



Seguir al líder: Una introducción a la replicación entre clusters en Elasticsearch
Las necesidades de muchos
La capacidad de replicar datos de forma nativa en un cluster de Elasticsearch desde otro cluster de Elasticsearch es la característica más solicitada, y una que nuestros usuarios piden desde hace mucho. Después de años de un esfuerzo de ingeniería para sentar las bases necesarias, incorporar tecnología nueva fundamental en Lucene e iterar y refinar nuestro diseño inicial, nos entusiasma anunciar que la replicación entre clusters (CCR) ahora se encuentra disponible y lista para la producción en Elasticsearch 6.7.0. En este blog, el primero de una serie, proporcionaremos una breve introducción a lo que hemos implementado y algunos antecedentes técnicos sobre la CCR. En los próximos blogs analizaremos detalladamente casos de uso específicos de la CCR.
La replicación entre clusters en Elasticsearch permite una variedad de casos de uso de misión crítica dentro de Elasticsearch y el Elastic Stack:
- Recuperación de desastre (DR)/disponibilidad alta (HA): la tolerancia para resistir un corte de energía en el centro de datos o la región es un requisito de muchas aplicaciones de misión crítica. Este requisito se resolvió previamente en Elasticsearch con tecnologías adicionales, que agregaban mayor complejidad y gastos generales de administración. Ahora es posible satisfacer los requisitos de DR/HA entre datacenters de forma nativa en Elasticsearch, con la CCR y sin tecnologías adicionales.
- Localización de datos: replica los datos en Elasticsearch para acercarte más al usuario o al servidor de aplicaciones, reduciendo las latencias que te generan gastos. Por ejemplo, es posible replicar un catálogo de productos o set de datos de referencia en veinte o más centros de datos en todo el mundo para minimizar la distancia entre los datos y el servidor de aplicaciones. Otro caso de uso puede ser el de una firma bursátil con oficinas en Londres y Nueva York. Todas las transacciones de la oficina de Londres se registran de forma local y se replican en la oficina de Nueva York, y viceversa. Ambas oficinas tienen una visión global de todas las transacciones.
- Reportes centralizados: replica los datos de una gran cantidad de clusters más pequeños en un cluster de reportes centralizado. Es útil cuando buscar en una red grande puede no ser eficiente. Por ejemplo, un banco global grande puede tener 100 clusters de Elasticsearch en todo el mundo, cada uno en una sucursal bancaria diferente. Podemos usar la CCR para replicar los eventos de todos los 100 bancos en todo el mundo en un cluster central que nos permita analizar y agregar eventos de forma local.
Antes de Elasticsearch 6.7.0, estos casos de uso podían abordarse parcialmente con tecnologías de terceros, lo cual es complicado, trae aparejado muchos gastos generales administrativos y tiene desventajas importantes. Gracias a la replicación entre clusters integrada de forma nativa en Elasticsearch, liberamos a nuestros usuarios de la carga y las desventajas de administrar soluciones complicadas, podemos ofrecer ventajas por sobre lo que brindan las soluciones existentes (por ejemplo, manejo integral de errores) y API dentro de Elasticsearch y UI en Kibana para administrar y monitorear la CCR.
Mantente atento a los blogs de seguimiento para adentrarte en cada uno de estos casos de uso con mayor detalle.
Primeros pasos con la replicación entre clusters
Visita nuestra página de descargas para obtener las versiones más recientes de Elasticsearch y Kibana, y sumérgete con nuestra guía de primeros pasos.
CCR es una característica de nivel platino y se encuentra disponible a través de una licencia de prueba por 30 días que puede activarse mediante la API de inicio de prueba o directamente desde Kibana.
