



Using Molly to Model and Test Data Replication in Elasticsearch
Distributed systems and concurrency are known hard computer science problems. Put the two together and you get something that is extremely hard for us mere humans to reason about. It is often the case that a small, innocent looking, change can lead to violation of important assumptions. To that effect, both academia and industry have been hard at work to develop tools to validate ongoing work. Academia typically looks at new algorithm design and industry at adapting those algorithms to specific use cases.
At Elasticsearch, we use a pragmatic approach. At every given moment our CI infrastructure puts our code through a series of randomized set of chaos-monkey style simulated failures and validates that nothing goes wrong. While this approach is working tremendously well, we were looking to complement it with formal testing as well. To that end, a tweet by Peter Alvaro caught our attention. Peter, the head of a distributed systems research group at UC Santa Cruz, was looking for a collaboration on just that subject. After a short exchange of tweets and a few follow up calls, it was decided that Kamala — a PhD student in the group — would join the team at Elastic for a few months. During this time Kamala worked on modeling Elasticsearch's data replication logic. Sadly, that time is over, but Kamala has gracefully agreed to write a blog post about her adventure with us.
Note: Kamala worked on a future and yet unreleased version of our data replication logic. This algorithm is slated to ship in Elasticsearch 6.0. — Boaz Leskes
This past summer, I collaborated with Elastic to model the data replication protocol of Elasticsearch. Data replication is the logic responsible for indexing documents into all copies of a shard and is an important part of the system. It needs to be both correct and efficient, which are generally opposing requirements. My goal was to determine if there were any scenarios in which Elasticsearch's data replication could be driven to an inconsistent state and to use counterexamples found to refine the next version modeled, thereby gaining confidence as I moved forward. As I made progress, there were some nice insights to be had.
Elasticsearch's data replication protocol is a variant of primary-backup. In the primary-backup model, all client requests are routed to the primary replica which in turn acknowledges the request after it has been replicated on all the backups. The basic write setup involves all writes being re-routed to the primary, followed by a replication step. The primary sends the request out to all replicas, which log the request and then acknowledge the primary. Once the primary has received acknowledgements from all replicas, it acknowledges the sender from which the request was received. The acknowledgements retrace the path of the forwarded request until it reaches the client. In practice, multiple concurrent requests can be in flight. This has implications for operational behavior influencing the results from stale reads, reads after writes, and so forth.
Assumptions
Indexing in Elasticsearch is highly concurrent, making it interesting from a modeling perspective. Since the Elasticsearch APIs guarantee focus around a single document, we modeled a single document with concurrent accesses, rather than multiple independent documents (as would exist in actuality). For simplicity, we focused on an Elasticsearch cluster with one primary shard and two replicas. We also assume that there exists a master oracle that is fully aware of the state of other processes and is not a typical process in that sense. This master oracle is internally a group of servers, amongst which a consensus protocol is run, but we ignore this for our purposes and treat the externally visible actions of the master oracle as input data. Each message is sent exactly once.
Framework used
I specified the protocol in the Dedalus language, a relational language which is a superset of Datalog. Protocol state is represented as records in tables, and computation is represented as queries or "rules" describing the relationships among records. The rules and facts are used to derive new facts, which can be understood as the flow of data amongst the components. Pre and post conditions are used to specify the global invariants that must hold at the end of a execution. These typically represent some form of correctness and/or durability guarantees.
For example:
1. nodeid("a", 1)@1;
2. nodeid(Node, Nodeid)@next :- nodeid(Node, Nodeid);
Statement (1) indicates that an entry (a,1) is created in the table "nodeid" for the first time at time 1 and (2) indicates that the entry is maintained in the table at every timestep thereafter.
Similarly,
pre(X) :- log(Node, X), member(Node, Node); post(X) :- log(Node, X), notin missing(X); missing(X) :- log(Node, X), member(Node, Node), member(Node, Other), notin log(Other, X);
The pre statement says If a log exists on a node with a payload X, the post statement asserts that such a log must exist in every other node. The fact that the log must exist on every other node is encoded by the statements:
member(Node, Other): where Other is a node known to Node
log(Other, X): The log is present on the node Other
missing(X): A utility rule to indicate that the log is present in Node but there exists a node Other which doesn't have it.
