Web crawler (beta) reference
editWeb crawler (beta) reference
editThe Elastic Enterprise Search web crawler is a beta feature. Beta features are subject to change and are not covered by the support SLA of general release (GA) features. Elastic plans to promote this feature to GA in a future release.
See Web crawler (beta) for a guided introduction to the Elastic Enterprise Search web crawler.
Refer to the following sections for terms, definitions, tables, and other detailed information.
Crawl
editA crawl is a process, associated with an engine, by which the web crawler discovers web content, and extracts and indexes that content into the engine as search documents.
During a crawl, the web crawler stays within user-defined domains, starting from specific entry points, and it discovers additional content according to crawl rules. Operators and administrators manage crawls through the App Search dashboard.
Each crawl also respects various instructions embedded within the web content, such as canonical link tags, robots meta tags, and nofollow links.
Operators can monitor crawls using the ID and status of each crawl, and using the web crawler events logs.
Each engine may run one active crawl at a time, but multiple engines can run crawls concurrently.
Each crawl is stateless. Crawl state is not persisted, and crawls cannot be resumed.
Each re-crawl is a full crawl. Partial crawls are not supported at this time.
Content discovery
editTo begin each crawl, the web crawler populates a crawl queue with the entry points for the crawl. It then begins fetching and parsing each page in the queue. The crawler handles each page according to its HTTP response status code.
As the web crawler discovers additional URLs, it uses the crawl rules from the crawl configuration and instructions embedded within the content to determine which of those URLs it is allowed to crawl. The crawler adds the allowed URLs to the crawl queue.
If a page is not linked from other pages, the web crawler will not discover it. Refer to the web of pages in the following image. The crawler will not discover the page outlined in red, unless an admin adds its URL as an entry point for the domain:
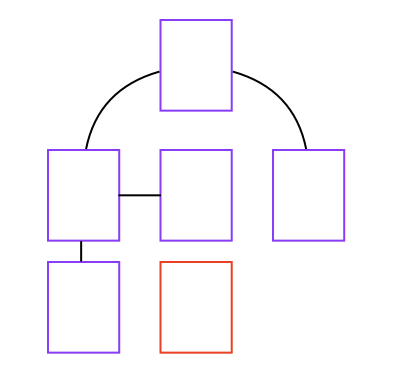
The web crawler continues fetching and adding to the crawl queue until the queue is empty, the crawler hits a resource limit, or the crawl fails unexpectedly.
The crawler logs detailed events while it crawls, which allow monitoring and auditing of the content discovery process.
Content extraction and indexing
editContent extraction is the process where the web crawler transforms an HTML document into a search document. And indexing is the process where the crawler puts the search document into an App Search engine for searching.
During content extraction, the web crawler checks for duplicate content. The crawler indexes duplicate web documents as a single search document.
The web crawler extracts each web document into a predefined schema before indexing it as a search document. At this time, the web crawler does not provide configuration or control over what content is extracted or how it is extracted.
During a crawl, the web crawler uses HTTP response status codes and robots meta tags to determine which documents it is allowed to index.
Content deletion
editThe web crawler must also delete documents from an engine to keep its documents in sync with the corresponding web content.
During a crawl, the web crawler uses HTTP response status codes to determine which documents to delete. However, this process cannot delete stale documents in the engine that are no longer linked to on the web.
Therefore, at the conclusion of each crawl, the web crawler begins an additional "purge" crawl, which fetches URLs that exist in the engine, but have not been seen on the web during recent crawls.
The crawler deletes from the engine all documents that respond with 4xx and 3xx responses during the phase.
HTTP response status codes
editThe web crawler handles HTTP response status codes as follows:
| Code | Description | Web crawler behavior |
|---|---|---|
|
Success |
The web crawler extracts and de-duplicates the page’s content into a search document. Then it indexes the document into the engine, replacing an existing document with the same content if present. |
|
Redirection |
The web crawler follows all redirects recursively until it receives a |
|
Client (permanent) error |
The web crawler assumes this error is permanent. It therefore does not index the document. Furthermore, if the document is present in the engine, the web crawler deletes the document. |
|
Server (impermanent) error |
The web crawler optimistically assumes this error will resolve in the future. Therefore, if this content is already present in the engine, the crawler retains the content but updates the timestamp and state to indicate it’s been re-crawled. |
Domain
editA domain is a website or other internet realm that is the target of a crawl. Each domain belongs to a crawl, and each crawl has one or more domains.
