Where we started
The first version of Elasticsearch was released in 2010 as a distributed scalable search engine allowing users to quickly search for and surface critical insights. Twelve years and over 65,000 commits later, Elasticsearch continues to provide users with battle-tested solutions to a wide variety of search problems. Thanks to the efforts of over 1,500 contributors, including hundreds of full-time Elastic employees, Elasticsearch has constantly evolved to meet the new challenges that arise in the field of search.
Early in Elasticsearch's life when data loss concerns were raised, the Elastic team underwent a multiyear effort to rewrite the cluster coordination system to guarantee that acknowledged data is stored safely. When it became clear that managing indices in large clusters was a hassle, the team worked on implementing an extensive ILM solution to automate this work by allowing users to predefine index patterns and lifecycle actions. As users found a need to store significant amounts of metric and time series data, various features such as better compression were added to reduce data size. As the storage cost of searching extensive amounts of cold data grew we invested in creating Searchable Snapshots as a way to search user data directly on low cost object stores.
These investments lay the groundwork for the next evolution of Elasticsearch. With the growth of cloud-native services and new orchestration systems, we have decided it is time to evolve Elasticsearch to improve the experience when working with cloud-native systems. We believe that these changes present opportunities for operational, performance, and cost improvements while running Elasticsearch on Elastic Cloud.
Where we are going — future is stateless
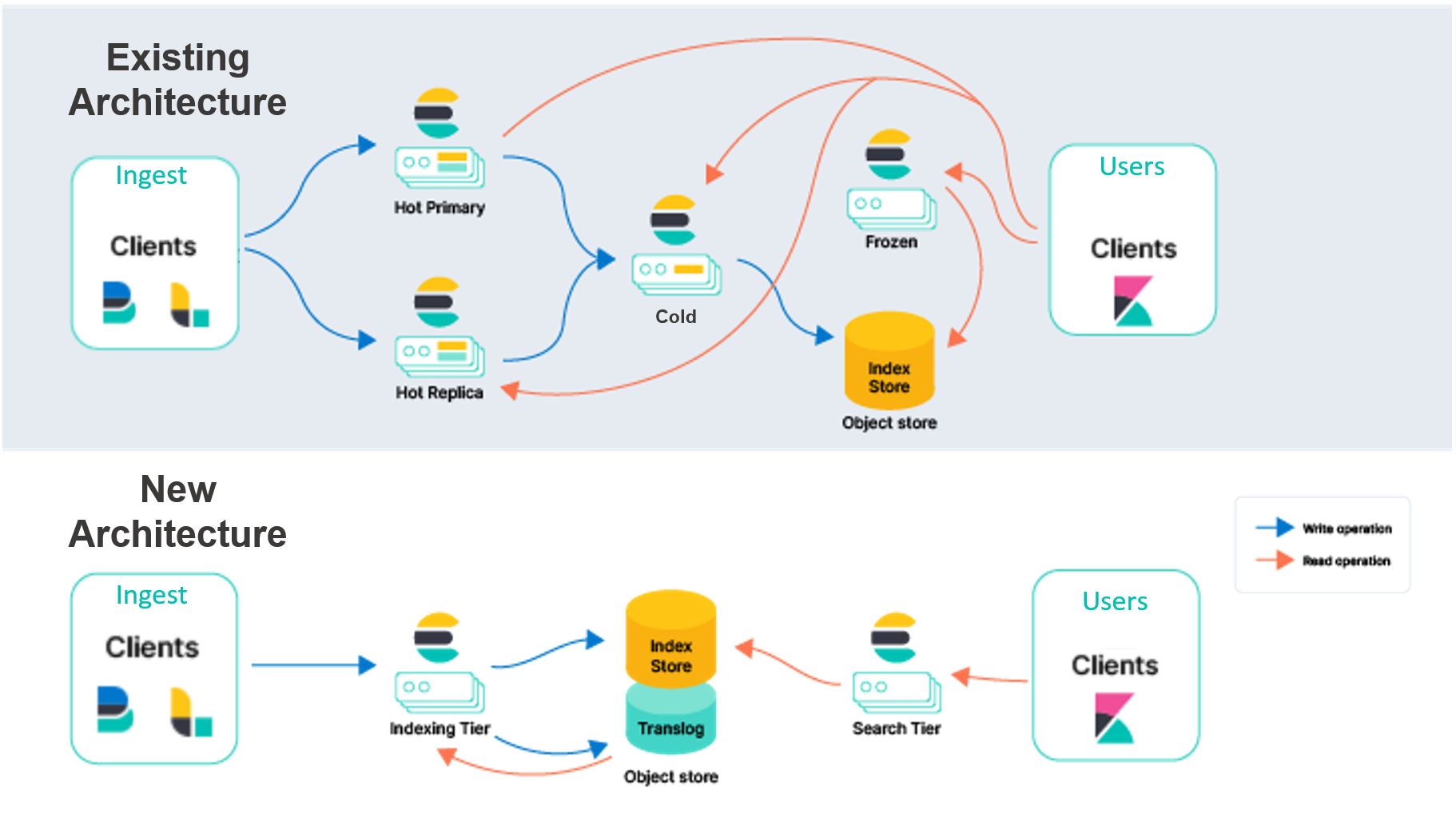
