Microsoft AzureにElasticsearchをデプロイする
UPDATE: This article refers to our old getting started experience for Elastic on Microsoft Azure. You can now take advantage of a more streamlined way to get started with Elastic on Microsoft Azure. Check out our latest blog to learn more.
最近、Azure OpenDevで発表する機会がありました。本日はElasticsearchとElastic Stackを稼働させて使用するとどのようになるのかについての概要を説明します。今日は、数分を使ってトピックのいくつかに関する詳細を見ていきたいと思います。
その前に、まずこの動画を紹介します。
イベントWebサイトでは、Microsoft、GitHub、CloudBees / Jenkins、Chef、HashiCorpによる他のトークを視聴することもできます
Azure Marketplace
このトークで説明されているとおり、AzureでElasticをはじめる最も簡単な方法は、Azure Marketplaceにある公式のデプロイテンプレートを使用することです。Azure Portalから直接デプロイすることができ、ElasticsearchとKibanaを立ち上げて稼働させるのに必要な手順、インスタンスとストレージのプロビジョニング、ソフトウェアのデプロイと設定、ネットワークのセットアップ、そして最後に諸々の導入といった具合に、すべての手順を処理していきます。
使用方法に関するわかりやすいブログ記事はこちらです。
今では、Marketplace経由でデプロイさせる以外の別の使用方法もあります。Azure Marketplace用のテンプレートはopen source(ソースはGithub上にある)ですので、コマンドラインからデプロイ備を選択することもできます。これにより、さまざまなものを自動化することができ、実行したい機能にカスタマイズを加えることも可能になります。これに関するわかりやすい別のブログ記事はこちらです。
テンプレートを使用する場合は、フィードバックを私たち(azuremarketplace@elastic.co)に共有してもらえるとありがたいです。
ハードウェア
以下は、Azureにデプロイする際に最もよくある質問の一部です。
どのインスタンスを使用すればよいですか?
本稿は2017年11月に記載されたものであることにご注意ください。
Elasticsearch - Data Node:私たちはDSシリーズのメモリ最適化インスタンスが問題なく適合していることを確認しました。あらゆる他のデータストアと同様、Elasticsearchでは、それ自体が利用できるメモリ(JVMヒープなど)や基幹となるホストシステム(重要なファイルシステムキャッシュに使用される)に利用できるメモリの量に対する依存度が極めて高いです。メモリを割り当てる方法に関するもう少し詳細な情報は、このブログ記事を読んでください。
Premium Storageを使用することもお勧めです。ソリッドステートドライブ(SSD)のおかげで、Elasticsearchは、保存されたデータにすぐに到達できるようになり、ユーザーにとっては応答時間が改善されます。Premium Managed Diskでは、保存データの暗号化(Storage Service Encryption)も付いています。
Elasticsearch - Master Node:大規模なクラスターの場合、専用マスターノードを3つ用意することをお勧めします。データを保存するわけではありませんが、新しいインデックスの作成やシャードのリバランスなどのクラスター管理タスクを処理してくれます。スモールDシリーズのインスタンスが適しているケースが最も多く見られます。
Kibana:マスターノードと同様に、Kibanaのリソース要件は比較的軽めです。ほとんどの演算処理はElasticsearchに落とし込まれるので、通常はスモールDシリーズのインスタンスでもKibanaを実行できます。
