



Lexer's upgrade to Elasticsearch 5.4.1 improved search speeds by 30-40%
Lexer houses a gigantic data set of 2.8 billion documents on 14 terabytes of disk space and over the last few months, we’ve migrated it all over to Elasticsearch 5.4.1. The result? A dramatic 30-40% performance increase for our most commonly used features and a more robust and scalable product moving forward.
Scaling up
Lexer provide the data, tools and team to help companies genuinely understand and engage current and prospective customers. Elasticsearch helps us process large volumes of data and present it to our clients for insight and action.
When we first began using Elasticsearch, our platform was managing around one million pieces of social content per day. Today that figure has climbed to 30 million per day, so upgrading towards a more robust cluster running Elasticsearch 5.4.1 was a crucial step in building a scalable product going forward.
Elasticsearch 5.4.1 features dramatically improved indexing performance making it faster to get new data into the system. Plus, it comes with a new default scripting language (Painless) that is several times faster than the alternatives. Resilience is also a key focus: searches keep running even if hardware fails, or someone gets greedy with a huge complicated search.
Needless to say, we were pretty eager to move in, so the first step was to work out how we were going to pack up the boxes in preparation for a full-scale migration.
Preparing for migration
The first step for us was moving our data into smaller indexes. We moved from a single index containing 2.8 billion tweets, comments, messages, articles and blogs to 90 smaller indexes of about 30 million objects each. These new indexes made the process of migration much more streamlined, and, more broadly, allowed our clients to make more efficient requests within Lexer.
The next step was to ensure our searches were compatible with Elasticsearch 5.4.1 by updating our query generation library to ensure the queries generated in the interface (i.e. term matches or author searches) would work on the new search cluster.
Here’s an example of the type of queries that had to be migrated, "and" and "or" filters which had to be translated into "bool" queries using "must" and "should":
Old Query
{
"query": {
"filter": {
"and": [
{
"or": [
{
"query": {
"query_string": {
"query": "car AND (blue OR red)",
"default_field": "content.content"
}
}
},
{
"query": {
"query_string": {
"query": "bob",
"default_field": "content.author"
}
}
}
]
},
{
"query": {
"query_string": {
"query": "facebook.com",
"default_field": "content.source"
}
}
}
]
}
}
}
New Query:
{
"query": {
"bool": {
"must": [
{
"query": {
"query_string": {
"query": "facebook.com",
"default_field": "content.source"
}
}
}
],
"should": [
{
"query": {
"query_string": {
"query": "car AND (blue OR red)",
"default_field": "content.content"
}
}
},
{
"query": {
"query_string": {
"query": "bob",
"default_field": "content.author"
}
}
}
],
"minimum_should_match": 1
}
}
}
We could translate these queries easily because we never stored Elasticsearch queries directly but instead store them in our own domain specific logical query structure. All we had to do was modify the library that translates our internal query format into Elasticsearch queries so that it would output queries that were accepted by Elasticsearch 5.
So our concerns here were not so much with common queries like keyword searches but instead with the more complicated searches, like geolocation filters. Our interface allows users to draw a box on a map that is effectively 4 lat/long points, which is converted into an Elasticsearch query and run against the cluster.
Here’s what this looks like in Lexer Listen, our social analytics tool. In this example, the user is searching for people posting about the Australian Football League (AFL) in the vicinity of its biggest stadium, the Melbourne Cricket Ground. All of the charts and tables in this example are the result of Elasticsearch aggregations using the geo filter.
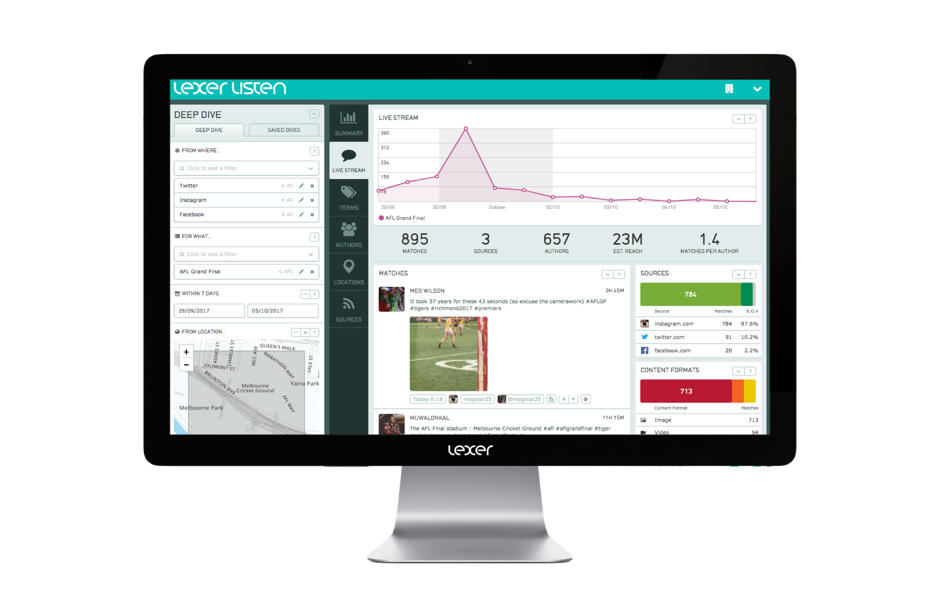
The "From Location" map filter translates into an Elasticsearch query like this:
{
"geo_bounding_box": {
"geography.point": {
"top_left": {
"lat": -37.8169206345321,
"lon": 144.978375434875
},
"bottom_right": {
"lat": -37.8230227432016,
"lon": 144.987988471985
}
}
}
}
We needed to ensure that this query was converting the inputs from the user into something the cluster could understand, so we rigorously tested all of the query combinations and possibilities until we were 100% sure these queries worked against Elasticsearch 5.4.1 APIs.
Pressing play
We used the snapshot and restore method to move data from the old Elasticsearch 2.3.4 cluster to a new Elasticsearch 5.4.1 cluster. Elasticsearch provides a snapshot facility that can copy index data to one of many destinations (in our case we used Amazon S3) and then restore this data very quickly into a different cluster. After configurations were complete and we’d conducted a range of tests, we completed a full disaster recovery scenario, going from absolutely nothing to a brand new cluster with our complete 3.7B object data set within just 40 minutes. Going down the snapshot restore route we came away not only with an upgraded cluster, we also got a robust backup system that backs up our entire social dataset every 15 minutes as well as a quick and reliable disaster recovery scenario.
A 30-40% performance increase
After performing the upgrade, the benefits were immediately obvious. Our general query performance improved 13% and some of our most frequently used features (those that show the context and history of a social object) saw a dramatic improvement of 30% to 40%.
To put that into perspective, these features are currently used over 8,000 times a day and this translates to a time saving of 6 hours a day across all our clients!
Looking forward
We’ve been with Elastic from the very beginning, and are proud to cultivate a unique use case for their stack.
Overall, we came away from this project with faster speeds for our clients, better processes for performing Elasticsearch cluster upgrades, a robust backup system, and a tested disaster recovery procedure. It also gave us lots of ideas to continue improving search performance, and making our cluster more efficient and scalable as Lexer takes on the world.
Chris Scobell is VP of Human Interface at Lexer.