The implicit assumption here is that every node knows of every other node in the system. This is an example of a consistency invariant.
For each given input, the model is executed. An execution produces a lineage, i.e. an explanation of how the invariants are satisfied in terms of the computation, data and messages that contributed to the outcome. This is then fed to a solver, which returns a set of fault scenarios (a set of possible events which may possibly cause an invariant violation). Each of these scenarios are tested and either a bug is discovered, or the system is declared correct subject to the assumptions made.
System invariants
System invariants specify the expected behavior of the system and can be used to determine whether a run of a model produced the correct output or not. We have two main invariants:
Durability:
To be considered durable, all writes acknowledged to the clients must be present on all active replicas. Note that we say active replicas. If a shard copy crashes, the cluster will continue to accept reads and writes without it. In the meantime, a new copy will be built in the background in a process called recovery. Shard recovery was not a part of project scope and is not modeled. We also do not consider a complete failure of all shards as violating this invariant.
Consistency:
In addition to all acknowledged writes, the consistency requirement is that all the active replicas agree on the contents of the documents at the end of the execution. In particular, there may be unacknowledged writes to the document and while these do not affect the durability invariant, for the consistency invariant to be satisfied all the active shard copies must agree on the contents an ID of the document. We will describe how this ID is derived for each of the versions in more detail as we go along.
Methodology
We used a fault injection framework called Molly to run through different fault scenarios and determine either that a counterexample has been discovered or that the system is correct subject to the assumptions made. Molly works by taking a specification and input data, and then produces all possible configurations for which the system does not behave predictably.
Instead of writing a complete specification from the get-go, I opted to start small and model only the core of the algorithm. Of course, the incomplete design meant that there will be scenarios where the system misbehaves and our invariants will fail. However, since we explicitly omitted pieces of the algorithm, I could anticipate those failure modes. Having Molly find these failures reassured us that I modeled things correctly so far and also verified our understanding of system behavior. This resulted in four versions of the protocol over time — ranging from simple to complex.
This approach to modeling the system can also be viewed as an approach to protocol design, or what is more commonly known as Test Driven Development. Verification is usually thought of as a task performed when significant functionality has been completed, to verify the end-to-end properties. It is true that the end-to-end properties of the system only hold on integration of a certain number of basic components. However, my experience over the summer has been that taking the time to define smaller coherent pieces and their expected behavior can offer a iterative approach to design. The benefits are twofold:
- We gain some confidence in the correctness of the specification. Especially in the the initial versions of any system, since we would be implementing the most basic version of the protocol, violations of invariants are particularly easy to achieve.
- The violations seen serve as signposts in guiding us to the next iteration of the protocol and help in defining how it is to be extended. Typically, the net iteration is the fix to the violation seen in the previous version.
The basic setup is that any write from a client is forwarded to the primary, which then forwards the request to every other replica in a replication step. On receiving a write from the primary, the corresponding slot in the replica's log is filled with details from the write. The replica acknowledges the write to the primary, which then retraces the request path until the client is acknowledged.
One-Write Consistency Failure:
As a strawman, I wanted to have a basic version of the data replication up and running. We had a single write and failure was observed when the write was replicated to one of the replicas but not to the other before the primary crashed. At the end of the execution, the write was not acknowledged to the client. Therefore, the durability invariant was not violated but since the write goes through to one replica but not the other, the consistency invariant is violated. A visualization of this scenario can be seen below (n1,n2 & n3 represent three nodes in the cluster, C is a client submitting requests):
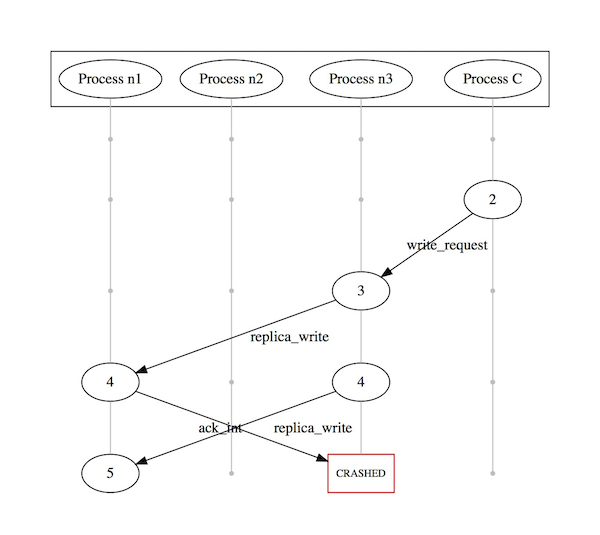
The points in the above diagram along each line represent virtual time, starting from time 1 and increasing as we move further down along the line. Inconsistencies can arise when the primary fails after a write request is sent to one replica but not the other. Re-sync is a procedure which is undertaken to ensure that the documents are consistent across all replicas when a primary failover occurs and a new replica takes over as primary. When a new node becomes a primary it replays all writes to the other replicas and sends a message indicating that all other slots in the logs be cleared beyond those corresponding to the messages sent. This fixes the problem of inconsistencies, but could potentially involve replay of a very large number of messages each time a primary failover occurs.
