Applying a new plan: Resize and add high availability
editApplying a new plan: Resize and add high availability
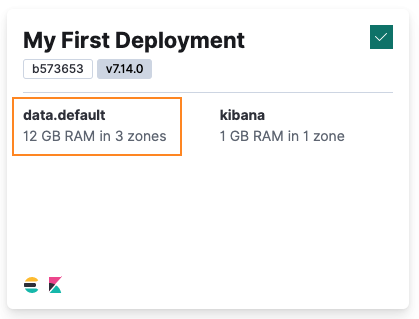
editIn the previous example, we created a simple deployment called My First Deployment that included a small Elasticsearch cluster, consisting of a single hot_content tier, together with a Kibana instance. The hot_content tier is relatively small with only 2048 MB of RAM. Indexing activity can often require more capacity, so let’s increase the amount of RAM and storage available to the tier. RAM and storage are coupled, so setting memory for the tier to 4096 allocates it with 4GB of RAM and 128GB of storage. To make the hot_content tier highly available, let’s also change the value of zone_count to 3 to replicate the tier across three availability zones.
Before you begin
editThis example requires a deployment with an Elasticsearch cluster to work with that is not being used for anything important. If you don’t already have one, you can follow our My First Deployment example to create one.
To make the cluster highly available, your Elastic Cloud Enterprise installation must include more than one availability zone, which is something you control with the --availability-zone parameter when you install Elastic Cloud Enterprise on additional hosts. If you don’t have additional availability zones to work with, you can perform just a resize operation.
To resize a resource from a deployment and add high availability we will do a PUT request to an existing deployment. We will use the same body we used to create the deployment, with the following differences:
- The name of the deployment can be modified or it will stay the same if not specified.
-
prune_orphansis an important parameter. It specifies how resources not included in the body of this PUT request should be handled:-
if
true, those resources not included will be shut down -
if
false, those resources not included will be kept intact
-
if
For example, we can update only the Elasticsearch resource in the deployment, without making any adjustments to the Kibana resource, by including only the Elasticsearch resource in the body and setting prune_orphans to false.
curl -k -X PUT -H "Authorization: ApiKey $ECE_API_KEY" https://$COORDINATOR_HOST:12443/api/v1/deployments/$DEPLOYMENT_ID -H 'content-type: application/json' -d '
{
"prune_orphans": false,
"resources":{
"elasticsearch": [{
"region": "ece-region",
"ref_id": "main-elasticsearch",
"plan":{
"cluster_topology": [
{
"id": "hot_content",
"node_roles": [
"data_hot",
"data_content",
"master",
"ingest",
"remote_cluster_client",
"transform"
],
"zone_count": 3,
"elasticsearch": {
"enabled_built_in_plugins": [],
"node_attributes": {
"data": "hot"
}
},
"instance_configuration_id": "data.default",
"size": {
"value": 4096,
"resource": "memory"
}
},
{
"id": "warm",
"node_roles": [
"data_warm",
"remote_cluster_client"
],
"zone_count": 1,
"elasticsearch": {
"enabled_built_in_plugins": [],
"node_attributes": {
"data": "warm"
}
},
"instance_configuration_id": "data.highstorage",
"size": {
"value": 0,
"resource": "memory"
}
},
{
"id": "cold",
"node_roles": [
"data_cold",
"remote_cluster_client"
],
"zone_count": 1,
"elasticsearch": {
"enabled_built_in_plugins": [],
"node_attributes": {
"data": "cold"
}
},
"instance_configuration_id": "data.highstorage",
"size": {
"value": 0,
"resource": "memory"
}
},
{
"id": "frozen",
"node_roles": [
"data_frozen"
],
"zone_count": 1,
"elasticsearch": {
"enabled_built_in_plugins": [],
"node_attributes": {
"data": "frozen"
}
},
"instance_configuration_id": "data.frozen",
"size": {
"value": 0,
"resource": "memory"
}
},
{
"id": "coordinating",
"node_roles": [
"ingest",
"remote_cluster_client"
],
"zone_count": 1,
"elasticsearch": {
"enabled_built_in_plugins": []
},
"instance_configuration_id": "coordinating",
"size": {
"value": 0,
"resource": "memory"
}
},
{
"id": "master",
"node_roles": [
"master",
"remote_cluster_client"
],
"zone_count": 1,
"elasticsearch": {
"enabled_built_in_plugins": []
},
"instance_configuration_id": "master",
"size": {
"value": 0,
"resource": "memory"
}
},
{
"id": "ml",
"node_roles": [
"ml",
"remote_cluster_client"
],
"zone_count": 1,
"elasticsearch": {
"enabled_built_in_plugins": []
},
"instance_configuration_id": "ml",
"size": {
"value": 0,
"resource": "memory"
}
}
],
"elasticsearch":{
"version": "7.14.0"
},
"deployment_template":{
"id": "default"
},
"autoscaling_enabled": false
}
}]
}
}
'
We could also add new resources as part of this PUT request and those would be included in the deployment. The response will always contain the list of all resources in the deployment (not only the updated ones).
After the plan is applied successfully, the hot_content data tier in your deployment has 4096MB of memory and is highly available with three availability zones. You can verify the new settings either in the ECE UI or by performing another GET request on the /api/v1/deployments/$DEPLOYMENT_ID/elasticsearch/$REF_ID endpoint, where $REF_ID is the value of the ref_id attribute for the Elasticsearch resource, typically main-elasticsearch.