See Manage domains to manage domains for a crawl.
A crawl always stays within its domains when discovering content. It cannot discover and index content outside of its domains.
Each domain has a domain URL that identifies the domain using a protocol and hostname. The domain URL must not include a path.
Each unique combination of protocol and hostname is a separate domain. Each of the following is its own domain:
-
http://example.com -
https://example.com -
http://www.example.com -
https://www.example.com -
http://shop.example.com -
https://shop.example.com
Each domain has one or more entry points.
Each domain has one or more crawl rules.
Entry point
editAn entry point is a path within a domain that serves as a starting point for a crawl. Each entry point belongs to a domain, and each domain has one or more entry points.
See Manage entry points to manage entry points for a domain.
Use entry points to instruct the crawler to fetch URLs it would otherwise not discover. For example, if you’d like to index a page that isn’t linked from other pages, add the page’s URL as an entry point.
Ensure the entry points you choose are also allowed by crawl rules. The web crawler will not fetch entry points that are disallowed by crawl rules.
Crawl rule
editA crawl rule is a crawler instruction to allow or disallow specific paths within a domain. Each crawl rule belongs to a domain, and each domain has one or more crawl rules.
See Manage crawl rules to manage crawl rules for a domain.
During content discovery, the web crawler discovers new URLs and must determine which it is allowed to follow.
Each URL has a domain (e.g. https://example.com) and a path (e.g. /category/clothing or /c/Credit_Center).
The web crawler looks up the crawl rules for the domain, and applies the path to the crawl rules to determine if the path is allowed or disallowed. The crawler evaluates the crawl rules in order. The first matching crawl rule determines the policy for the newly discovered URL.
Each crawl rule has a path pattern, a rule, and a policy. To evaluate each rule, the web crawler compares a newly discovered path to the path pattern, using the logic represented by the rule, resulting in a policy.
Rules:
The logic for each rule is as follows:
- Begins with
-
The path pattern is a literal string (no metacharacters).
The rule matches when the path pattern matches the beginning of the path (which always begins with
/).If using this rule, begin your path pattern with
/. - Ends with
-
The path pattern is a literal string (no metacharacters).
The rule matches when the path pattern matches the end of the path.
- Contains
-
The path pattern is a literal string (no metacharacters).
The rule matches when the path pattern matches anywhere within the path.
- Regex
-
The path pattern is a regular expression compatible with the Ruby language regular expression engine. In addition to literal characters, the path pattern may include metacharacters, character classes, and repetitions. You can test Ruby regular expressions using Rubular.
The rule matches when the path pattern matches the beginning of the path (which always begins with
/).If using this rule, begin your path pattern with
\/or a metacharacter or character class that matches/.
Comparison examples:
| URL path | Rule | Path pattern | Match? |
|---|---|---|---|
|
Begins with |
|
YES |
|
Begins with |
|
NO |
|
Begins with |
|
NO |
|
Ends |
|
YES |
|
Ends |
|
NO |
|
Contains |
|
YES |
|
Contains |
|
NO |
|
Regex |
|
YES |
|
Regex |
|
NO |
|
Regex |
|
NO |
Order:
The first crawl rule to match determines the policy for the URL. Therefore, the order of the crawl rules is significant.
The following table demonstrates how crawl rule order affects the resulting policy for a path:
| Path | Crawl rules | Resulting policy |
|---|---|---|
|
1. 2. |
DISALLOW |
|
1. 2. |
ALLOW |
Restricting paths:
The domain dashboard adds a default crawl rule to each domain: Allow if Regex .*.
You cannot delete or re-order this rule through the dashboard.
