데이터 시각화
edit데이터 시각화
edit데이터 시각화를 시작하려면 사이드 탐색 메뉴에서 시각화 를 클릭합니다.
시각화 툴을 사용하여 데이터를 다양한 방식으로 볼 수 있습니다. 예를 들어 훌륭한 시각화인 파이 차트를 사용하여 샘플 은행 계정 데이터의 계정 잔액을 살펴보겠습니다.
시작하려면 시각화 목록에서 파이 차트 를 클릭합니다. 저장된 검색에서 시각화를 작성하거나 새 검색 기준을 입력할 수 있습니다. 새 검색 기준을 입력하려면 먼저 색인 패턴을 선택하여 검색할 색인을 지정해야 합니다. 계정 데이터를 검색하기 위해 ba* 색인 패턴을 선택합니다.
기본 검색은 모든 문서에 대해 일치 여부를 비교합니다. 처음에는 하나의 "슬라이스"가 전체 파이를 포함합니다.
차트에 표시할 슬라이스를 지정하려면 Elasticsearch 버켓 집계를 사용합니다. 버킷 집계는 그저 검색 기준과 일치하는 문서를 여러 범주, 즉 _버킷_으로 분류합니다. 예를 들어 계정 데이터는 각 계정의 잔액을 포함하고 있습니다. 버킷 집계를 사용하여 계정 잔액의 범위를 여러 개 설정하고 각 범위에 얼마나 많은 계정이 해당되는지 확인할 수 있습니다.
각 범위에 대해 버킷을 정의하려면 다음을 수행합니다.
- 분할 슬라이스 버킷 유형을 클릭합니다.
- 집계 목록에서 범위 를 선택합니다.
- 필드 목록에서 잔액 필드를 선택합니다.
- 범위 추가 를 4번 클릭하여 총 6개의 범위가 되게 합니다.
-
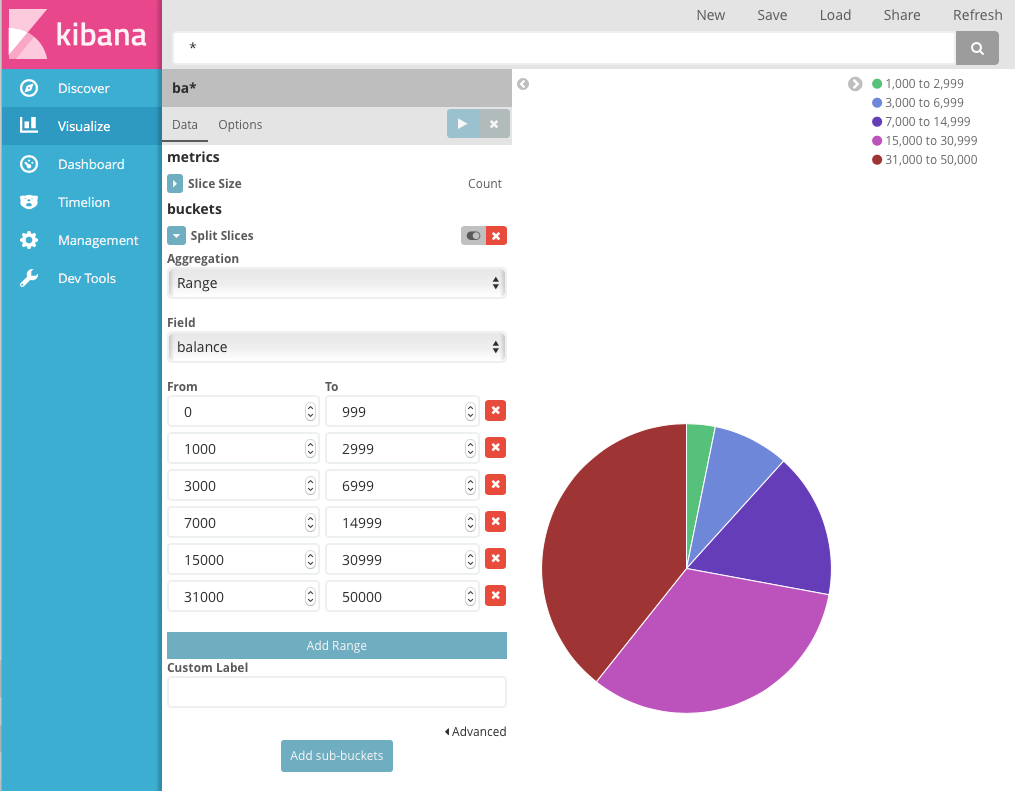
다음 범위를 정의합니다.
