



How Skroutz uses Elasticsearch to gather insights on user behaviour
Introduction
![]()
Skroutz.gr is a Greek price comparison website that enables its users to filter through a variety of more than 7.5 million products in more than 1.5 thousand shops. The site has been in business for almost 10 years and, in the process, has spinned off a sister site in Turkey, Alve.com. Skroutz will expand into the UK market in the near future with the Scrooge.co.uk site.
Let's analyse user behaviour
Being one of the top-3 sites in Greece, and with monthly traffic of more than 12 million visits from more than 4 million unique visitors, it is only natural that we would like to learn something about the way our visitors use our platform. Which product categories or product category families (e.g. “Technology") are the most popular? How does time of the season affect each product categories' popularity? Which are our users' most favourite products? Which are the top products of any category right now or a year ago? The most popular shops? Can we drill-down into these results to find the most popular product in a particular shop last summer?
From another point of view, maybe we would like to gain some insights about how well our search engine is working. For example, which are the most popular searches on our platform and which are the most popular searches in any specific category? We could also try to identify problematic searches by examining those that return zero results, such as which zero-result query is used most often by our users? Is our search engine performing well? Do our users find what they look for in the first results page, or do they paginate endlessly? How much do they use our search filters?
We could obviously go on, but at this point it should be painfully obvious that insights of this kind are of great value and can play a crucial role in the short and long-term development of our product.
The old approach
Certainly, all of the above didn't come to us as some kind of epiphany. Lots and lots of work had been done previously to make sense of the mountains of logs that we keep amassing. With the danger of oversimplifying, we can describe the previous approach as a set of task-specific Ruby scripts that would run in regular intervals, then process the most recent logs and persist the results inside time-stamped MongoDB documents. The results of these computations were presented to users in custom dashboards using libraries such as high charts.
Much thought was also put into creating the logs that we use as input. These are text files with lines in JSON format that record the subset of the website activity that is of interest to us. Each line corresponds to a specific user action and contains information such as the type of that action (e.g. “product view", “search", or “browsing"), a timestamp, the exact URI and also action-specific fields such as category or product ID, search query etc.
Unfortunately, our approach had its limitations. Creating a new dashboard required a lot of effort because many layers of the system would have to be touched.Usually, the MongoDB collections required a new schema so that query performance would be acceptable, which in turn meant altering existing scripts or creating new ones to convert the input to the required state. This process translated into time spent on designing, implementing and testing those scripts and also beefing up our MongoDB servers so they could handle the increased workload.
Years of repeating the above process whenever a need for a new dashboard arose had left us with a system that was unmaintainable and of debatable value. Sure, it did the number crunching correctly, but the actual presentation of the data was subpar, with the information hidden inside huge tables and dense plots. Any requested change could only be performed by the very few developers that were familiar with the systems inner workings, and even they found the task daunting.
All in all, we used to spend more time developing the platform than analysing the data it presented. Things like on-demand dashboards, interactive filtering and ad-hoc queries with acceptable response time looked like a far-fetched dream. The old way had served us well enough until then, but it was obvious that we had to approach our internal analytics platform differently.
ELK stack to the rescue
We were already happy Elasticsearch users here at Skroutz. We depend on it for our search engine functionality and have invested time into creating plugins for NLP tasks like stemmers for the Turkish language.
We have followed the evolution of Elasticsearch from a search-specific platform to one whose power can also be leveraged for analytics. The success stories of companies using Elasticsearch for analytics (such as the Guardian or Thomson Reuters) also played a part in making us want to investigate and experiment with it.
What we found was that the aggregations functionality added in version 1.0.0 was a huge boost over facets, and support for scripted aggregations in version 1.4 also meant that we could use more complex calculations inside our queries. However, there are two features of Elasticsearch that we consider the most important: the fact that every field is indexed means we can perform ad-hoc queries without performance loss, and the improvements on doc value performance in version 1.4 mean that our computations will not be heavily memory-dependent.
Another attractive aspect was that Elasticsearch can work seamlessly with two other tools, Logstash (for log monitoring and parsing) and Kibana (for data visualization) - all three comprising what is known as the ELK stack. The ELK stack offers a complete solution that can take our log files, crunch them, and enable us to create beautiful, interactive and real-time dashboards with minimal fuss. The fact that we could just throw a couple of our log files into ELK and quickly experiment with it, then judge whether it suited our needs also played a huge part in us making up our minds.
We decided to spend a few days experimenting with it. Setting up a simple ELK installation on a virtual machine was a breeze using the provided Debian packages. We then took a few days worth of logs, pointed Logstash to their location and let it import their contents into Elasticsearch. After that, it was only a matter of waiting for the import to finish and opening Kibana inside our browsers to validate that our intuition about ELK was correct: we could visualize, aggregate and analyze our logs on demand, going into as much detail as we wanted.