Logstash:Logstashは、通常数多くの処理を行うので、FSシリーズにデプロイするのが最適です。
可用性
インスタンスやゾーンの障害に直面してもオンラインを継続できる、高可用性のElasticsearchクラスターをデプロイしたいと思うことがしばしばあります。Azureには、冗長性をデプロイするのに役立つ考え方がいくつかあり、このドキュメントが参考になります。
リージョン:Azureには、地理的に区画されるリージョンが世界中にあります。各地域には複数のデータセンターが近接しています。どのリージョンが最も近いか、あるいはどのリージョンがユーザーのシステムに最も近いかを選択することがよくあります。Elasticsearchクラスターのすべてのノードは同じリージョンにデプロイする必要があります。
可用性セット:Elastic Stackの各層は個々のセットに配置する必要があります。Kibanaの2つのインスタンスは1つのセットに、Logstashの2つのインスタンスは別のセットに、Elasticsearchノードは3つ目のセットに配置する必要があります。
障害ドメインと更新ドメイン:Azureでは障害ドメインと更新ドメインにインスタンスを分散させます。計画メンテナンス中は、1度に1つの更新ドメインのみをリブートし、同じ故障ドメインにあるマシンのみが電源とネットワークスイッチを共有します。ドメイン全体でインスタンスを分散させることにより、予定内の環境でも予定外の事態でもインスタンスの可用性が実現できます。
可用性ゾーン:Azureではこのコンセプトをプレビュー版として公開しており、リージョンごとに3つのゾーンサポートしています。今後は、これがElasticsearchをデプロイするベストな方法になるでしょう。ゾーンごとに、マスターノードになる可能性があるノード(または専用マスターノード)が1つある必要があり、データノードは、ゾーン全体に分散させ、Shard Allocation Awarenessを使用して適切にタグ付けする必要があります。
スケールセット:専用のElasticsearchマスターノード(上記参照)を使用する場合、スケールセットが、Elasticsearchデータノードを必要なときにスケールアップしたりスケールダウンしたりする方法として適しています。
バックアップ
Elasticsearchには、インデックスファイルを遠隔地のバックアップロケーションに送信するSnapshot Restore APIがあります。公式のAzure向けプラグインが利用でき、すべてのStandardストレージ アカウントをサポートしています
BeatsとLogstashを使用したデータ収集
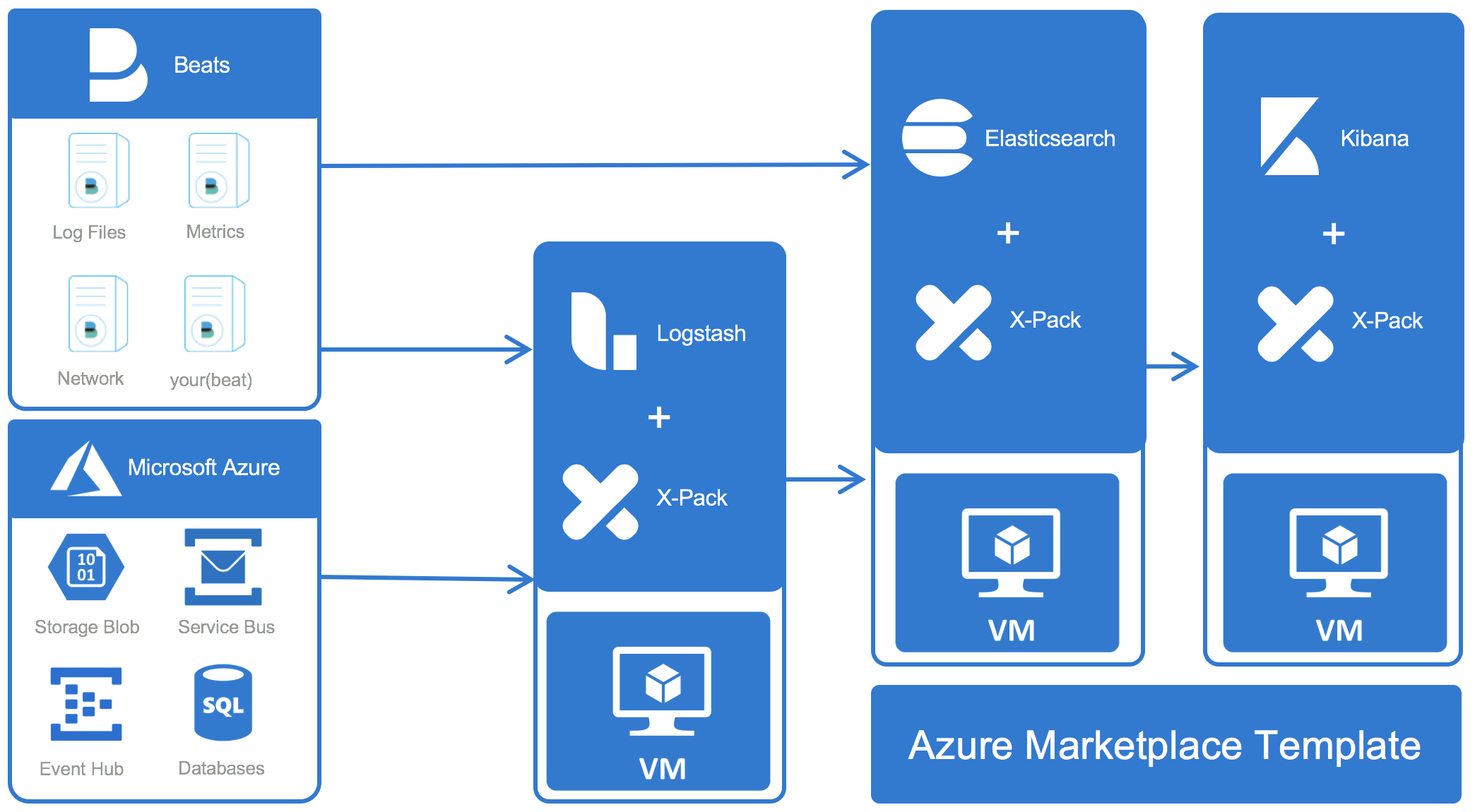
Beats
最近、Beatsは、収集するイベントデータにAzureメタデータ(instance_id、instance_name、machine_type、region)を付加するサポートを追加しました。
このため、ログファイルの追跡にFilebeatを使用しようと、システム指標としてMetricbeatを使用しようと、Linux監査ログ用に新規のAuditbeatを使用しようと、その他公式やコミュニティの数多くのBeatsを使用しようと、イベントが発生したマシンをいつでも把握することができます。
Logstash
ソースからデータを収集するBeatsとは対照的に、Logstashは、さらに処理を行うためにBeatsからデータを受け取ったり、中間システムからデータを取得したりするためによく使用されています。Azure専用に使用できるサードパーティ入力プラグインがたくさんあります。
Azure Event Hub:Event Hubパーティションからデータを読み込みます。
Azure Storage Blob:ストレージアカウント名、アクセスキー、コンテナー名を設定すると、コンテナーのコンテンツを読み込みます。
Azure Service Busトピック:Service Busトピックからメッセージを読み込みます。
まとめ
AzureにElasticsearchとElastic Stackをデプロイすることはすばらしい考え方です。本稿がこれらを活用する方法の一助となることを期待しています。結果を共有していただければ幸いです。