Adding nodes to your cluster
editAdding nodes to your cluster
editWhen you start an instance of Elasticsearch, you are starting a node. An Elasticsearch cluster
is a group of nodes that have the same cluster.name attribute. As nodes join
or leave a cluster, the cluster automatically reorganizes itself to evenly
distribute the data across the available nodes.
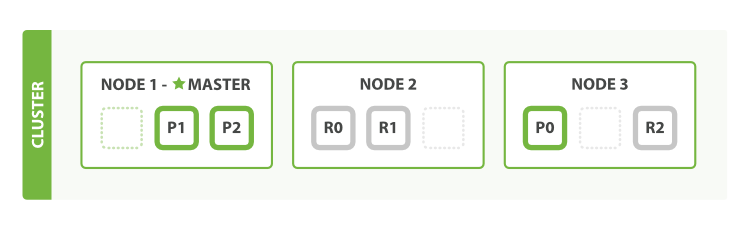
If you are running a single instance of Elasticsearch, you have a cluster of one node. All primary shards reside on the single node. No replica shards can be allocated, therefore the cluster state remains yellow. The cluster is fully functional but is at risk of data loss in the event of a failure.

You add nodes to a cluster to increase its capacity and reliability. By default, a node is both a data node and eligible to be elected as the master node that controls the cluster. You can also configure a new node for a specific purpose, such as handling ingest requests. For more information, see Nodes.
When you add more nodes to a cluster, it automatically allocates replica shards. When all primary and replica shards are active, the cluster state changes to green.
To add a node to a cluster:
- Set up a new Elasticsearch instance.
-
Specify the name of the cluster in its
cluster.nameattribute. For example, to add a node to thelogging-prodcluster, setcluster.name: "logging-prod"inelasticsearch.yml. - Start Elasticsearch. The node automatically discovers and joins the specified cluster.
For more information about discovery and shard allocation, see Discovery and cluster formation and Shard allocation and cluster-level routing.