0 999 1000 2999 3000 6999 7000 14999 15000 30999 31000 50000
-
변경 사항 적용
 을 클릭하여 차트를 업데이트합니다.
을 클릭하여 차트를 업데이트합니다.
이제 1,000개 계정 중에서 각 잔액 범위에 속하는 계정의 비율을 확인할 수 있습니다.
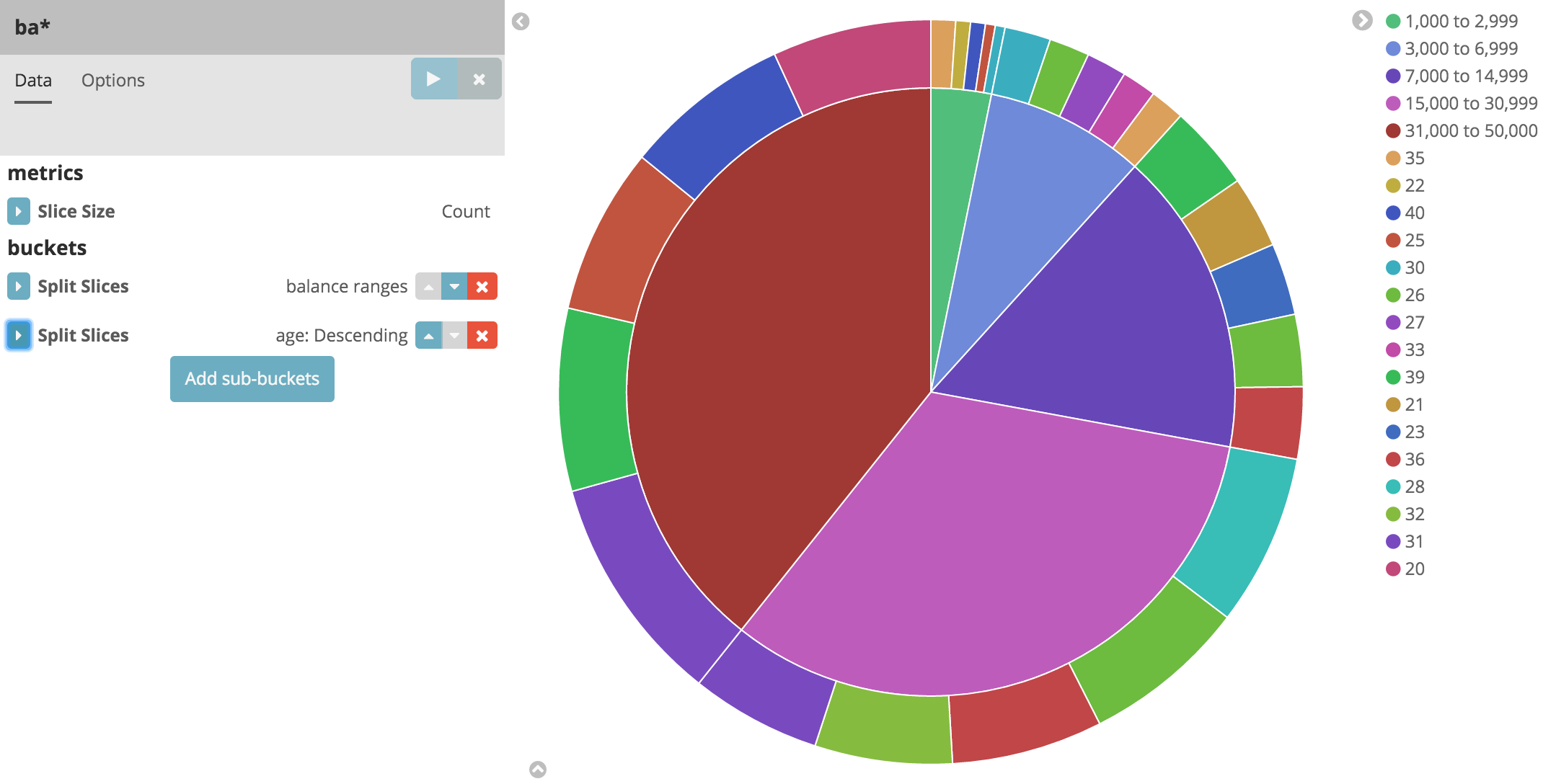
데이터의 또 다른 차원, 즉 계정 소유자의 나이를 살펴보겠습니다. 다른 버킷 집계를 추가하여 각 잔액 범위에 속하는 계정 소유자의 나이를 확인할 수 있습니다.