Two-Write Consistency Failure:
In the one-write version, the invariants were very basic. The consistency failure essentially checked for the presence of a write on any active replica and if found, it required that a write be present on all other active replicas as well. In the next step, we introduced two writes to the system and modified the consistency invariant to check that the ID of the last write in the log is equal on all active replicas. Previously, since there was only a single write, the consistency check was simply that if a write was seen at one replica, it was seen at all replicas. With the introduction of multiple writes, we now need to check that the same write was seen last at all replicas.
I ran the specification of our protocol with and without the fix made in the previous version. With the fix, the new primary replayed all writes and trimmed logs of all other replicas after the last write on the new primary. The system behaved correctly with the fix but without it we hit a similar bug as in the one-write scenario. An example run is given below (this time we added a process M, representing the master node).
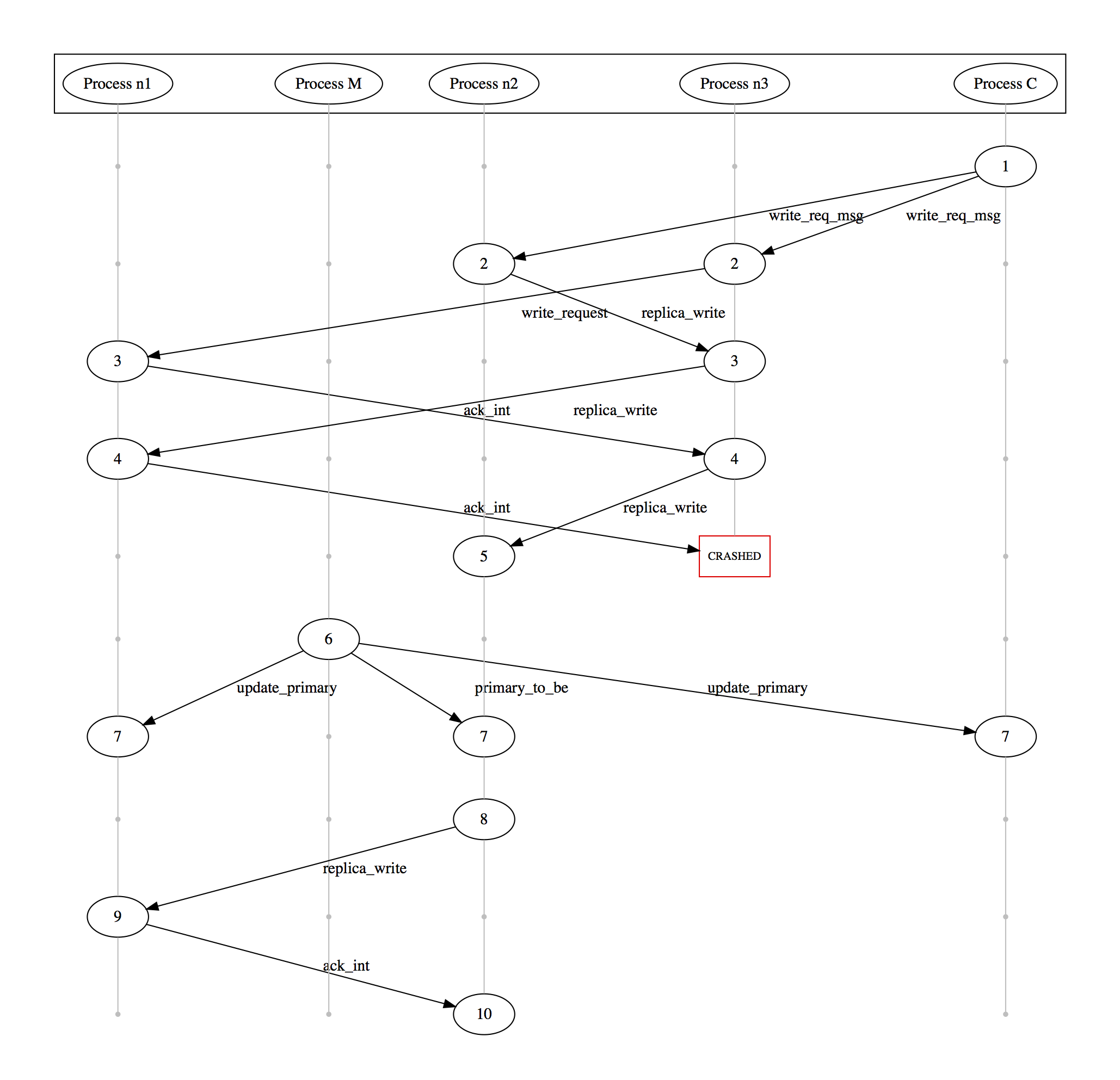
Same Sequence, Different Payload:
In the previous two versions, I have implemented the invariants as well as a model of the basic operation of the system. This included single as well multiple writes. I found a violation of the consistency invariant which was fixed with replaying all acknowledged writes and forcing all unfilled slots in the new primary with null values in all the backup replicas. This gives us confidence that what we have working is now, at the very least, a reasonable approximation of the actual system.