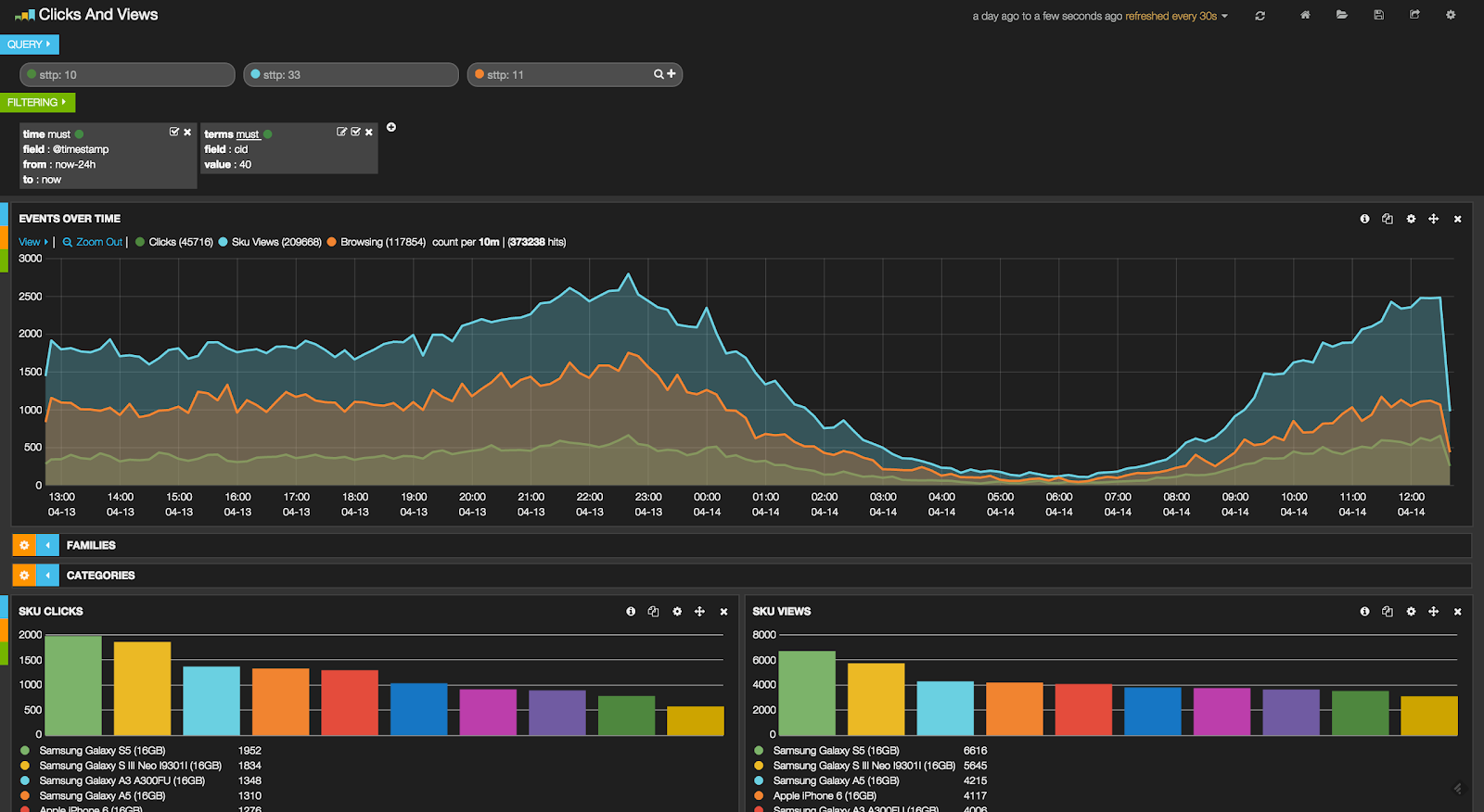
Implementation details
After deciding on using the ELK stack for our internal analytics platform, we spent a couple of weeks writing down in detail all of its requirements, creating user stories for the dashboards and planning our developing strategy. During that process we realised we would need to log some new fields so we altered our application's code accordingly.
For our infrastructure we decided that we would use two nodes each having 8 cores, 32GB of RAM one 50GB SSD and two 600GB spinning disks, to handle our daily stream of about four million events. We would experiment with importing only new logs and after being satisfied with the cluster's stability we would import a year's worth of backlogs. We would also set up Curator to move older indexes into spinning disks so newer ones would stay on the SSDs.
We already had UDP multicast emission of our logs set up in our network, so we wrote a simple program that would join that multicast group and write to a file that would be monitored by Logstash.
We also needed to create custom mappings for our Elasticsearch documents. We took care to specify all the field types correctly, set their format to “doc_values", and to set all string field (apart from that holding the search queries) indexes to “not_analyzed".
