What’s new in 8.11
editWhat’s new in 8.11
editHere are the highlights of what’s new and improved in Elasticsearch 8.11! For detailed information about this release, see the Release notes and Migration guide.
Other versions:
8.10 | 8.9 | 8.8 | 8.7 | 8.6 | 8.5 | 8.4 | 8.3 | 8.2 | 8.1 | 8.0
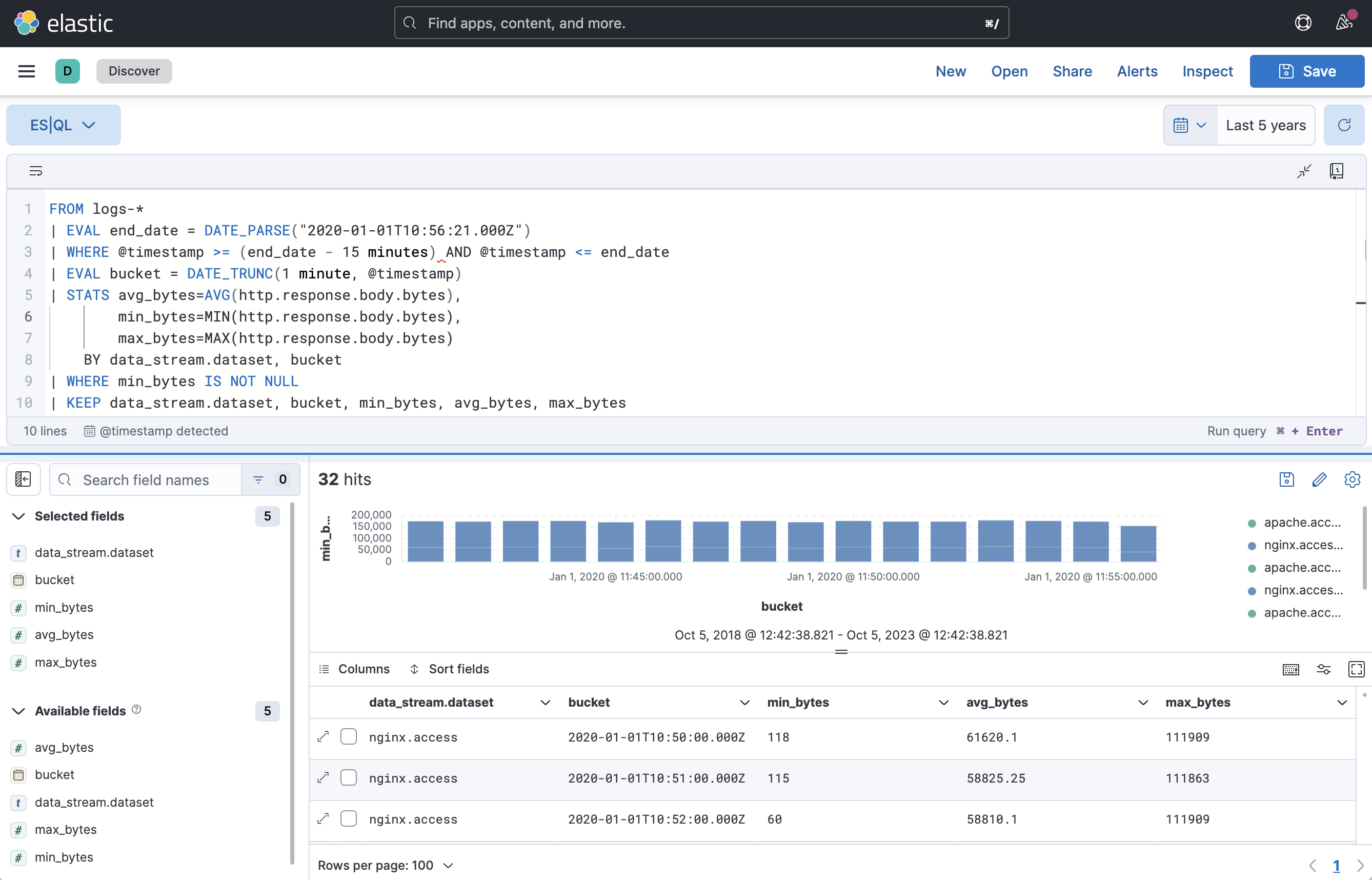
ES|QL — a new query language for flexible, iterative analytics in technical preview
editAs the Elastic Platform has become more widely adopted for search, security, observability, and general analytics, analyst users require the ability to take data-as-ingested, transform it to fit their investigative needs post-ingestion, and derive insights from underlying Elasticsearch index data. They need a concise, integrated, and efficient workflow enabled by rich and expressive queries where search, filter, aggregation, and transformation are performed via a single query expression with little-to-no UI context switching.
To solve these challenges, the Elastic team is developing the Elasticsearch Query Language (ES|QL). ES|QL provides Elastic users with a flexible, powerful, and robust query expression language to interrogate data. ES|QL also provides a superior query UX with post-ingest processing capabilities that fundamentally transforms and expands the analytics and data processing capabilities of Elasticsearch.
ES|QL introduces distributed compute capabilities to users in disparate roles and with varying skill levels. These compute capabilities enable ES|QL to simplify user workflows in several key ways.
- Utilize a superior query UX: ES|QL query expressions support complex analytics and data processing. They are easy to learn, read, and share.
- Use the filter, aggregation, and transformation capabilities of Elasticsearch with subqueries and lookups, made possible by new Elasticsearch compute and data processing capabilities.
- Use ES|QL across Kibana in Discover, Kibana Lens, and Elastic Solutions, giving you seamless workflows. You will be able to visualize ES|QL queries, share them with teams on dashboards or as queries, and use queries to create custom alerts.
- In Elastic Security, create an ES|QL rule and use ES|QL to investigate events in Timeline. Use the AI Assistant to write queries, or answer questions about the ES|QL query language.
The data stream lifecycle is now in Technical Preview
editThis marks the data stream lifecycle as available in Technical Preview. Data streams will be able to take advantage of a built-in simplified and resilient lifecycle implementation. Data streams with a configured lifecycle will be automatically rolled over and tail merged (a forcemerge implementation that’s lightweight and only merges the long tail of small segments instead of the whole shard). With the shard and index maintenance tasks being handled automatically to ensure optimum performance, and trade-off between indexing and searching, you’ll be able to focus on the business related lifecycle aspects like data retention.
Use IndexWriter.flushNextBuffer() to reclaim memory from indexing buffers
editRather than forcing a refresh to reclaim memory from indexing buffers, which flushes all
segments no matter how large, Elasticsearch now takes advantage of
IndexWriter#flushNextBuffer which only flushes the largest pending segment. This should smooth
out indexing allowing for larger segment sizes, fewer merges and higher throughput.
Furthermore, the selection algorithm to pick which shard to reclaim memory from next was changed, from picking the shard that uses the most RAM to going over shards in a round-robin fashion. This approach has proved to work significantly better in practice.