Extract, filter, and transform content
editExtract, filter, and transform contentedit
Elastic connectors offer a number of tools for extracting, filtering, and transforming content from your third-party data sources. Each connector has its own default logic, specific to the data source, and every Elastic Search deployment uses a default ingest pipeline to extract and transform data. Several tools are also available for more advanced use cases.
The following diagram provides an overview of how content extraction, sync rules, and ingest pipelines can be orchestrated in your connector’s data pipeline.
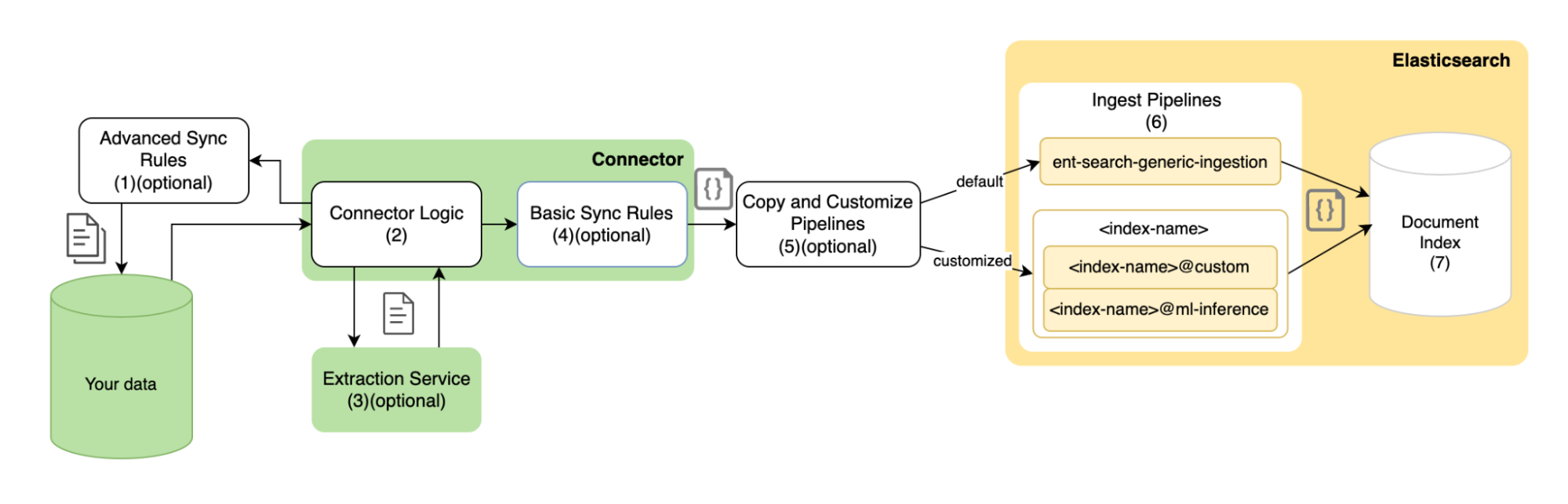
By default, only the connector specific logic (2) and the default ent-search-generic-ingestion pipeline (6) extract and transform your data, as configured in your deployment.
The following tools are available for more advanced use cases:
- Advanced sync rules (1). Remote filtering at the data source level, before data reaches the connector.
- Basic sync rules (4) or extraction service (3). Integration filtering controlled by the connector.
- Ingest pipelines (6). Customized pipeline filtering where Elasticsearch filters data before indexing.
Learn more in the following documentation links.
Content extractionedit
Connectors have a default content extraction service, plus the self-hosted extraction service for advanced use cases.
Refer to Content extraction for details.
Sync rulesedit
Use sync rules to help control which documents are synced between the third-party data source and Elasticsearch. Sync rules enable you to filter data early in the data pipeline, which is more efficient and secure.
- Basic sync rules are identical for all connectors.
- Advanced sync rules are data source-specific. They cover complex query-and-filter scenarios, defined in a DSL JSON snippet.
Refer to Sync rules for details.
Ingest pipelinesedit
Ingest pipelines are a user-defined sequence of processors that modify documents before they are indexed into Elasticsearch. Use ingest pipelines for data enrichment, normalization, and more.
Elastic connectors use a default ingest pipeline, which you can copy and customize to meet your needs.
Refer to ingest pipelines in Search in the Elasticsearch documentation.