The next step was configuring Logstash. The most important part was using a filter to point to the timestamp field in our logs so it could be parsed and used by Elasticsearch. Beyond that, we created some regular expressions to extract information such as pagination, ordering and filtering from the URI. Those were either added as tags or as new fields in the resulting document, depending on the use case.
Finally, we created a series of Kibana dashboards, extracted them into JSON files and put them under version control. This enables teams to co-operate in creating and modifying dashboards using a pull request-based workflow, thus ensuring that all changes are reviewed, tracked and easy to roll back.
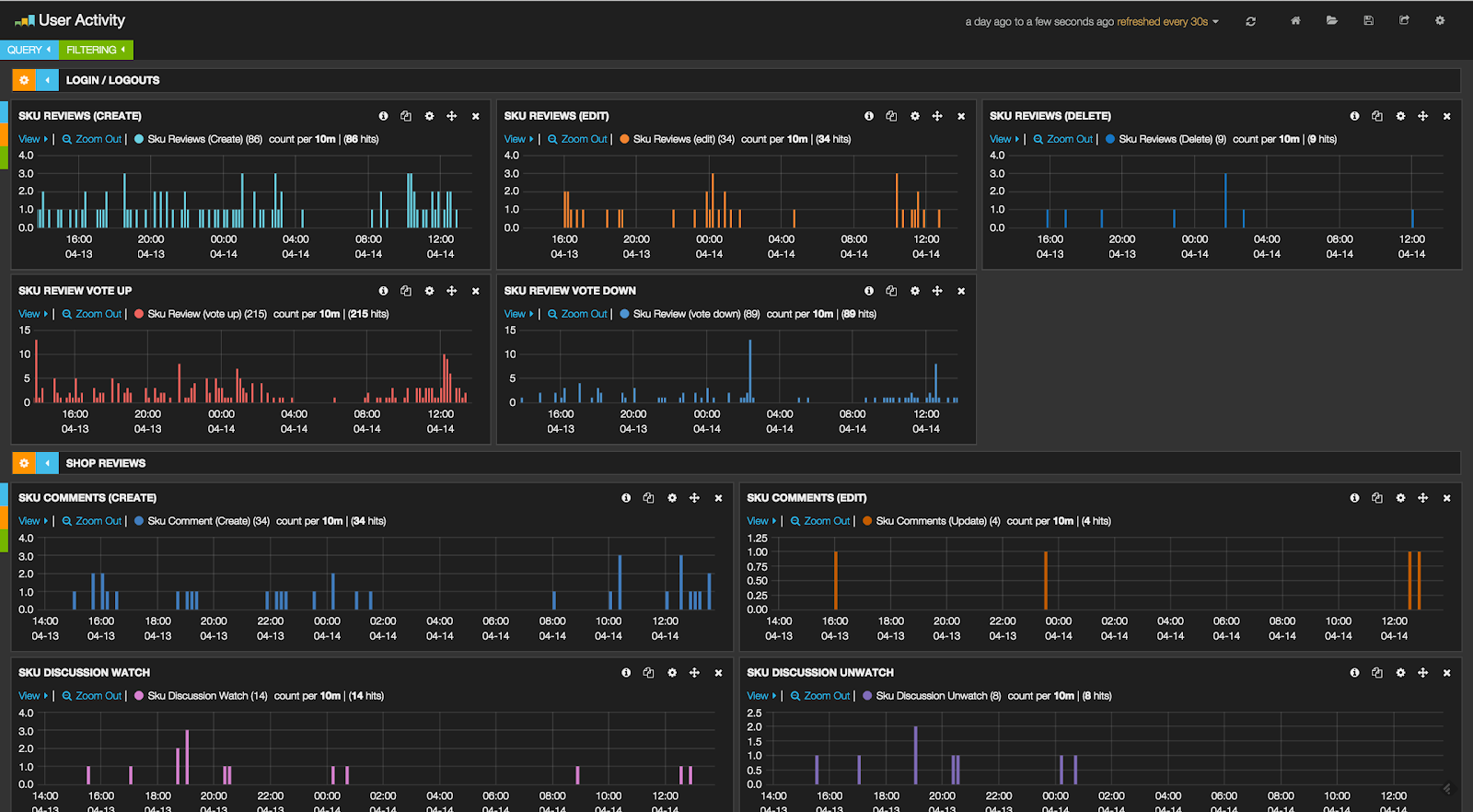
Reception and future work
We consider our project both a big success and a great start. The simple and intuitive Kibana interface has democratized access to data, making it possible for non-technical people to easily navigate their way through a Kibana dashboard and even create custom panels that suit their specific needs. Everything is indexed and no code needs to be written when a need for different statistics arises. We now have a very fast feedback loop in which the impact of a change in the website can be monitored in real-time, opening many possibilities.
But this is only the beginning. We intend to heavily utilize and build upon our new analytics platform, taking advantage of the power that Elasticsearch offers.