Introducción técnica a la replicación entre clusters
La CCR está diseñada en torno a un modelo de índice activo-pasivo. Un índice en un cluster de Elasticsearch puede configurarse para replicar los cambios de un índice en otro cluster de Elasticsearch. El índice que replica los cambios se denomina “índice seguidor”, y aquel desde el cual se replican, “índice líder”. El índice seguidor es pasivo en el sentido que puede atender solicitudes de lectura y búsquedas, pero no puede aceptar escrituras directas; solo el índice líder está activo para escrituras directas. Como la CCR se administra a nivel del índice, un cluster puede contener tanto índices líderes como índices seguidores. De esta forma, puedes resolver algunos casos de uso activo-activo replicando algunos índices en una dirección (por ejemplo, de un cluster de los EE. UU. a un cluster europeo) y otros en la otra dirección (de un cluster europeo a un cluster de los EE. UU.).
La replicación se realiza a nivel del shard; cada shard en el índice seguidor extraerá los cambios de su shard correspondiente en el índice líder, lo que significa que un índice seguidor tiene la misma cantidad de shards que su índice líder. El seguidor replica todas las operaciones, de modo que se replican las operaciones de creación, actualización y eliminación. La replicación se realiza prácticamente en tiempo real; tan pronto como el punto de control global de un shard avanza, una operación es elegible para que un shard siguiente la replique. El shard siguiente extrae e indexa eficientemente de forma masiva las operaciones; y es posible la ejecución de varias solicitudes de extracción de datos al mismo tiempo. Tanto los datos primarios como las réplicas pueden responder estas solicitudes de lectura; y salvo por la lectura desde el shard, estas solicitudes no agregan una carga adicional al líder. Este diseño permite a la CCR escalar junto a tu carga de producción para que puedas continuar disfrutando de las velocidades de indexación de alto rendimiento que has llegado a apreciar (y esperar) en Elasticsearch.
La CCR soporta tanto índices nuevos como existentes. Cuando se configura un seguidor inicialmente, se iniciará desde el índice líder copiando los archivos subyacentes desde el índice líder en un proceso similar al que se realiza cuando una réplica se recupera de un dato primario. Una vez finalizado este proceso de recuperación, la CCR replicará cualquier operación adicional del líder. Los cambios de mapeo y configuración se replican automáticamente según sea necesario desde el índice líder.
Ocasionalmente, la CCR puede enfrentarse a escenarios de error (por ejemplo, una falla de la red). La CCR puede clasificar automáticamente estos errores en errores recuperables y errores fatales. Cuando se produce un error recuperable, la CCR entra en un bucle de reintentos para reanudar la replicación tan pronto como se resuelva la situación que llevó a la falla.
El estado de la replicación puede monitorearse mediante una API dedicada. A través de esta API puedes monitorear con cuánta cercanía el seguidor rastrea al líder, ver estadísticas detalladas sobre el rendimiento de la CCR y rastrear cualquier error que requiera tu atención.
Integramos la CCR con las aplicaciones de monitoreo y administración dentro de Kibana. La UI de monitoreo te permite ver el progreso de la CCR y reportes de error.

UI de monitoreo de la CCR de Elasticsearch en Kibana
La UI de administración te permite configurar clusters remotos, configurar índices seguidores y administrar patrones autoseguidores para la replicación automática de índices.