- 버킷 목록의 아래에서 하위 버킷 추가 를 클릭합니다.
- 버킷 유형 목록에서 분할 슬라이스 를 클릭합니다.
- 집계 목록에서 조건 을 선택합니다.
- 필드 목록에서 나이 를 선택합니다.
-
변경 사항 적용 을 클릭합니다.
이제 잔액 범위에 따라 링 모양으로 표시된 계정 소유자의 나이를 분류할 수 있습니다.
나중에 사용할 수 있도록 이 차트를 저장하려면 저장 을 클릭하고 파이 예시 의 이름을 입력합니다.
이제 Shakespeare 데이터 집합의 데이터를 볼 차례입니다. 희곡의 화자의 수를 비교하고 그 정보를 바 차트에 표시하는 방법을 알아보겠습니다.
- 새로 만들기 를 클릭하고 '세로 바 차트’를 선택합니다.
-
shakes*색인 패턴을 선택합니다. 아직 어떤 버킷도 정의하지 않았으므로 커다란 하나의 바가 나타나 기본 와일드카드 쿼리와 일치하는 총 문서 수를 표시합니다.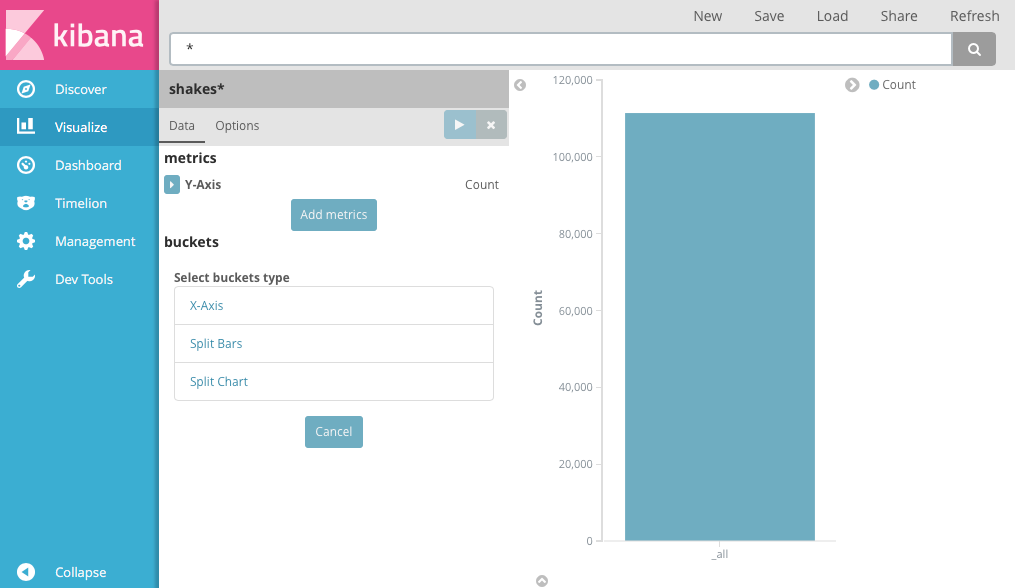
- Y축에 각 희곡의 화자의 수를 표시하려면 Y축메트릭 집계를 구성해야 합니다. 메트릭 집계는 검색 결과에서 추출된 값을 기준으로 메트릭을 계산합니다. 희곡당 화자의 수를 구하려면 고유 카운트 집계를 선택하고 필드 목록에서 speaker 필드를 선택합니다. 축에 맞춤형 레이블, _화자_를 지정할 수도 있습니다.
