What’s new in 8.3
editWhat’s new in 8.3
editHere are the highlights of what’s new and improved in Elasticsearch 8.3!
Other versions:
We have improved the pipeline execution logic for pipelines with processors that are synchronous by avoiding (deep) recursion. On our nightly benchmark that simulates a Logging use-case, this resulted in a 10% reduction of CPU time spent on ingest pipelines and a 3% overall ingestion speedup.
Ingest pipelines have a mechanism to prevent circular references in the records
they process, so that they are serializable. Prior to this change, this check was
performed after each script processor execution, and was ignorable.
Because of this check, a script processor configured with
"source": """
def x = ctx;
ctx.x = x;
"""
…would error with "type" : "illegal_argument_exception", "reason" : "Iterable
object is self-referencing itself (ingest script)".
If the script processor also had
"ignore_failure" true
…then the handling thread would actually crash from an unrecoverable StackOverflowError when trying to serialize the resulting event.
Now, this check is performed once per pipeline, remediating the potential for a StackOverflowError. There are some side effects also:
- The resulting error message specifies which pipeline is causing the issue.
- There is a slight speed up for pipelines with multiple scripts, and a slight slowdown for pipelines without scripts.
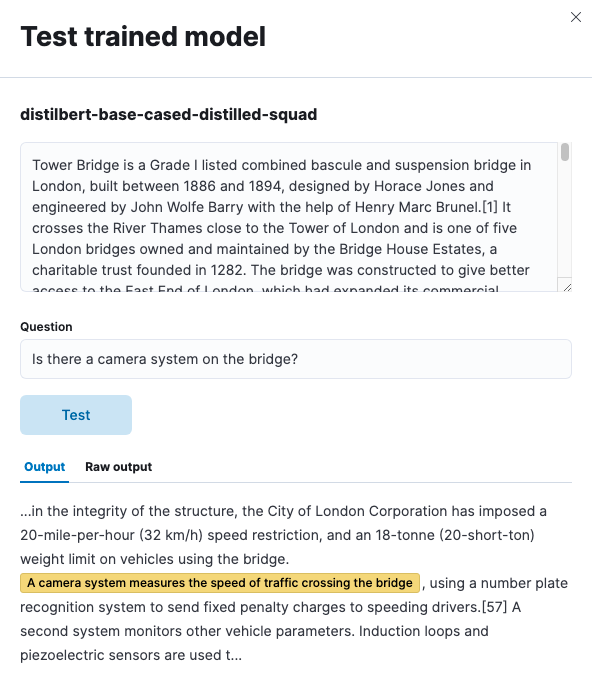
We introduce a new question answering NLP task in 8.3. This task extracts the relevant section that answers a specific question from a larger context. This is especially suited to search requests against large documents. You can see an example of extracting an answer from a larger wiki article about Tower Bridge below.
Metrics data can often be made of several fields with dots in their names, sharing common prefixes, like in the following example:
{
"metrics.time" : 10,
"metrics.time.min" : 1,
"metrics.time.max" : 500
}
Such format causes a mapping conflict as the metrics.time holds a value,
but it also needs to be mapped as an object in order to hold the min and
max leaf fields.
A new object mapping parameter called subobjects, which defaults to true,
has been introduced to preserve dots in field names. An object with subobjects
set to false can only ever hold leaf sub-fields and no further objects. The
following example shows how it can be configured in the mappings for the
metrics object:
{
"mappings": {
"properties" : {
"metrics" : {
"type" : "object",
"subobjects" : false
}
}
}
}
With this configuration any child of metrics will be mapped unchanged,
without expanding dots in field names to the corresponding object structure.
That makes it possible to store the metrics document above.
Elasticsearch has full query and write support for indices created in the previous major version. If you have indices created in Elasticsearch versions 5 or 6, you can now use the archive functionality to import and query these indices as well. The archive functionality provides slower read-only access to older data, for compliance or regulatory reasons, the occasional lookback or investigation, or to rehydrate parts of it. Access to the data is expected to be infrequent, and can therefore happen with limited performance and query capabilities.
Now it is possible to use the range aggregations in transforms. Transforms didn’t support multi-bucket aggregations, but this limitation no longer exists.
With the geo grid query, you can now natively return all the documents that overlap a specific geo tile. There is no need to reconstruct the geometry or the actual boundaries of the spatial cluster as Elasticsearch can do this for you, which saves you time and reduces complexity. This is especially useful when geometries are spread across tiles like on a soccer ball or football. While hexagon tiles line the sphere, calculating the boundary of each tile is not straightforward.
GET /example/_search
{
"query": {
"geo_grid" :{
"location" : {
"geotile" : "6/32/22"
}
}
}
}
Geo grid query can also help determine the single source of truth of containment. With geo grid query, you can match exactly the intersection-test of Elasticsearch. As an example, if a client has bounds for a grid-cell at a higher (or lower) precision than what is used by Elasticsearch when running a corresponding aggregation, the containment-check might be slightly different. This side-steps any disconnect based on projection/datum difference between client and Elasticsearch.