One of the primary challenges when operating or orchestrating Elasticsearch is that it depends on numerous pieces of persistent state, it is therefore a stateful system. The three primary pieces are the translog, index store, and cluster metadata. This state means that storage must be persistent and cannot be lost during a node restart or replacement.
The existing Elasticsearch architecture on Elastic Cloud must duplicate indexing across multiple availability zones to provide redundancy in the case of outages. We intend to shift the persistence of this data from local disks to an object store, like AWS S3. By relying on external services for storing this data, we will remove the need for indexing replication, significantly reducing the hardware associated with ingestion. This architecture also provides very high durability guarantees because of the way cloud object stores such as AWS S3, GCP Cloud Storage, and Azure Blob Storage replicate data across availability zones.
Offloading index storage into an external service will also allow us to re-architect Elasticsearch by separating indexing and search responsibilities. Instead of having primary and replica instances handling both workloads, we intend to have an indexing tier and a search tier. Separating these workloads will allow them to be scaled independently and hardware selection to be more targeted for the respective use cases. It also helps solve a longstanding challenge where search and indexing load can impact one another.
After undertaking a multi-month proof-of-concept and experimental phase, we are convinced that these object store services meet the requirements we envision for index storage and cluster metadata. Our testing and benchmarks indicate that these storage services can meet the high indexing needs of the largest clusters we have seen in Elastic Cloud. Additionally, backing the data in the object store reduces indexing costs and allows for simple tuning of the performance of search. In order to search data, Elasticsearch will use the battled-tested Searchable Snapshots model where data is permanently persisted in the cloud-native object store and local disks are used as caches for frequently accessed data.
