



This Week in Elasticsearch and Apache Lucene - 2019-02-08
Elasticsearch
Tackling CI/test failures
We took some time away from working on new features this week to address test failures which had been building up. These tend to be tricky issues to fix since they are often hard to reproduce so require a lot of effort to identify the cause. We have fixed 30 of these issues this week and we will be continuing to address these issues in the coming week as well.
Performance of BKD-backed Geoshapes
Work has continued on speeding up indexing throughput of BKD trees. A nice side-effect of this is that range fields in ES should also see an improvement since they use the same data structure (e.g. 2D points in BKD tree).
Java time migration
We have completed the work to migrate to using Java time, pushing the necessary changes for Watcher and Monitoring. There have also been severalfixes and we also fixed a performance issue in the aggregrations code. Currently, there is an open issue around a change in the date formatting of the date histogram aggregation and we need to document the expected changes / restrictions (e.g. due a bug in JDK 8, the timezone "GMT0" cannot be properly parsed (fixed in JDK 9)).
Nanosecond field mapper
Related to the jave time migration above, a new field type will be available in Elasticsearch 7.0 called date_nanos that allows to index date at the nanoseconds precision. This field will be usable in sort, docvalues_field and script with the full resolution (nanoseconds), for aggregations the value will be downgraded to the milliseconds precision automatically. Adding more precision on the date field was a longstanding feature request that we were able to tackle thanks to the migration from Joda to Java Time.
Performance
We are working on introducing default distribution benchmarks for our nightly results. Currently we either benchmark the OSS distribution or specific configurations with x-pack security with the trial license. There were some issues that alerted us that we also need to benchmark with the default distribution. Towards that, we've recently obtained new bare metal environments and we are working on a fair split of the workload per benchmark environment, necessary changes in night-rally (the tool to run nightlies) and changes in charts so that it's easy to compare results and maintain the history of earlier results.
Types removal
The last round of PRs were merged for types removal. This concludes the types removal changes we wanted to get in for 7.0. Going forward, we'll be keeping an eye out for bug reports, and are also working on solidifying the approach around typeless APIs.
SQL
We added sorting by aggregations which means that the SQL plugin is able to perform custom sorting behind the scenes and return the top N elements. The sorting is performed only on the aggregate functions, any sorting that can be pushed down to to the aggregations framework will be used as is. This means that for the query:
SELECT MAX(salary) FROM emp GROUP BY gender ORDER BY MIN(languages) ASC, gender DESC, AVG(salary) DESC
the order by gender DESC is pushed down to aggregations while MIN and AVG are sorted by SQL.
Support for first/lasthas also been added and we have implemented the CURRENTDATE* function along with their aliases, similar to CURRENT*TIMESTAMP which allows queries like:
SELECT * FROM employees WHERE birth_date > TODAY() - INTERVAL 30 YEARS
Finally we have deployed new CI jobs for the ODBC driver so we can run both unit tests and integration tests in CI.
Follower indices UI
The follower indices section of Cross-cluster replication UI app is complete. In parallel with the cross-cluster follower indices, we also merged a few enhancements on the remote clusters app to better integrate it with CCR. This week we mainly focused on tidying the UI (copy, i18n and stakeholder review) and testing.
The UI also now supports re-opening a follower index after it unfollowed the leader index (a follower index has to be paused and closed before unfollowing a leader index).
Cross Cluster Replication
We have been benchmarking the recovery from remote functionality across high-latency connections. Initial tests also showed poor performance given the small default chunk size on a cross region link with high latency (~100ms). Increasing the chunk size helped, but was still not fully saturating the network links. The key missing ingredient was the parallelization of file chunk fetching. As CCR will often times be operating across high-latency networks, recovery from remote will require concurrent fetching of file chunks to better saturate network pipes. We added the ability to fetch chunks from different files in parallel, configurable using a new ccr.indices.recovery.maxconcurrentfile_chunks setting.
With this change, the benchmarking is showing much more promising numbers. Further benchmarking in various configurations is ongoing. The file chunk size is now configurable and we have fixed twobugs found during benchmarking, one of which was causing recovery from remote to fill gaps in the history using NOOPs instead of fetching them from the leader.
Kerberos in Hadoop
Kerberos support has been merged and will make the 6.7 and 7.0.0 releases!
ILM
All ILM work for ILM/CCR integration has been completed, although we are still waiting for CCR to fully integrate shard history retention leases for it to be fully functional.
