WARNING: The 2.x versions of Elasticsearch have passed their EOL dates. If you are running a 2.x version, we strongly advise you to upgrade.
This documentation is no longer maintained and may be removed. For the latest information, see the current Elasticsearch documentation.
Multidocument Patternsedit
The patterns for the mget and bulk APIs are similar to those for
individual documents. The difference is that the coordinating node knows in
which shard each document lives. It breaks up the multidocument request into
a multidocument request per shard, and forwards these in parallel to each
participating node.
Once it receives answers from each node, it collates their responses
into a single response, which it returns to the client, as shown in Figure 12, “Retrieving multiple documents with mget”.
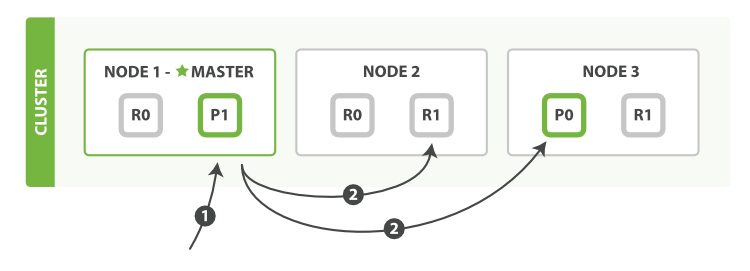
mgetHere is the sequence of steps necessary to retrieve multiple documents
with a single mget request:
-
The client sends an
mgetrequest toNode 1. -
Node 1builds a multi-get request per shard, and forwards these requests in parallel to the nodes hosting each required primary or replica shard. Once all replies have been received,Node 1builds the response and returns it to the client.
A routing parameter can be set for each document in the docs array.
The bulk API, as depicted in Figure 13, “Multiple document changes with bulk”, allows the execution of multiple create, index, delete, and update requests within a single bulk request.
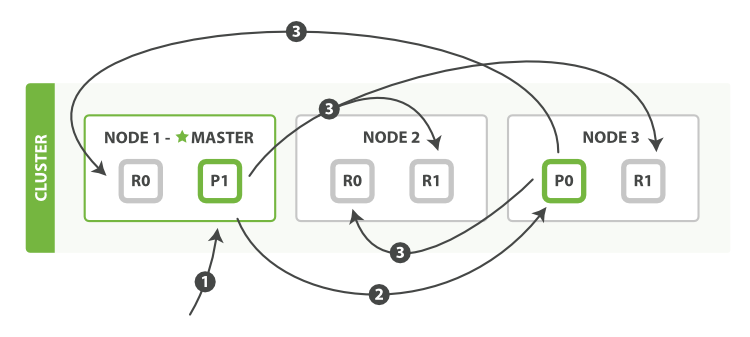
bulkThe sequence of steps followed by the
bulk API are as follows:
-
The client sends a
bulkrequest toNode 1. -
Node 1builds a bulk request per shard, and forwards these requests in parallel to the nodes hosting each involved primary shard. - The primary shard executes each action serially, one after another. As each action succeeds, the primary forwards the new document (or deletion) to its replica shards in parallel, and then moves on to the next action. Once all replica shards report success for all actions, the node reports success to the coordinating node, which collates the responses and returns them to the client.
The bulk API also accepts the consistency parameter
at the top level for the whole bulk request, and the routing parameter
in the metadata for each request.
Why the Funny Format?edit
When we learned about bulk requests earlier in Cheaper in Bulk, you may have asked
yourself, “Why does the bulk API require the funny format with the newline
characters, instead of just sending the requests wrapped in a JSON array, like
the mget API?”
To answer this, we need to explain a little background: Each document referenced in a bulk request may belong to a different primary
shard, each of which may be allocated to any of the nodes in the cluster. This
means that every action inside a bulk request needs to be forwarded to the
correct shard on the correct node.
If the individual requests were wrapped up in a JSON array, that would mean that we would need to do the following:
- Parse the JSON into an array (including the document data, which can be very large)
- Look at each request to determine which shard it should go to
- Create an array of requests for each shard
- Serialize these arrays into the internal transport format
- Send the requests to each shard
It would work, but would need a lot of RAM to hold copies of essentially the same data, and would create many more data structures that the Java Virtual Machine (JVM) would have to spend time garbage collecting.
Instead, Elasticsearch reaches up into the networking buffer, where the raw
request has been received, and reads the data directly. It uses the newline
characters to identify and parse just the small action/metadata lines in
order to decide which shard should handle each request.
These raw requests are forwarded directly to the correct shard. There is no redundant copying of data, no wasted data structures. The entire request process is handled in the smallest amount of memory possible.