It is time to say goodbye: This version of Elastic Cloud Enterprise has reached end-of-life (EOL) and is no longer supported.
The documentation for this version is no longer being maintained. If you are running this version, we strongly advise you to upgrade. For the latest information, see the current release documentation.
Common issues
editCommon issues
editInstallation failures with firewalld enabled on CentOS and RHEL
editSymptom: On CentOS and RHEL the installation of Elastic Cloud Enterprise fails, possibly indicating an issue that affects communication between Docker containers on the host.
Resolution: The issue might be caused by the firewalld service. The service is not compatible with Docker and interferes with the installation of ECE. You must disable firewalld with sudo systemctl disable firewalld and reboot before installing or reinstalling ECE.
To learn more, see the the configuration steps for Red Hat Enterprise Linux (RHEL) 7 and CentOS 7.
Allocator failures
editAllocator failures result in alerts in the Cloud UI. You cannot repair an allocator in the Cloud UI, so you should first move all nodes to a new allocator. Vacate options for a selected allocator can help fine tune the removal of nodes. After the allocator is vacated, you should investigate the cause of the failure separately, which could be due to a host machine failure, and replace any lost capacity.
Allocators not being used
editSymptoms: You installed Elastic Cloud Enterprise on a new host and assigned it the allocator role from the command line with the --roles "allocator" parameter during installation, but new clusters are not being created on the allocator.
Resolution: The issue is caused by a token specified with the --roles-token 'TOKEN' parameter that does not have sufficient privileges to assign the role correctly. To resolve this issue, you might need to refresh the roles for the allocator.
- Follow the steps for assigning roles to runners, but do not change any of the assigned roles. Click Update roles.
- Verify that the allocator is now being used when creating new Elasticsearch clusters or moving nodes off other allocators.
To avoid this issue on future allocators you create, generate a roles token that has the right permissions for this to work, in this case the permission to assign the allocator role; the token generated during the installation on the first host will not suffice.
Do you have an allocator that shows up in the Cloud UI but remains unused even after you have completed these steps? There might not be an issue. ECE version 1.0.x takes a fill first approach to using up all available space on previously used allocators before starting to use new ones. A future version of ECE will offer a distribute first approach that ensures the distribution of Elasticsearch clusters across available allocators, including any new ones that you might have added recently.
Cloud UI login failures
editSymptoms: When you attempt to log into the Cloud UI, the login process appears to hang and then fails.
Resolution: The administration console that supports the Cloud UI might be running out of Java heap space, causing login failures. This issue is expected to be fixed in a future release. As a workaround, you can manually increase the heap size.
In the current release, there is no direct way to change the Java heap size in the UI, so you need to increase the heap size as follows:
-
For convenience, you can store the IP address of the host machine where the Cloud UI is running in the
ADMIN_IPenvironment variable. Alternatively, replace$ADMIN_IPin the commands shown with the IP address. -
Create a file with your current configuration, here
containerdata.json(requires that you have jq installed):curl -u admin http://$ADMIN_IP:12400/api/v0/regions/ece-region/container-sets/admin-consoles | jq '.containers | ."admin-console" | .data' > containerdata.json
When prompted, enter the password you use to log into the Cloud UI.
-
Open the
containerdata.jsonfile in your favorite editor and locate this line:"ADMINCONSOLE_JAVA_OPTIONS=-Djute.maxbuffer=33554432 -Xmx256M -Xms256M",
-
Increase the Java heap size by changing the values for
XmxandXmsto 1024 or 4096, depending on the size of your host machine. For example: Change the values to-Xmx1024M -Xms1024M. - Save the configuration and exit the editor.
-
Apply the new configuration:
curl -XPOST -u admin 'http://$ADMIN_IP:12400/api/v0/regions/ece-region/container-sets/admin-consoles/containers/admin-console' -d @containerdata.json
-
On the host machine where the Cloud UI administration console is running, recreate the Cloud UI:
docker stop frc-admin-consoles-admin-console && docker rm -f frc-admin-consoles-admin-console
If you prefer, you can use the HTTPS protocol on port 12443, but it currently supports only a self-signed certificate. Alternatively, you can perform the step from localhost.
- Log into the Cloud UI administration console to confirm that the issue is resolved.
Cloud UI, Elasticsearch, and Kibana endpoint URLs inaccessible on AWS
editSymptoms: When you attempt to log into the Cloud UI or when you attempt to connect to an Elasticsearch or Kibana endpoint URL, the connection eventually times out with an error. The error indicates that the host cannot be reached.
Resolution: On AWS, the default URLs provided might point to a private host IP address, which is not accessible externally. To resolve this issue, use a URL for the Cloud UI that is externally accessible and update your cluster endpoint to use a public IP address for Elasticsearch and Kibana.
This issue applies only to hosts running on AWS, where both public and private IP addresses are provided.