This rule is permissive, allowing all paths within the domain. To restrict paths, use either of the following techniques:
Add rules that disallow specific paths (e.g. disallow the blog):
| Policy | Rule | Path pattern |
|---|---|---|
|
|
|
|
|
|
Or, add rules that allow specific paths and disallow all others (e.g. allow only the blog):
| Policy | Rule | Path pattern |
|---|---|---|
|
|
|
|
|
|
|
|
|
When you restrict a crawl to specific paths, be sure to add entry points that allow the crawler to discover those paths.
For example, if your crawl rules restrict the crawler to /blog, add /blog as an entry point.
If you leave only the default entry point of /, the crawl will end immediately, since / is disallowed.
Canonical URL link tag
editA canonical URL link tag is an HTML element you can embed within pages that contain duplicate content. The canonical URL link tag indicates the URL of the canonical page with the same content.
Template:
<link rel="canonical" href="{CANONICAL_URL}">
Example:
<link rel="canonical" href="https://example.com/categories/dresses/starlet-red-medium">
Robots meta tags
editRobots meta tags are HTML elements you can embed within pages to prevent the crawler from following links or indexing content.
Template:
<meta name="robots" content="{DIRECTIVES}">
Supported directives:
-
noindex - The web crawler will not index the page.
-
nofollow -
The web crawler will not follow links from the page (i.e. will not add links to the crawl queue). The web crawler logs a
url_discover_deniedevent for each link.The directive does not prevent the web crawler from indexing the page.
Examples:
<meta name="robots" content="noindex"> <meta name="robots" content="nofollow"> <meta name="robots" content="noindex, nofollow">
Nofollow link
editNofollow links are HTML links that instruct the crawler to not follow the URL.
The web crawler will not follow links that include rel="nofollow" (i.e. will not add links to the crawl queue).
The web crawler logs a url_discover_denied event for each link.
The link does not prevent the web crawler from indexing the page in which it appears.
Template:
<a rel="nofollow" href="{LINK_URL}">{LINK_TEXT}</a>
Example:
<a rel="nofollow" href="/admin/categories">Edit this category</a>
Crawl status
editEach crawl has a status, which quickly communicates its state.
See View crawl status to view the status for a crawl.
All crawl statuses:
- Pending
- The crawl is enqueued and will start after resources are available.
- Starting
- The crawl is starting. You may see this status briefly, while a crawl moves from pending to running.
- Running
- The crawl is running.
- Success
- The crawl completed without error. The web crawler may stop a crawl due to hitting resource limits. Such a crawl will report its status as success, as long as it completes without error.
- Canceling
- The crawl is canceling. You may see this status briefly, after choosing to cancel a crawl.
- Canceled
- The crawl was intentionally canceled and therefore did not complete.
- Failed
- The crawl ended unexpectedly. View the web crawler events logs for a message providing an explanation.
Web crawler schema
editThe web crawler indexes search documents using the following schema:
-
additional_urls - The URLs of additional pages with the same content.
-
body_content -
The content of the page’s
<body>tag with all HTML tags removed. -
content_hash - A "fingerprint" to uniquely identify this content. Used for de-duplication and re-crawling.
-
domains - The domains in which this content appears.
-
id - The unique identifier for the page.
-
links - Links found on the page.
-
meta_description -
The page’s description, taken from the
<meta name="description">tag. -
meta_keywords -
The page’s keywords, taken from the
<meta name="keywords">tag. -
title -
The title of the page, taken from the
<title>tag. -
url - The URL of the page.
Web crawler events logs
editWeb crawler configuration settings
editOperators can configure several web crawler settings.
See Configuration in the Enterprise Search documentation for a complete list of Enterprise Search configuration settings.
Settings beginning with crawler. are specific to the web crawler.
These settings include:
crawler.user_agent crawler.workers.pool_size.limit crawler.crawl.max_duration.limit crawler.crawl.max_crawl_depth.limit crawler.crawl.max_url_length.limit crawler.crawl.max_url_segments.limit crawler.crawl.max_url_params.limit crawler.crawl.max_unique_url_count.limit
Refer to the Enterprise Search documentation for an up-to-date list of all configuration settings.