- X축을 따라 여러 희곡을 표시하려면 X축 버킷 유형을 선택하고 집계 목록에서 조건 집계를 선택한 다음 필드 목록에서 play_name 필드를 선택합니다. 알파벳순으로 나열하려면 오름차순 메뉴를 선택합니다. 축에 맞춤형 레이블, 희곡 이름 을 지정할 수도 있습니다.
-
변경 사항 적용 을 클릭하여 결과를 표시합니다.
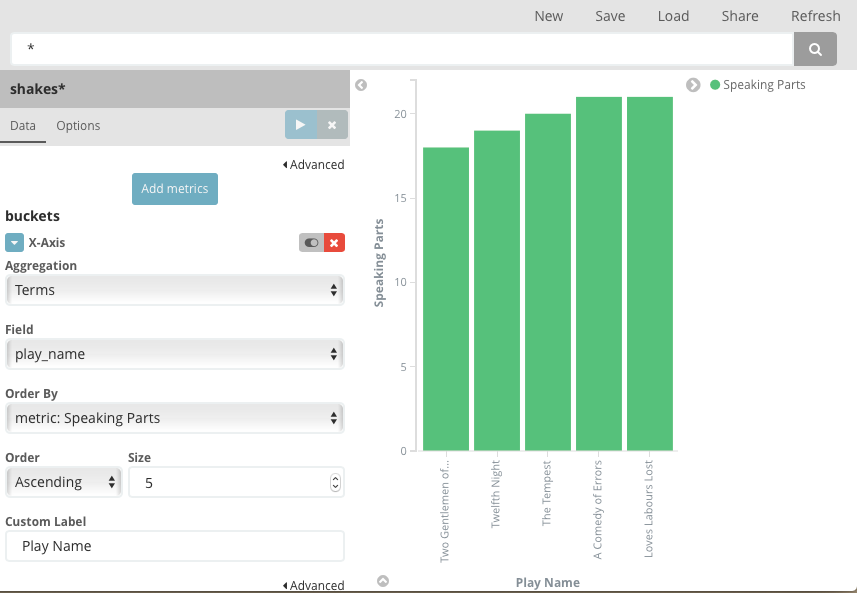
각 희곡 이름이 개별 단어로 나뉘지 않고 온전한 문구로 표시됩니다. 이는 튜토리얼을 시작할 때 수행한 맵핑 때문에, play_name 필드를 '분석 안 됨’으로 표시한 결과입니다.
각 바 위에 커서를 놓으면 각 희곡의 화자 수가 툴팁으로 표시됩니다. 툴팁을 끄고 시각화를 위한 다른 옵션을 구성하려면 시각화 빌더의 옵션 탭을 선택합니다.
이제 Shakespeare 희곡의 최소 출연자 목록이 있으므로 어떤 역할의 최대 대사 수를 표시하여 개별 배우에게 가장 많은 역량이 요구되는 작품을 확인하고 싶을 수도 있습니다.
- Y축 집계를 추가하기 위해 메트릭 추가 를 클릭합니다.
- 최대 집계를 선택하고 speech_number 필드를 선택합니다.
- 옵션 메뉴를 클릭하고 바 모드 옵션을 그룹화 로 변경합니다.
-
변경 사항 적용 을 클릭합니다. 다음과 같은 차트가 표시되어야 합니다.