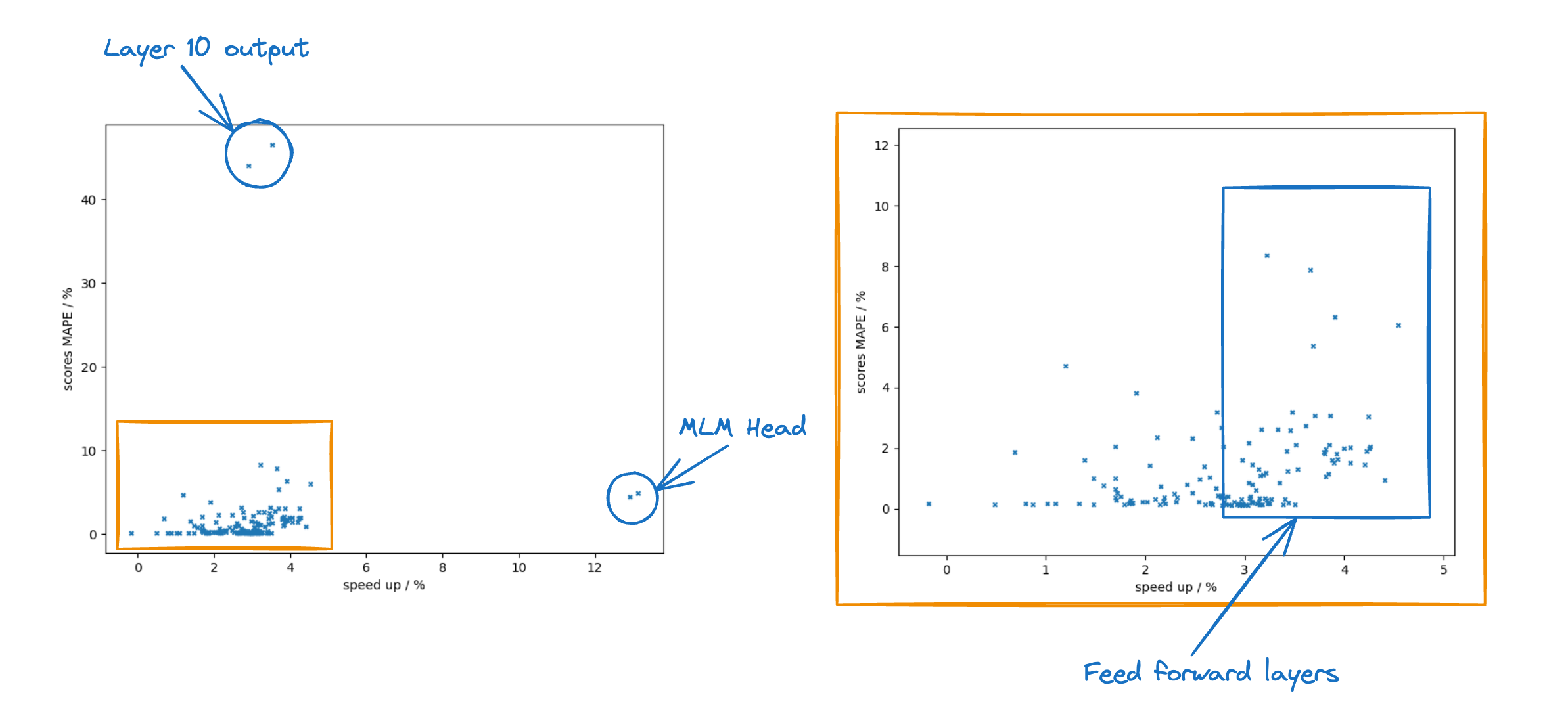
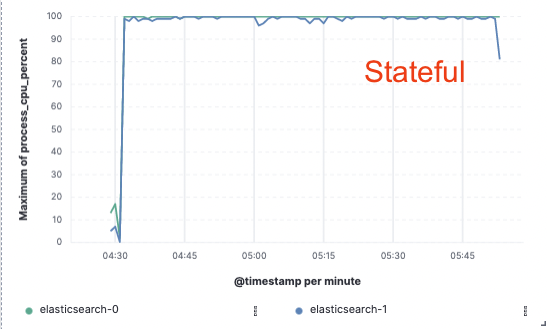
To help differentiate, we describe our existing model as "node-to-node" replication. In the hot tier for this model, the primary and replica shards both do the same heavy lifting to handle ingest and serve search requests. These nodes are "stateful" in that they rely on their local disks to safely persist the data for the shards they host. Additionally, primary and replica shards are constantly communicating to stay in sync. They do this by replicating the operations performed on the primary shard to the replica shard, which means that the cost of those operations (CPU, mainly) is incurred for each replica specified. The same shards and nodes doing this work for ingest are also serving search requests, so provisioning and scaling must be done with both workloads in mind.
Beyond search and ingest, shards in the node-to-node replication model handle other intensive responsibilities, such as merging Lucene segments. While this design has its merits, we saw a lot of opportunity based on what we've learned with customers over the years and the evolution of the broader cloud ecosystem.
The new architecture enables many immediate and future improvements, including:
- You can significantly increase ingest throughput on the same hardware, or to look at it another way, significantly improve efficiency for the same ingest workload. This increase comes from removing the duplication of indexing operations for every replica. The CPU-intensive indexing operations only need to happen once on the indexing tier, which then ships the resulting segments to an object store. From there, the data is ready to be consumed as-is by the search tier.