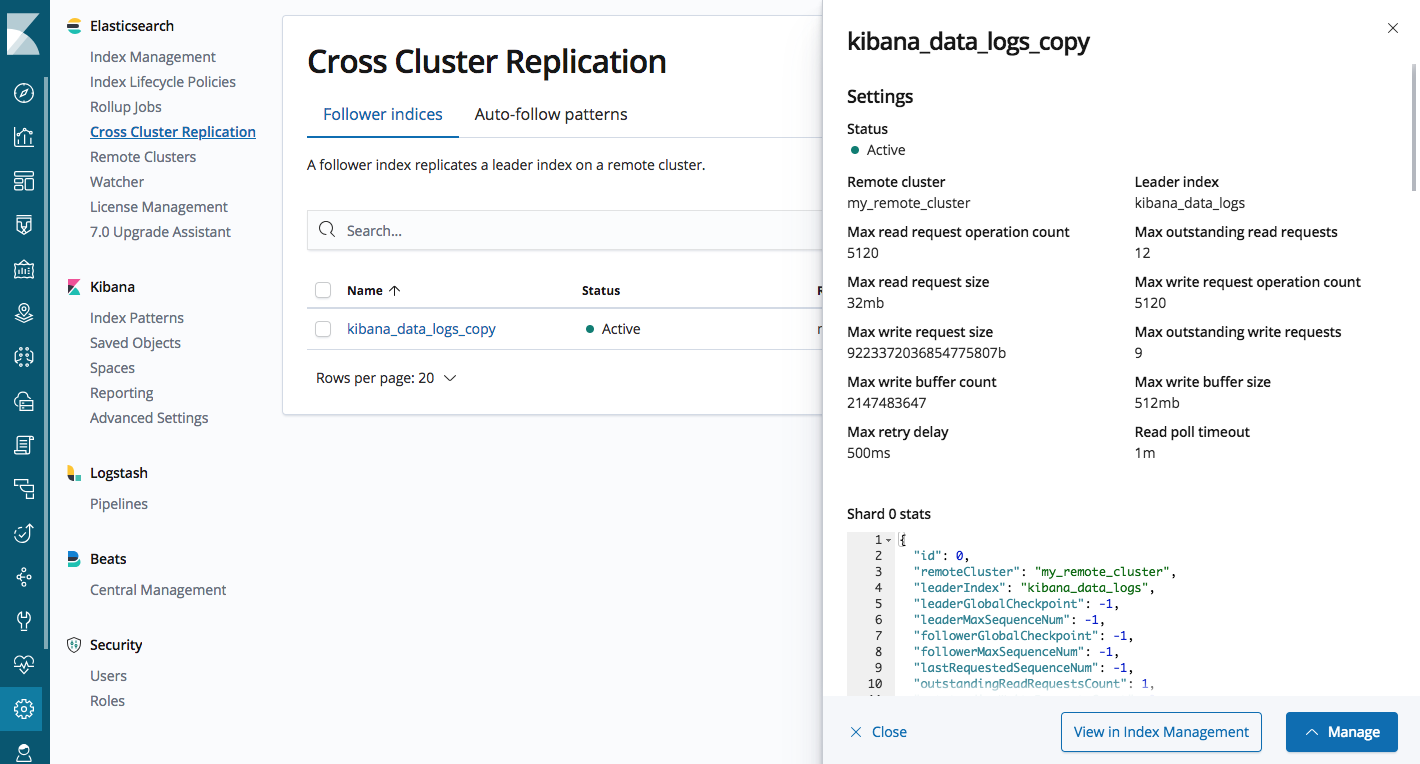
UI de administración de la CCR de Elasticsearch en Kibana
Seguimiento de los índices actuales
Muchos de nuestros usuarios tienen cargas de trabajo que crean índices nuevos periódicamente. Por ejemplo, los índices diarios de los archivos de log que Filebeat envía o los índices acumulados automáticamente con la gestión de ciclo de vida de los índices (ILM). En lugar de tener que crear índices seguidores manualmente para replicar estos índices desde un cluster de origen, incorporamos la funcionalidad de autoseguimiento directamente en la CCR. Esta funcionalidad te permite configurar la replicación automática de patrones de índices desde un cluster de origen. La CCR monitoreará los clusters de origen en busca de índices que coincidan con estos patrones y configurará los índices siguientes para que repliquen aquellos índices líderes que coincidan.
También integramos la CCR y la ILM para que los índices basados en el tiempo puedan replicarse mediante CCR y administrarse con ILM tanto en clusters de origen como de destino. Por ejemplo, la ILM comprende cuándo la CCR está replicando un índice líder y, por lo tanto, administra cuidadosamente las operaciones destructivas como la reducción y eliminación de índices hasta que la CCR haya concluido la replicación.