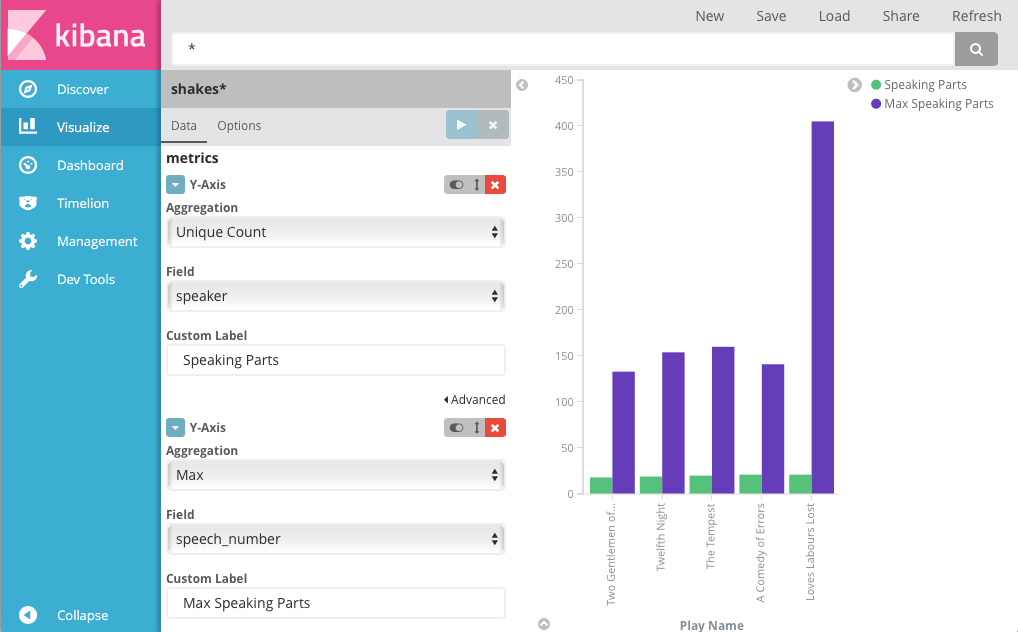
_Love’s Labours Lost_의 최대 대사 수가 다른 작품보다 훨씬 많으므로 배우의 기억력이 더 많이 요구된다고 볼 수 있습니다.
화자 수 Y축은 0에서 시작하지만 바는 18에 이르러서야 구별되기 시작합니다. 이 차이를 확실하게 드러내기 위해 Y축을 최소값과 더 가까운 값에서 시작하려면 옵션으로 이동하여 *Y축을 데이터 경계로 조정*을 선택합니다.
이 차트를 _바 예시_라는 이름으로 저장합니다.
이제 타일 맵 차트를 사용하여 로그 파일 샘플 데이터의 지리 정보를 시각화하겠습니다.
- 새로 만들기 를 클릭합니다.
- 타일 맵 을 선택합니다.
-
logstash-*색인 패턴을 선택합니다. - 탐색 중인 이벤트에 대한 시간 창을 설정합니다.
- Kibana 툴바에서 시간 선택기를 클릭합니다.
- 절대 를 클릭합니다.
-
시작 시간을 2015년 5월 18일로, 종료 시간을 2015년 5월 20일로 설정합니다.
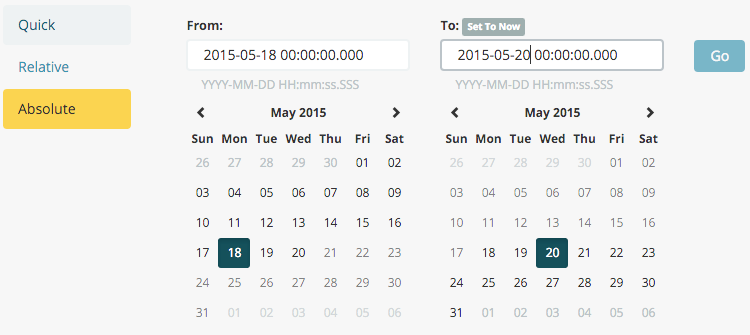
- 시간 범위를 설정한 다음 이동 단추를 클릭하고 오른쪽 아래의 작은 위쪽 화살표를 클릭하여 시간 선택기를 닫습니다.
아직 버킷을 정의하지 않았으므로 전 세계 맵이 표시됩니다.