On receiving a write request, the primary assigns each request with a unique number which is incremented with each assignment. These are called sequence numbers and are useful to allow replicas to determine ordering amongst concurrent requests. A key aspect is that sequence numbers are locally picked at the primary, i.e. the primary decides the ordering of concurrent requests and locally generates sequence numbers. An optimization made is that when a write with a particular sequence number exists in the logs, receiving another write request with the same sequence number causes the payload to be dropped. In the above scenario, when the new primary processes a write request, the payload is dropped and while the replicas agree on sequence number, their payloads differ.
What happens if the primary crashes after a write with a specific sequence number reaches one replica but not the other and the replica that has not received the write becomes the primary? A violation based on this exact scenario is presented in the figure below (corresponding code can be found here).
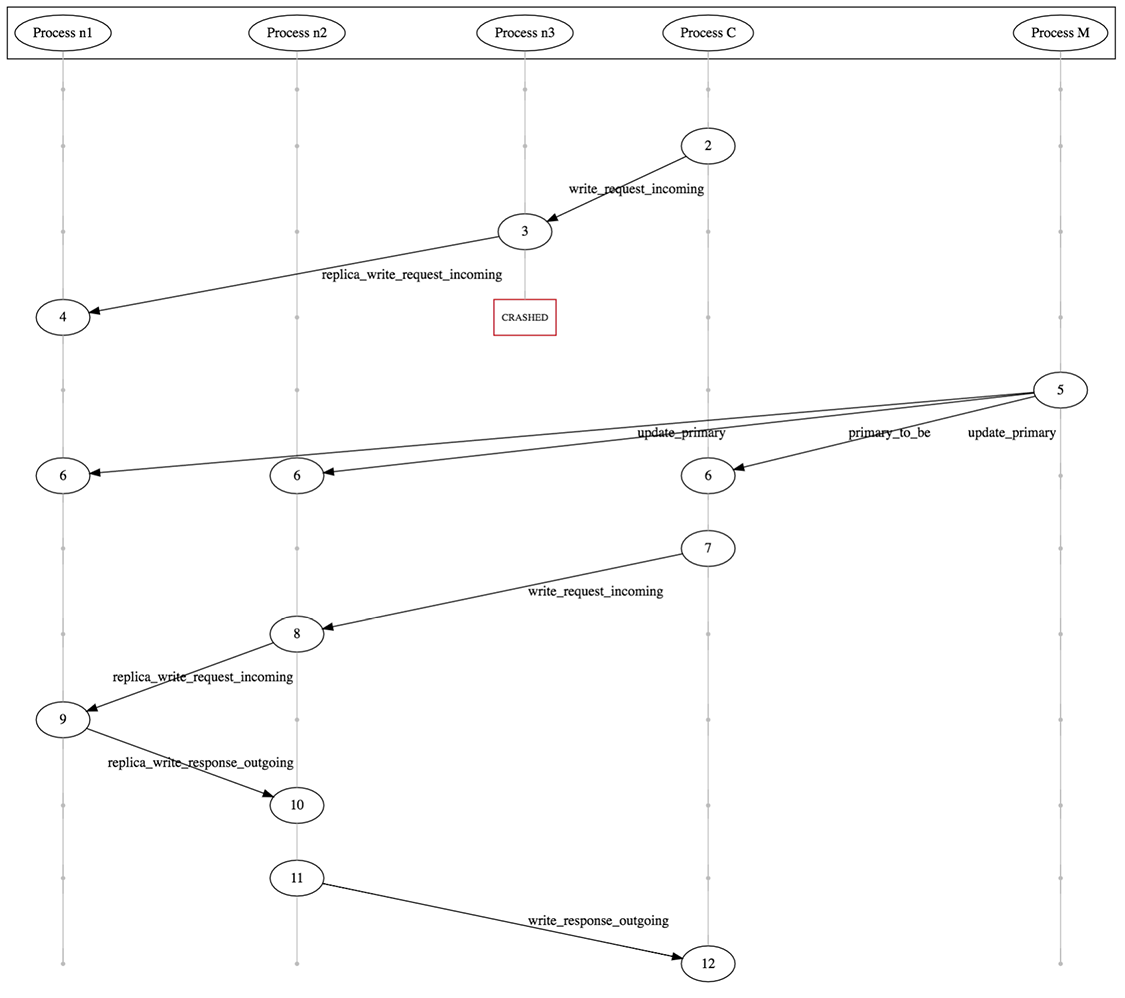
Up and Away
In order to fix the problem shown above (Same Sequence, Different Payload), the notion of term number is introduced. The idea is that the term number is updated for each primary change. A write request with a higher term number causes an overwrite even if the corresponding sequence number exists in the logs. With the introduction of term number, we found that the bug depicted in the figure above was fixed.
Currently, on a primary failover, the new primary replays all of its acknowledged writes. In practice, doing so can be prohibitively expensive. To flesh out the protocol completely, we are working on implementing local and global checkpoints, which provide some notion of how far back it is safe to roll back without replay. These can be thought of as optimizations to replaying the entire history.
Conclusion
My technique of modeling Elasticsearch's data replication protocol was to model only the core of the algorithm and as violations were discovered, to refine the implementation until the model was as close to the real protocol as possible. I found that the final version of our model is robust and has no counterexamples, given that we are considering deterministic runs of the protocol in which processes may crash but message drops are not considered part of the failure profile. I also did not model the node failure and re-joining as part of this project.
In addition, there were several insights to be had. Firstly, our modeling depicts the fact that Test Driven development(TDD) is a way of organically building a system while gaining confidence that the system built so far is correct. The discovery of anticipated issues in partially developed systems is a source of reassurance.
Secondly, in the first two versions modeled, the underlying bug is the same. This is not easy to see as we go from a simple to more complex version of the protocol. Identifying duplicate bugs is an area of future work. In our final version, a primary failover triggers replay of all acknowledged writes on the new primary to the replicas in the system, which could potentially be a very large number of messages. The Elasticsearch algorithm has provisions for a more efficient history sync, which was modeled in follow-up work that can be found here.
From my experience of modeling a real system that is larger than ever before in Dedalus, the specification language used in Molly, we came away with a wish list of improvements to Molly itself. Some of these include being able to interact with the visualizations and stricter checking at compile time.
And that folks is how I spent my summer!!