Los que no conocen la historia
Para que la CCR pueda replicar cambios, es necesario un historial de operaciones en los shards del índice líder e indicadores en cada shard para conocer cuáles operaciones es seguro replicar. El historial de operaciones se rige por las ID de secuencia, y el indicador se conoce como punto de control global. Sin embargo, hay una complicación. Cuando se actualiza o elimina un documento en Lucene, Lucene marca un bit para registrar la eliminación del documento. El documento se retiene en el disco hasta que una futura operación de fusión fusione los documentos eliminados. Si la CCR replica esta operación antes de que la eliminación se fusione, todo está bien. Pero las fusiones ocurren conforme a su propio ciclo de vida, lo que significa que un documento eliminado podría fusionarse antes de que la CCR haya tenido la oportunidad de replicar la operación. Sin la capacidad de controlar cuándo se fusionan los documentos eliminados, la CCR podría pasar por alto operaciones y no poder replicar por completo el historial de operaciones en el índice seguidor. En la fase inicial del diseño de la CCR planificamos usar el log de transacciones de Elasticsearch como fuente del historial de estas operaciones; esto habría evitado el problema. Rápidamente nos dimos cuenta de que el log de transacciones no estaba diseñado para los patrones de acceso que la CCR necesitaba para tener un rendimiento efectivo. Consideramos agregar estructuras de datos adicionales sobre y junto al log de transacciones para lograr el rendimiento que necesitábamos; pero este enfoque tiene limitaciones. En primer lugar, agregaría mayor complejidad a uno de los componentes más fundamentales de nuestro sistema, lo cual simplemente no es coherente con nuestra filosofía de ingeniería. Además, nos limitaría con respecto a cambios futuros que queremos realizar sobre el historial de operaciones, y estaríamos obligados a limitar los tipos de búsquedas que pueden realizarse en el historial de operaciones o a volver a implementar todo Lucene sobre el log de transacciones. A partir de esta información, nos dimos cuenta de que necesitábamos integrar de forma nativa en Lucene una funcionalidad que nos permitiera controlar cuándo fusionar un documento eliminado y enviar así, efectivamente, el historial de operaciones a Lucene. A esta tecnología la denominamos “eliminación parcial”. Esta inversión en Lucene se pagará sola en los próximos años debido a que no solo la CCR está desarrollada a partir de la eliminación parcial, sino que estamos recreando nuestro modelo de replicación en base a esta; y las próximas API de cambios también estarán basadas en esta tecnología. La eliminación parcial debe estar habilitada en los índices líder.
Lo que resta, entonces, es que un seguidor pueda influenciar cuándo se fusionan los documentos eliminados de forma parcial en el líder. Para este fin, introdujimos los alquileres de retención del historial de shard. Con un alquiler de retención del historial de shard, un seguidor puede marcar en el historial de operaciones del líder en qué parte del historial se encuentra actualmente ese seguidor. Los shards del líder saben que es seguro fusionar las operaciones debajo de dicha marca, pero que se deben retener todas las operaciones por encima de la marca hasta que el seguidor haya tenido la oportunidad de replicarlas. Estos marcadores garantizan que si un seguidor se desconecta temporalmente, el líder mantendrá las operaciones que aún no se replicaron. Debido a que la retención de este historial requiere almacenamiento adicional en el líder, estos marcadores solamente son válidos por un período limitado después del cual el marcador expirará y los shards del líder podrán fusionar el historial. Puedes ajustar la duración de este período conforme a la cantidad de almacenamiento que estés dispuesto a retener en caso de que un servidor se desconecte y al período que estés dispuesto a aceptar que un seguidor esté desconectado antes de que deba volver a iniciarse desde el líder.
Resumen
Nos encanta que pruebes la CCR y compartas con nosotros tus comentarios sobre la funcionalidad. Esperamos que disfrutes esta funcionalidad tanto como nosotros disfrutamos crearla. Mantente atento a los blogs futuros de esta serie en los que nos dedicaremos a explicar con mayor detalle algunas de las funcionalidades en la CCR y los casos de uso para los que la CCR está destinada. Y si tienes preguntas sobre la CCR, puedes consultar en el foro de discusión.
La imagen en miniatura asociada con este blog es propiedad de la NASA y está protegida bajo la licencia CC BY-NC 2.0. La imagen del banner asociada con este blog es propiedad de Rawpixel Ltd, está protegida bajo la licencia CC BY 2.0 y es un recorte de la imagen original.