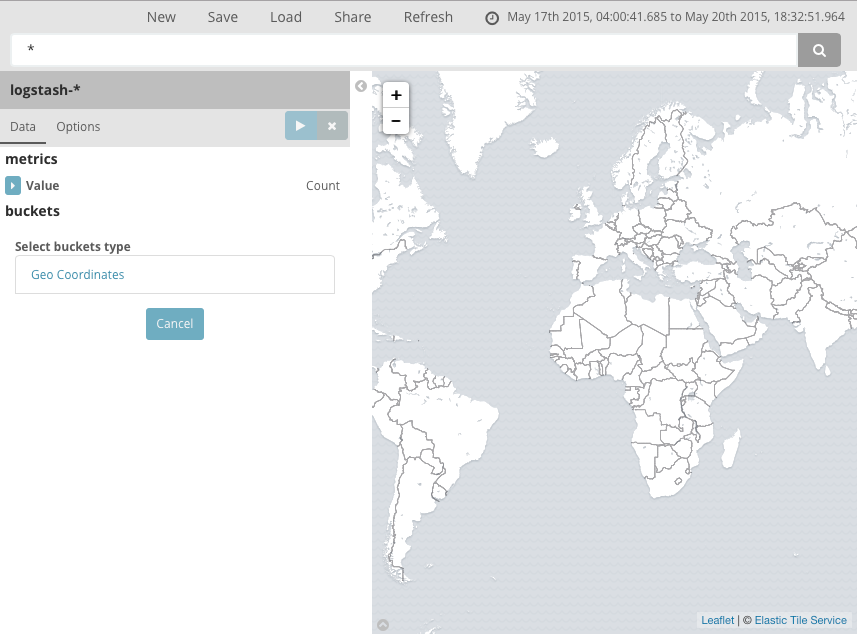
로그 파일의 지리 좌표를 맵핑하려면 지리 좌표 를 버킷으로 선택하고 변경 사항 적용 을 클릭합니다.
다음과 같은 차트가 표시되어야 합니다.
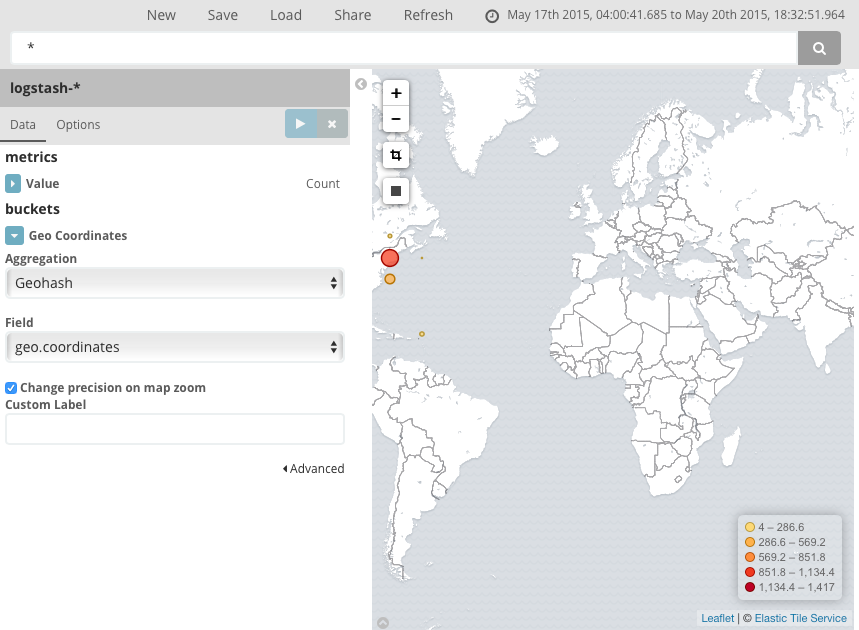
클릭하고 끌어 맵을 탐색하거나  단추로 확대하거나 데이터 경계 맞추기
단추로 확대하거나 데이터 경계 맞추기  단추를 눌러 모든 포인트를 포함하는 가장 낮은 레벨로 확대/축소할 수 있습니다. 또한 위도/경도 필터
단추를 눌러 모든 포인트를 포함하는 가장 낮은 레벨로 확대/축소할 수 있습니다. 또한 위도/경도 필터  단추를 클릭하고 맵에 경계 상자를 그리는 방법으로 직사각형 영역을 포함하거나 제외할 수도 있습니다. 적용된 필터는 쿼리 표시줄의 아래에 나타납니다. 필터 위에 커서를 놓으면 필터 전환, 고정, 도치, 삭제 컨트롤이 표시됩니다.
단추를 클릭하고 맵에 경계 상자를 그리는 방법으로 직사각형 영역을 포함하거나 제외할 수도 있습니다. 적용된 필터는 쿼리 표시줄의 아래에 나타납니다. 필터 위에 커서를 놓으면 필터 전환, 고정, 도치, 삭제 컨트롤이 표시됩니다.