- You can separate compute from storage to simplify your cluster topology. Today, Elasticsearch has multiple data tiers (content, hot, warm, cold, and frozen) to match data with hardware profile. Hot tier is for near real-time search and frozen is for less frequently searched data. While these tiers provide value, they also increase complexity. In the new architecture, data tiers will no longer be necessary, simplifying the configuration and operation of Elasticsearch. We are also separating indexing from search, which further reduces complexity and allows us to scale both workloads independently.
- You can experience improved storage costs on the indexing tier by reducing the amount of data that must be stored on a local disk. Currently, Elasticsearch must store a full shard copy on hot nodes (both primary and replica) for indexing purposes. With the stateless approach of indexing directly to the object store, only a portion of that local data is required. For append only use cases, only certain metadata will need to be stored for indexing. This will significantly reduce the local storage required for indexing.
- You can lower storage costs associated with search queries. By making the Searchable Snapshots model the native mode of searching data, the storage cost associated with search queries will significantly decrease. Depending on the search latency needs for users, Elasticsearch will allow adjustments to increase local caching on frequently requested data.
Benchmarking — 75% indexing throughput improvement
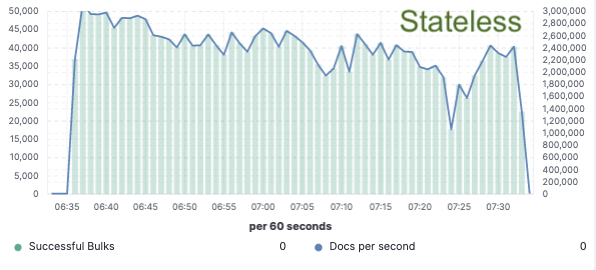
In order to validate this approach we implemented an extensive proof of concept where data was only indexed on a single node and replication was achieved through cloud object stores. We found that we could achieve a 75% indexing throughput improvement by removing the need to dedicate hardware to indexing replication. Additionally, the CPU cost associated with simply pulling data from the object store was much lower than indexing the data and writing it locally, as is necessary for the hot tier today. This means that search nodes will be able to fully dedicate their CPU to search.
These performance tests were performed on a two node cluster against all three major public cloud providers (AWS, GCP, and Azure). We intend to continue to build out larger benchmarks as we pursue a production stateless implementation.
Indexing Throughput
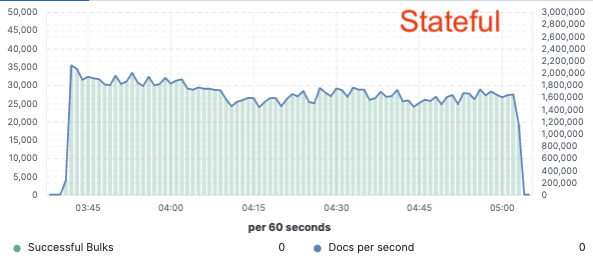
CPU Usage
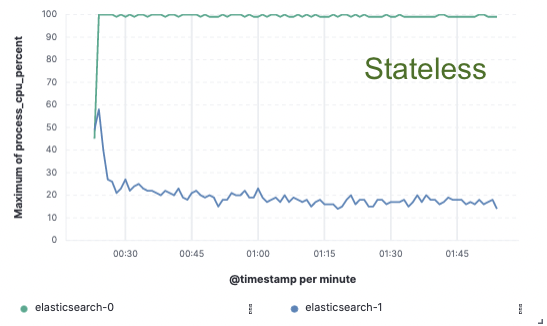
Stateless for us, savings for you
The stateless architecture on Elastic Cloud will allow you to reduce indexing overhead, independently scale ingest and search, simplify data tier management, and accelerate operations, such as scaling or upgrading. This is the first milestone towards a substantial modernization of the Elastic Cloud platform.
Become part of our stateless vision
Interested in trying out this solution before everyone else? You can reach out to us on discuss or on our community slack channel. We would love your feedback to help shape the direction of our new architecture.