



Introducing Spark Structured Streaming Support in ES-Hadoop 6.0
Try this feature today. Download 6.0.0 preview release to become a Pioneer.
Spark Structured Streaming Support
Support for Spark Structured Streaming is coming to ES-Hadoop in 6.0.0
Last year (July 2016 to be exact) Spark 2.0.0 was released. With it came many new and interesting changes and improvements, but none as buzzworthy as the first look at Spark’s new Structured Streaming programming model. Initially released as an experimental feature, now one year later, it is considered GA in Spark 2.2.0. I am excited to announce that we will be supporting Structured Streaming as part of our native Spark integration!
What is Structured Streaming?
Structured Streaming is the a new stream processing model in Spark that combines the existing approach of executing in micro-batches with the same data transformation and optimization framework that users have come to love from the SparkSQL API’s. Structured Streaming’s programming model aims to fill the missing fourth quad of Spark API’s along RDDs, DStreams, and Datasets:
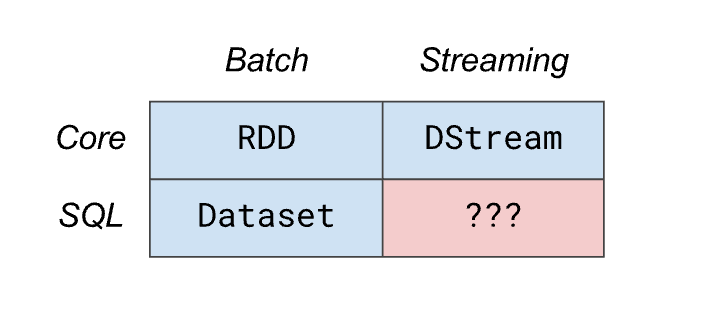
Structured Streaming leverages the same Dataset API from SparkSQL, allowing for the same operations (with a few reasonable limitations) to be executed on bounded (batch) or unbounded (streaming) data sources. The new programming model also advertises Exactly-Once Processing through usage of disk-based checkpointing of input offsets, commit logs, and idempotent data sinks.
Using SQL on a streaming data source introduces new patterns for performing aggregations. Structured Streaming provides a rich set of features for performing aggregations over sliding windows of time, allowing for groupings of data to be materialized as data flows in. It’s execution model stores long running aggregations in memory, so if you have event data that arrives late it will be appropriately handled. Users can provide watermarks that inform the framework to discard extremely late data if there is little chance of encountering data for that window ever again. All of these features together make Spark Structured Streaming an enticing streaming technology for Spark users.
Integrating with Elasticsearch
Available now in ES-Hadoop 6.0.0-beta1 is a Streaming Sink implementation that allows for sending data from a Structured Streaming job to an Elasticsearch cluster. This sink implementation is built with all the same features you have come to expect from the ES-Hadoop connector, like automatic connection failover between Elasticsearch nodes and dynamic multi-resource writes.
Under the hood
Hooking into Spark as an extension through the SQL DataSource api, ES-Hadoop offers up an implementation of the new Sink interface, allowing users to save a streaming Dataset to Elasticsearch. In order to uphold Structured Streaming’s exactly once processing semantics, we must make sure of the following:
- A previously committed batch should not be written (in the event that a batch is retried after a failure) and…
- The underlying datasource should support idempotent writes (in the event that a batch fails after partially writing its documents).
Users of ES-Hadoop can specify one of their fields to be used as the document’s ID, and Elasticsearch manages ID based writes consistently. We can’t know ahead of time what your documents’ IDs are, so it’s up to each user to ensure their streaming data contains an ID of some sort. With your help, we have requirement #2 satisfied, but what about requirement #1?
Spark Structured Streaming ships with some internal log classes that help us out here. ES-Hadoop extends an internal metadata log implementation that persists committed batch id’s to HDFS. We have provided a simple commit protocol for these batch IDs: If it does not already exist, then each batch ID is initialized in the driver, and sent to the workers. Each worker responds back to the driver with a result for the opened transaction. This result contains if the task succeeded or failed, as well as some simple statistics about the task. The driver collects these transaction results, and if they are all satisfactory, the batch ID is committed to HDFS as a file which contains the serialized transaction results.

You may be wondering where these logs are kept on the filesystem once you launch your job. Structured Streaming requires users to specify a checkpoint location when writing their streaming queries. ES-Hadoop scoops up whichever checkpoint configurations you chose to set and persists its commit log alongside the rest of Spark’s checkpoint data. As time carries on, these log files are bound to pile up. Luckily, Spark provides some helpful facilities for compacting these log files on HDFS.
ES-Hadoop’s out of box commit log configurations are sourced from default values and settings you’ve already provided to Spark. We’ve also exposed our own settings to override the sink’s behaviour in the event that you wish to have the two technologies configured differently. You can check out all the nifty switches and dials for configuring the commit log here, but trust us when we say that it doesn’t get much simpler than the defaults!
Watch the Sparks fly
The Spark Structured Streaming integration will be landing in version 6.0 of ES-Hadoop. The integration will support all Spark versions 2.2.0 and up. Why Spark 2.2.0? Structured Streaming has been marked as an experimental feature in Spark since its introduction and each release since then has seen backwards incompatible changes to the underlying framework. With Spark 2.2.0 now released, the framework’s underlying API’s should be far more stable moving forward. As such, Spark versions before 2.2.0 will not be supported for Structured Streaming. Alas, the sweet sting of early adoption.
Hey, speaking of early adoption: You can get a sneak peak of this new integration in our 6.0 pre-release builds for ES-Hadoop. In fact, if you would like, there’s tons of new stuff across the entire Elastic Stack that we’d love for you take for a spin. Try it all out and let us know of any woes or hiccups you may have experienced along the way. That could get you qualified for the Elastic Pioneer Program, and could win you some sweet perks. How’s that for watching the sparks fly?
Banner image credit: Wikipedia.
{kind=link}