Authentication/Authorization for Security
Token Service
The OAuth2 based tokens that Elasticsearch provides can only be refreshed a single time as an added security measure. This behavior is not specified by the RFC and is left for the implementation to make a decision. Unfortunately, this restriction caused issues for Kibana's SAML auth provider and a token-based auth provider. We discussed and came to a solution; in short subsequent client requests to refresh the same token that arrive within a predefined window of 4 seconds will be treated as duplicates of the original refresh and thus receive the same response with the same access token and refresh token that was issued for the first response.
Custom Authorization Engines
The authorization engines branch has been merged and backported. This allows users to plug in their own AuthorizationEngine to be able to control how authorization decisions are made on each request. The default mechanism is backed by role and the roles define how authorization decisions are made. A custom engine could make these decisions based on any mechanism the user wants. For example the user may have authorization information stored in an external system and not be able to sync the information stored there with Elasticsearch roles so could create a custom authorization engine to query the external system and retrieve authorization information.
Changes
Changes in Elasticsearch
Changes in 7.0:
- Add apm_user reserved role 38206
- Add elasticsearch-node detach-cluster tool 37979
- Remove support for maxRetryTimeout from low-level REST client 38085
- BREAKING: Remove support for internal versioning for concurrency control 38254
- Updates the grok patterns to be consistent with the logstash 27181
- BREAKING: Remove DiscoveryPlugin#getDiscoveryTypes 38414
- Deprecate
_typein simulate pipeline requests 37949 - Deprecate types in rollover index API 38039
- Types removal - fix FullClusterRestartIT warning expectations 38310
- Deprecate HLRC security methods 37883
- Remove types from Monitoring plugin "backend" code 37745
- Run Node deprecation checks locally (#38065) 38250
- Add nanosecond field mapper 37755
- Enable TLSv1.3 by default for JDKs with support 38103
- BREAKING: Remove heuristics that enable security on trial licenses 38075
- geotile_grid implementation 37842
Changes in 6.7:
- Limit token expiry to 1 hour maximum 38244
- Fix Two Races that Lead to Stuck Snapshots 37686
- Add support for API keys to access Elasticsearch 38291
- Throw if two inner_hits have the same name 37645
- Tighten mapping syncing in ccr remote restore 38071
- RestoreService should update primary terms when restoring shards of existing indices 38177
- TransportVerifyShardBeforeCloseAction should force a flush 38401
- SQL: Allow look-ahead resolution of aliases for WHERE clause 38450
- Fix _host based require filters 38173
- Update IndexTemplateMetaData to allow unknown fields 38448
- Allow custom authorization with an authorization engine 38358
- Deprecate support for internal versioning for concurrency control 38451
- Recover retention leases during peer recovery 38435
- SQL: Fix esType for DATETIME/DATE and INTERVALS 38179
- Deprecation check for No Master Block setting 38383
- Bubble-up exceptions from scheduler 38317
- Lift retention lease expiration to index shard 38380
- Prevent CCR recovery from missing documents 38237
- Deprecate maxRetryTimeout in RestClient and increase default value 38425
- BREAKING: Make sure to reject mappings with type doc when includetype_name is false. 38270
- Update Rollup Caps to allow unknown fields 38339
if_seq_noandif_primary_termparameters aren't wired correctly in REST Client's CRUD API 38411- SQL: Implement CURRENT_DATE 38175
- Fix Concurrent Snapshot Ending And Stabilize Snapshot Finalization 38368
- Fix ILM explain response to allow unknown fields 38054
- Support unknown fields in ingest pipeline map configuration 38352
- Add Composite to AggregationBuilders 38207
- Add TLS version changes to deprecation checks 37793
- Deprecate implicit security on trial licenses 38295
- Dep. check for ECS changes to User Agent processor 38362
- Use DateFormatter in monitoring instead of joda code 38309
- Move CAS operations in TokenService to sequence numbers 38311
- Introduce retention lease background sync 38262
- SQL: Move metrics tracking inside PlanExecutor (#38259) 38288
- SQL: Remove exceptions from Analyzer (#38260) 38287
