어떤 한국어 분석기를 사용할까?
1443년 세종대왕은 한글을 창제합니다. 그 전에는 한자를 사용했지만, 중국어는 우리말과 많이 달라 실질적으로 한자를 익힐 여유가 있는 사람들은 양반들뿐이었고 평민들은 생업에 바빠 틈을 내서 한자를 익히기 어려웠습니다.
한글은 24자로 이루어진 표음문자입니다. 14개의 자음(ㄱ[g], ㄴ[n], ㄷ[d], ㄹ[l/r], ㅁ[m], ㅂ[b], ㅅ[s], ㅇ[null/ng], ㅈ[j], ㅊ[ch], ㅋ[k], ㅍ[p], ㅌ[t], ㅎ[h])과 10개의 모음(ㅏ[a], ㅑ[ja], ㅓ[ə], ㅕ[jə], ㅗ[o], ㅛ[jo], ㅜ[u], ㅠ[ju], ㅡ[ɯ], ㅣ[i])으로 이루어져 있고, 이들을 조합하여 11172자(음절, 예: ㅎ+ㅏ+ㄴ=한)를 만들 수 있습니다.
엘라스틱서치를 이용해서 한국어 문서들을 효과적으로 검색하려면 한국어 분석기가 필요합니다. 영어는 굴절어, 중국어는 고립어임에 비해, 우리말은 교착어입니다. 같은 뜻의 용언이라도 어미에 따라 형태가 바뀌고(예, ‘먹다’와 ‘먹고’), 체언은 조사를 붙여서 쓰는 경우가 많으며(예, 엘라스틱서치(체언)+를(조사)),’문서들’과 같이 접미사(‘들’)를 붙이기도 합니다. 한국어 분석기 없이 검색하면 이렇게 변형된 형태 중 하나만 검색되기 때문에, 예를 들어 ‘엘라스틱서치’를 키워드로 검색하면 ‘엘라스틱서치를’이 포함된 문서는 검색이 되지 않습니다. 한국어 분석기는 ‘엘라스틱서치를 이용해서 한국어 문서들을 효과적으로 검색하려면 한국어 분석기가 필요합니다’라는 문장을 ‘엘라스틱서치’, ‘를’, ‘이용’, ‘해서’, ‘한국어’, ‘문서’, ‘들’, ‘을’, ‘효과적’, ‘으로’, ‘검색’, ‘하려면’, ‘한국어’, ‘분석기’, ‘가’, ‘필요’, ‘합니다’와 같은 키워드로 분리합니다(참고용으로 제시한 것이고 실제 분석 결과는 아닙니다). 이로써 문서에 ‘엘라스틱서치’가 있든 ‘엘라스틱서치를’이 있든 키워드 ‘엘라스틱서치’로 검색할 수 있게 됩니다.
현재 엘라스틱서치용 한국어 형태소 분석기로는 상용 제품과 오픈 소스 프로젝트가 있고, 필요하다면 사용자가 자체 개발도 할 수 있도록 API도 제공됩니다. 오픈 소스 프로젝트 중 널리 알려진 것으로는 seunjeon, arirang, open-korean-text의 세 가지가 있습니다. 이 중 open-korean-text는 엘라스틱서치 5.x 버전만을 지원합니다. 엘라스틱서치 5.5.0에 이들 세 형태소 분석기를 설치한 뒤 분석 속도와 분석 중 메모리 사용량을 비교해 보았습니다.
seunjeon
- URL: https://bitbucket.org/eunjeon/seunjeon
- 설명: mecab-ko-dic 기반으로 만들어진 JVM 상에서 돌아가는 한국어 형태소분석기입니다. 기본적으로 java와 scala 인터페이스를 제공합니다. 사전이 패키지 내에 포함되어 있기 때문에 별도로 mecab-ko-dic을 설치할 필요가 없습니다. 특징으로는 (시스템 사전에 등록되어 있는 단어에 한하여) 복합명사 분해와 활용어 원형 찾기가 가능합니다. (속도도 빨라요)
- License: Apache 2.0
arirang
- URL: https://github.com/HowookJeong/elasticsearch-analysis-arirang
- 설명: korean analyzer (lucene analyzer kr arirang)
- License: as-is
open-korean-text
- URL: https://github.com/open-korean-text/open-korean-text
- 설명: 오픈소스 한국어 처리기 (Official Fork of twitter-korean-text)
스칼라로 쓰여진 한국어 처리기입니다. 현재 텍스트 정규화와 형태소 분석, 스테밍을 지원하고 있습니다. 짧은 트윗은 물론이고 긴 글도 처리할 수 있습니다. - License: Apache 2.0
속도를 비교할 때에는 JIT 컴파일러의 영향도 살펴보기 위해 같은 테스트를 두 번 실행했습니다. 분석 시간 측정에는 ‘time’ 명령(http://man7.org/linux/man-pages/man1/time.1.html)을 사용했습니다(부록의 at.sh, ot.sh, st.sh를 참고하시기 바랍니다). 엘라스틱서치를 실행한 직후에 한 번 실행(1st run)하고, 엘라스틱서치 재기동 없이 연이어 다시 한 번 실행(2nd run)했습니다.
