Data streams
editData streams
editElastic Agent uses data streams to store time series data across multiple indices while giving you a single named resource for requests. Data streams are well-suited for logs, metrics, traces, and other continuously generated data. They offer a host of benefits over other indexing strategies:
- Reduced number of fields per index: Indices only need to store a specific subset of your data–meaning no more indices with hundreds of thousands of fields. This leads to better space efficiency and faster queries. As an added bonus, only relevant fields are shown in Discover.
- More granular data control: For example, filesystem, load, cpu, network, and process metrics are sent to different indices–each potentially with its own rollover, retention, and security permissions.
- Flexible: Use the custom namespace component to divide and organize data in a way that makes sense to your use case or company.
- Fewer ingest permissions required: Data ingestion only requires permissions to append data.
Data stream naming scheme
editElastic Agent uses the Elastic data stream naming scheme to name data streams. The naming scheme splits data into different streams based on the following components:
-
type -
A generic
typedescribing the data, such aslogs,metrics,traces, orsynthetics. -
dataset -
The
datasetis defined by the integration and describes the ingested data and its structure for each index. For example, you might have a dataset for process metrics with a field describing whether the process is running or not, and another dataset for disk I/O metrics with a field describing the number of bytes read. -
namespace -
A user-configurable arbitrary grouping, such as an environment (
dev,prod, orqa), a team, or a strategic business unit. Anamespacecan be up to 100 bytes in length (multibyte characters will count toward this limit faster). Using a namespace makes it easier to search the data from a given source by using index patterns, or to give users permissions to data by assigning an index pattern to user roles.
The naming scheme separates each components with a - character:
<type>-<dataset>-<namespace>
For example, if you’ve set up the Nginx integration with a namespace of prod,
Elastic Agent uses the logs type, nginx.access dataset, and prod namespace to store data in the following data stream:
logs-nginx.access-prod
Alternatively, if you use the APM integration with a namespace of dev,
Elastic Agent stores data in the following data stream:
traces-apm-dev
All data streams, and the pre-built dashboards that they ship with, are viewable on the Fleet Data Streams page:
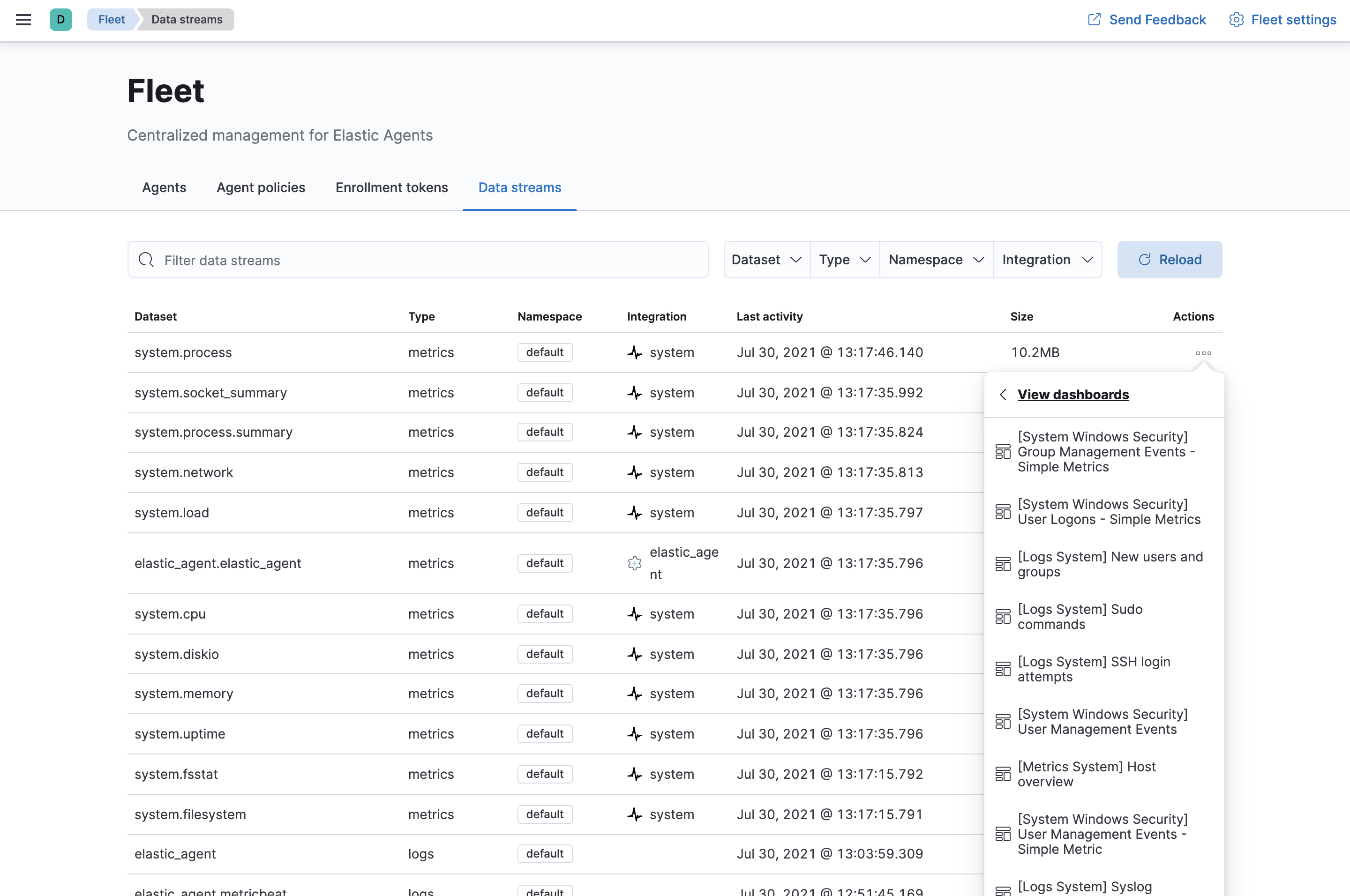
If you’re familiar with the concept of indices, you can think of each data stream as a separate index in Elasticsearch. Under the hood though, things are a bit more complex. All of the juicy details are available in Elasticsearch Data streams.
Index patterns
editWhen searching your data in Kibana, you can use an index pattern to search across all or some of your data streams.
Index templates
editAn index template is a way to tell Elasticsearch how to configure an index when it is created. For data streams, the index template configures the stream’s backing indices as they are created.
Elasticsearch provides the following built-in, ECS based templates: logs-*-*, metrics-*-*, and synthetics-*-*.
Elastic Agent integrations can also provide dataset-specific index templates, like logs-nginx.access-*.
These templates are loaded when the integration is installed, and are used to configure the integration’s data streams.
Configure an index lifecycle management (ILM) policy
editUse the index lifecycle management (ILM) feature in Elasticsearch to manage your Elastic Agent data stream indices as they age. For example, create a new index after a certain period of time, or delete stale indices to enforce data retention standards.
Elastic Agent uses ILM policies built-in to Elasticsearch to manage backing indices for its data streams. See the Customize built-in ILM policies tutorial to learn how to customize these policies based on your performance, resilience, and retention requirements.
To instead create a new ILM policy, in Kibana, go to Stack Management > Index Lifecycle Policies. Click Create policy. Define data tiers for your data, and any associated actions, like a rollover, freeze, or shrink. See configure a lifecycle policy for more information.