- BREAKING: Forbid negative field boosts in analyzed queries 37930
- Ensure ILM policies run safely on leader indices 38140
- Run Node deprecation checks locally 38065
- Ignore obsolete dangling indices 37824
- SQL: Allow sorting of groups by aggregates 38042
- Introduce retention leases versioning 37951
- Add finalReduce flag to SearchRequest 38104
- Don't load global ordinals with the
mapexecution_hint 37833 - Trim the JSON source in indexing slow logs 38081
- Use dateformatter in ingest-common to log deprecations 38099
- Fix file reading in ccr restore service 38117
Changes in 6.6:
- Preserve ILM operation mode when creating new lifecycles 38134
- SQL: Fix issue with IN not resolving to underlying keyword field 38440
- SQL: change the Intervals milliseconds precision to 3 digits 38297
- Cleanup construction of interceptors 38294
- Fix IndexAuditTrail rolling upgrade on rollover edge - take 2 38286
- SQL: Generate relevant error message when grouping functions are not used in GROUP BY 38017
- Allow built-in monitoring_user role to call GET _xpack API 38060
Changes in 6.5:
- Fix NPE in Logfile Audit Filter 38120
Changes in Elasticsearch Hadoop Plugin
Changes in 7.0:
- BREAKING: Remove Cascading 1235
Changes in 6.7:
- Disable testing in kerberos project when localRepo is set 1245
- Add support for Kerberized Elasticsearch 1244
Changes in Elasticsearch Management UI
Changes in 7.0:
- BREAKING: Add configPrefix to Index Management, License Management, Rollup Jobs, and Upgrade Assistant 30149
Changes in 6.7:
- [CCR] Disable flaky follower indices API integration tests. 30157
- Order Elasticsearch Management apps in order of most used to least used. 30145
- fixing React warning about missing prop 30147
- [CCR] Follower index CRUD 27936
- improving a11y for activating phases 30101
Changes in 6.6:
- [Watcher] Add missing Action types on client (webhook) 29818
Changes in Elasticsearch SQL ODBC Driver
Changes in 6.7:
- Integration testing: increase timeouts for ES starting 109
Changes in 6.6:
Changes in Rally
Changes in 1.0.4:
- Add recovery-stats telemetry device 639
Changes in Rally Tracks
- Allow _doc type in master 64
Lucene
Lucene 7.7 and 8.0
There is an ongoing vote to release Lucene 7.7 which is going well so far. Once Lucene 7.7 is out, we plan to immediately start a new vote for Lucene 8.0.
Faster construction of BKD trees
Lucene builds BKD trees by recursively splitting points by the median value of the dimension that has the wider range. Until now the approach was to assign an ordinal to all points, sort by every dimension up-front, and recursively build the tree by marking ordinals that should go on the right side of the tree in a bitset. The logic was written entirely by removing the up-front sort which was costing a lot of CPU and temporary disk space, and recursively partitioning using a variant of quickselect that can run offline (we build huge trees so we can't afford to hold everything in memory). This change resulted in a stunning 2x indexing throughput improvement for geo shapes and +15% for geo points. Another side-effect of this change is that it greatly reduces the amount of temporary disk space that is required in order to build the tree. The below chart compares disk usage over time with (Radix) and without (Current) the change:
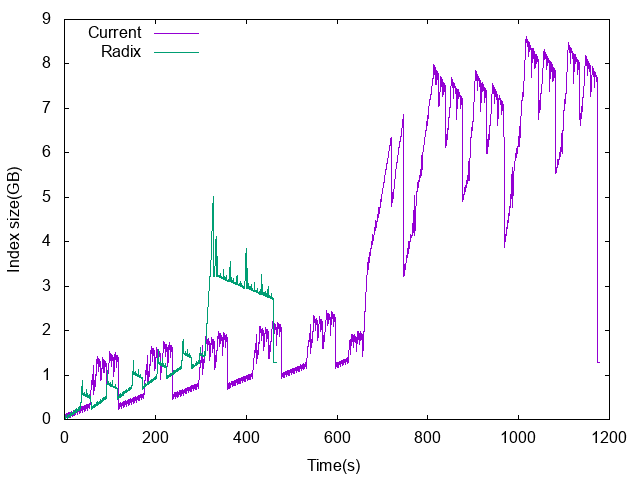
There are some follow-up ideas how to optimize it further and indexing points as geo-shapes in the upcoming Lucene 8.1 will likely be almost as fast as indexing geo points in Lucene 7.x.
Faster but inaccurate top hits
A long term member of the Lucene community, started a thread about enabling Lucene to skip collecting documents if they are unlikely to make it to the top hits. For instance if you have 10 segments that are sorted by some field and want the top 100 documents sorted by this field. Today, Lucene will always collect 100 documents on this first segment, while the 100th collected document is actually unlikely to make it to the top hits globally. So a discussion started about how we can more generally allow users to trade accuracy for speed. Note that this is different from enhancements that have been brought to Lucene 8.0/Elasticsearch 7.0 which always return the correct top hits.
Other
- equals/hashcode support was added to Lucene's TotalHits object.
- Lucene already supports searching multiple segments in parallel. Could we go further and leverage threads to speed up searching a single segment?