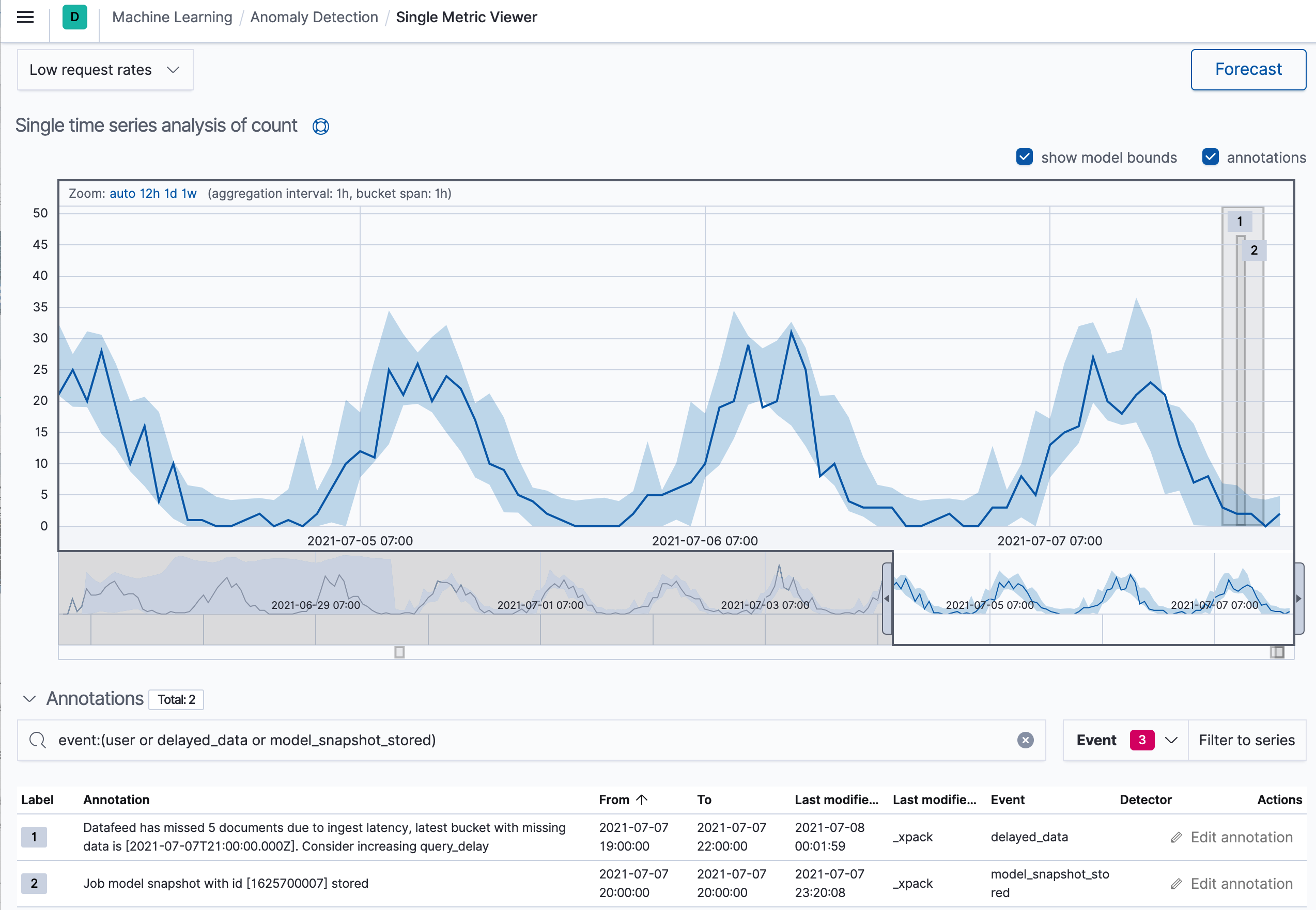
There is another tool for visualizing the delayed data on the Annotations tab in the anomaly detection job management page:
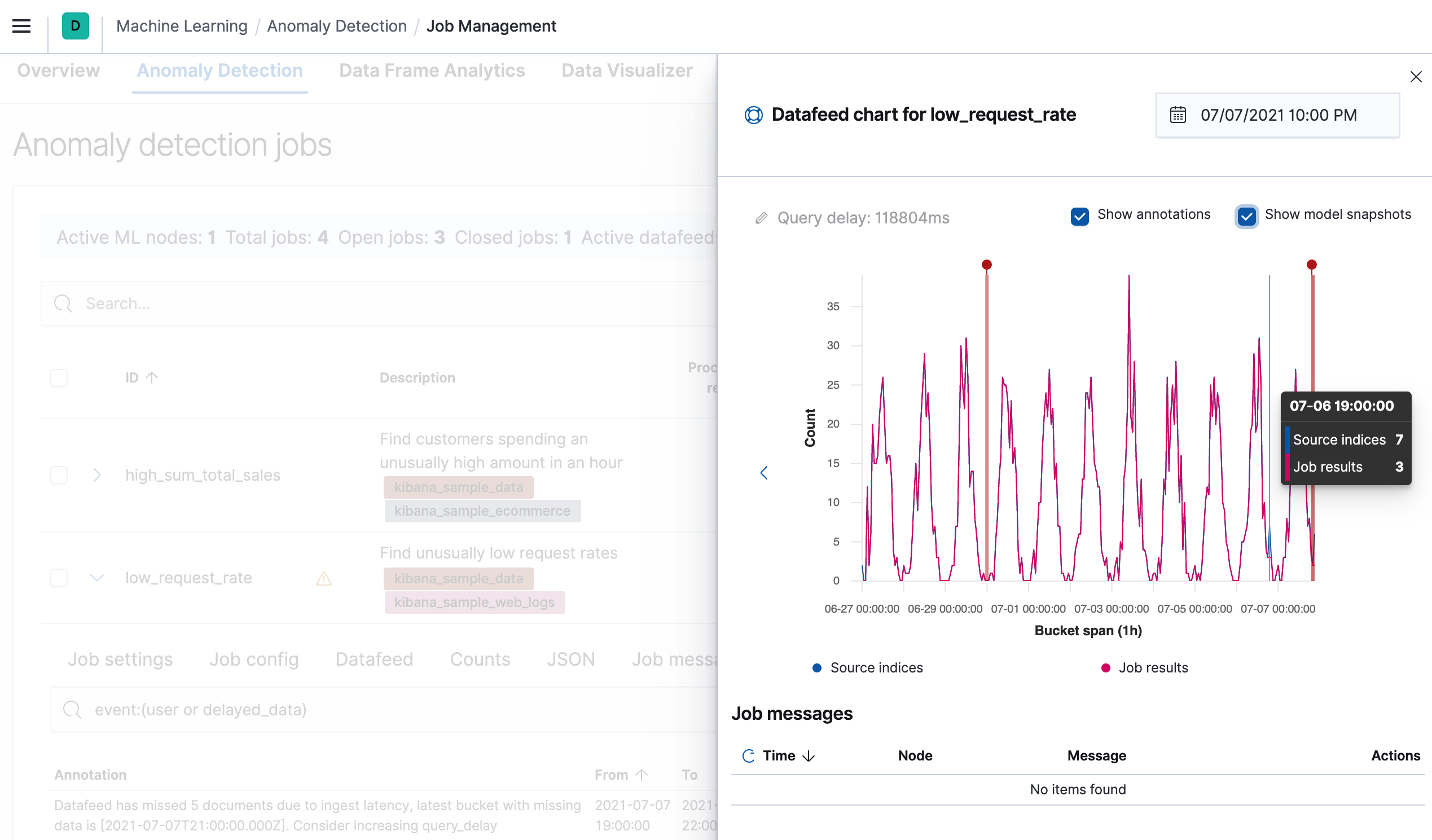
What to do about delayed data?
editThe most common course of action is to simply to do nothing. For many functions
and situations, ignoring the data is acceptable. However, if the amount of
delayed data is too great or the situation calls for it, the next course of
action to consider is to increase the query_delay of the datafeed. This
increased delay allows more time for data to be indexed. If you have real-time
constraints, however, an increased delay might not be desirable. In which case,
you would have to tune for better indexing speed.