< 그림 1. 텍스트 분석 시간 >
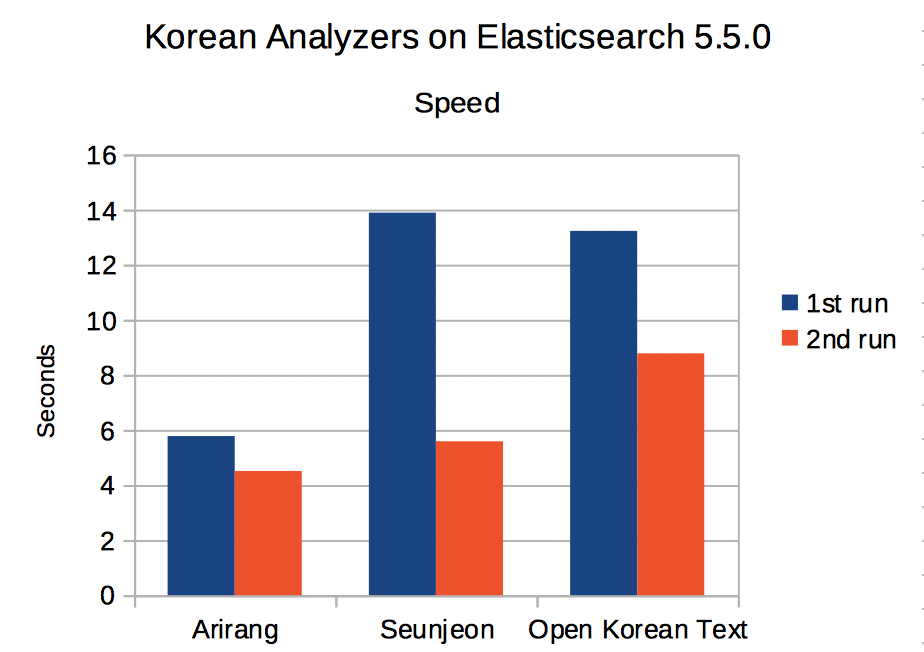
첫번째(1st run)와 두번째(2nd run) 모두 arirang이 빠른 것을 확인할 수 있습니다. seunjeon의 경우 첫번째에 비해 두번째에 많이 빨라지고, open-korean-text의 경우 seunjeon과 비슷하거나 약간 느린 성능을 보여주고 있습니다.
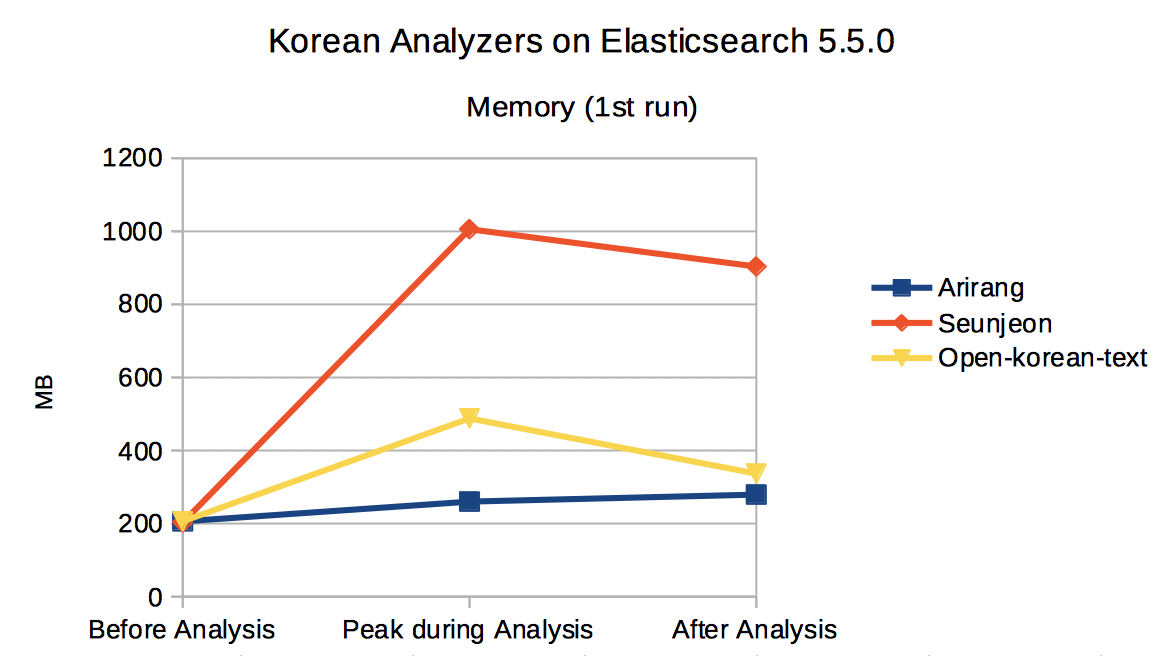
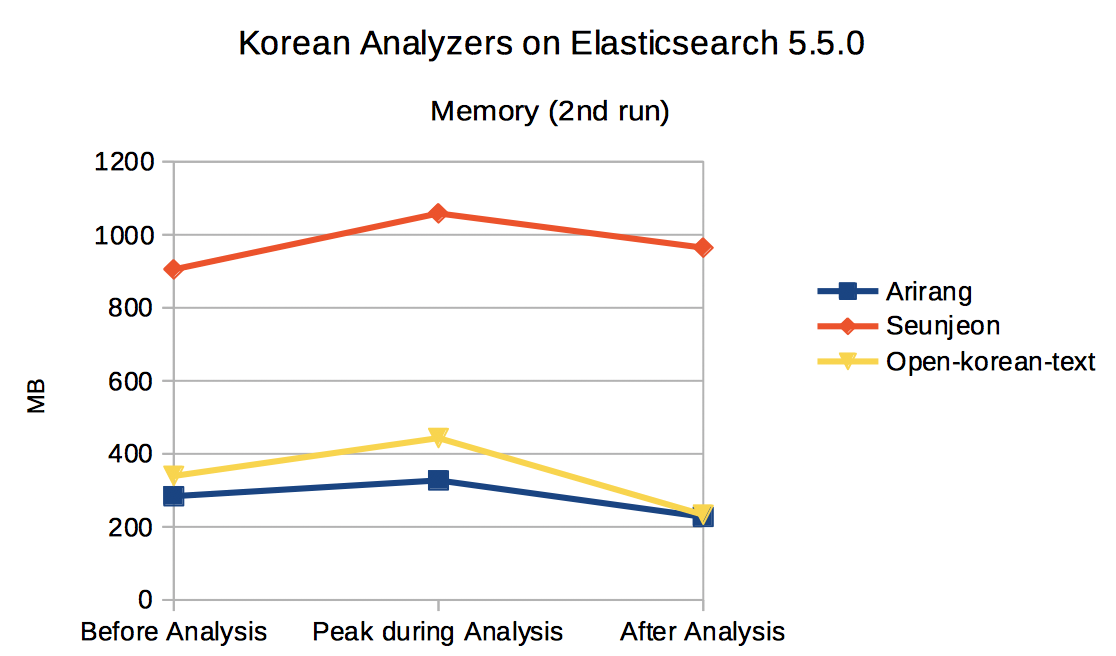
메모리 사용량은 분석 직전 자바 힙 메모리 사용량, 분석 중 최대 사용량, 분석 직후 사용량으로 나누어 측정했습니다. 메모리 사용량 측정에는 ‘jstat -gc’ 명령(https://docs.oracle.com/javase/8/docs/technotes/tools/unix/jstat.html)을 사용했습니다(부록의 am.sh, om.sh, sm.sh를 참고하시기 바랍니다). 역시 같은 테스트를 두 번 실행했습니다. 