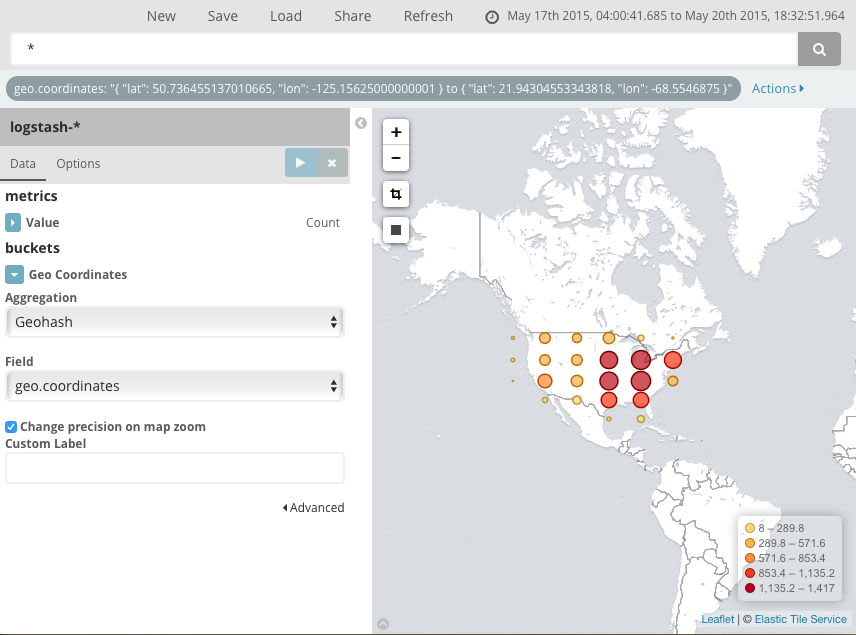
이 맵을 _맵 예시_라는 이름으로 저장합니다.
마지막으로 추가 정보를 표시하기 위해 마크다운 위젯을 생성합니다.
- 새로 만들기 를 클릭합니다.
- 마크다운 위젯 을 선택합니다.
-
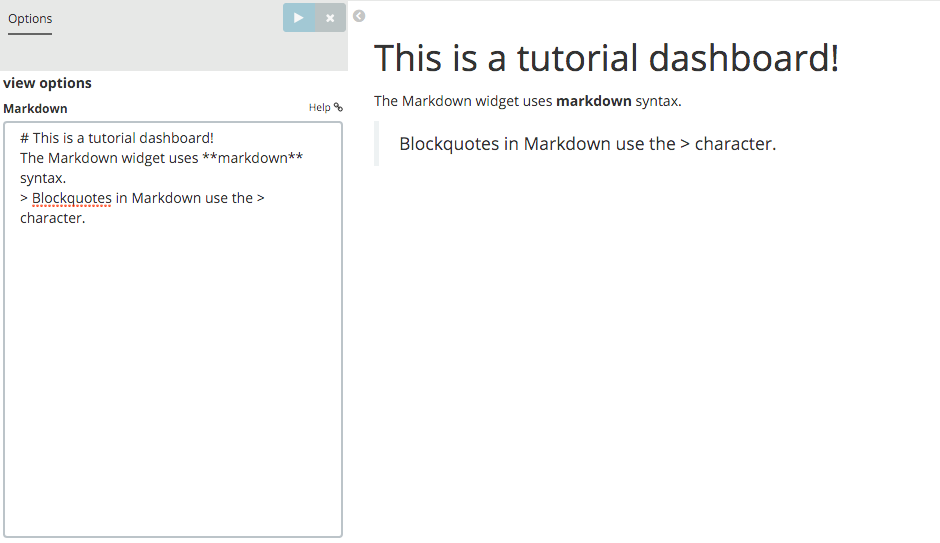
필드에 다음 텍스트를 입력합니다.
# This is a tutorial dashboard! The Markdown widget uses **markdown** syntax. > Blockquotes in Markdown use the > character.
-
미리보기 창에서 마크다운을 렌더링하기 위해 변경 사항 적용
을 클릭합니다.
이 시각화를 마크다운 예시 라는 이름으로 저장합니다.