To check if you are affected and to resolve this issue:
-
Compare the URL you are trying to reach to the host IP address information in the AWS EC2 Dashboard.
For example, on a Elastic Cloud Enterprise installation, the following URLs might be provided by default:
-
Cloud UI:
http://192.168.40.73:12400 -
Elasticsearch:
https://e025c4xxxxxxxxxxxxx.192.168.40.73.ip.es.io:9243/ -
Kibana:
https://1e2b57xxxxxxxxxxxxx.192.168.40.73.ip.es.io:9243/
A quick check in the AWS EC2 Dashboard confirms that
192.168.40.73is a private IP address, which is not accessible externally:
-
Cloud UI:
-
To resolve this issue:
-
For the Cloud UI, use the public host name or public IP. In this example, the Cloud UI is accessible externally at
ec2-54-162-168-86.compute-1.amazonaws.com:12400. -
For Elasticsearch and Kibana, update your cluster endpoint to use the public IP address. In this example, you can use
54.162.168.86: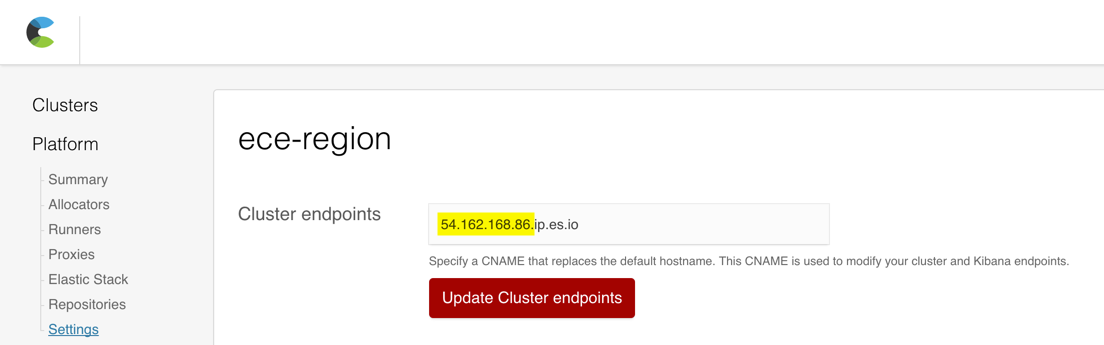
-
For the Cloud UI, use the public host name or public IP. In this example, the Cloud UI is accessible externally at
Upgrade failures
editSymptoms: When upgrading Elastic Cloud Enterprise, the upgrade process indicates that a container upgrade has failed, followed by a rollback of all container upgrades and an error message that the upgrade process has failed. The information you see is similar to this output:
...
- Runner [192.168.44.10]: container [proxies-proxy] status changed: [upgrade failed] at [2017-08-23T20:27:02.114Z]
- Runner [192.168.44.10]: container [proxies-proxy] status changed: [rollback started] at [2017-08-23T20:27:07.134Z]
...
- The upgrade of the {n} installation has failed, but we successfully rolled back changes.
- Check that all services are running and that they are at the same version level with the docker ps command. Try the upgrade again.
- The log files on each host might provide additional information about the cause of the failures. (path: HOST_STORAGE_PATH/logs/upgrader-logs).
- You can find a backup of ZooKeeper's transaction log that was created before the upgrade in [/mnt/data/elastic/192.168.44.10/services/zookeeper/data/backup/20170823-202249/version-2].
- Exiting upgrader
- Removing upgrade container
Resolution: The Elastic Cloud Enterprise upgrade process is designed to be safe. If there is an issue with any part of the upgrade, the entire process is rolled back. In most cases, the rollback is automatic and the upgrade process can be reattempted after you fix the issue that caused the rollback.
The upgrade process can fail for several reasons, including:
-
If a host fails during the upgrade process, causing the
frc-upgraders-monitorcontainer to time out while it monitors the upgrade process. -
If there is an issue with the ZooKeeper ensemble establishing a quorum after the upgrade or if the
frc-upgraders-upgradercontainers performing the upgrade on each host continue to wait for a ZooKeeper connection indefinitely to report their upgrade status. - If an upgraded container does not keep running and the upgrade process determines that it is not viable.
To determine the root cause of an upgrade failure, the following logs are available where HOST_STORAGE_PATH and RUNNER_ID are specific to your installation:
-
HOST_STORAGE_PATH/logs/upgrader-logs/monitor.log - Available on the host where you initiated the upgrade process. This log file can help you pinpoint the host where an upgrade issue occurred or where in the overall upgrade process a failure happened.
-
HOST_STORAGE_PATH/logs/upgrader-logs/upgrader.log - Available on every host that attempted the upgrade. This log file can tell you about the specific issues that caused the upgrade to fail on a host.
In rare cases, a manual rollback of the upgrade might be required. To have someone walk you through the process, see Getting help.