엘라스틱서치를 실행한 직후에 한 번 실행(1st run)하고, 엘라스틱서치 재기동 없이 연이어 다시 한 번 실행(2nd run)했습니다. Arirang이 분석 전, 중, 후 모두 큰 차이 없는 자바 힙 메모리 사용량을 보이는 데 비해 seunjeon의 경우 분석 중 급격히 사용량이 느는 것을 볼 수 있습니다. 아마도 스칼라 런타임이 일정 수준의 메모리를 사용하기 때문이 아닐까 합니다. Open-korean-text는 분석 중 완만한 사용량 증가를 보이지만 분석이 끝난 뒤 거의 원상회복되는 것을 볼 수 있습니다.
< 그림 2. 텍스트 분석 중 자바힙 메모리 사용량(첫번째 실행) >
< 그림 3. 텍스트 분석 중 자바힙 메모리 사용량(두번째 실행) >
마지막으로 세 분석기의 형태소 분석 결과를 비교해 보았습니다. 원문은 훈민정음 언해 서문을 현대어로 바꾼 것입니다. 속도와 메모리 사용량 테스트에도 같은 문자열을 이용했습니다.
“나라의 말이 중국과 달라 한자와는 서로 맞지 아니할새 이런 까닭으로 어리석은 백성이 이르고자 하는 바 있어도 마침내 제 뜻을 능히 펴지 못할 사람이 많으니라 내 이를 위하여, 가엾게 여겨 새로 스물여덟 자를 만드나니 사람마다 하여금 쉽게 익혀 날마다 씀에 편안케 하고자 할 따름이니라”
< 표 1. 분석 결과 >
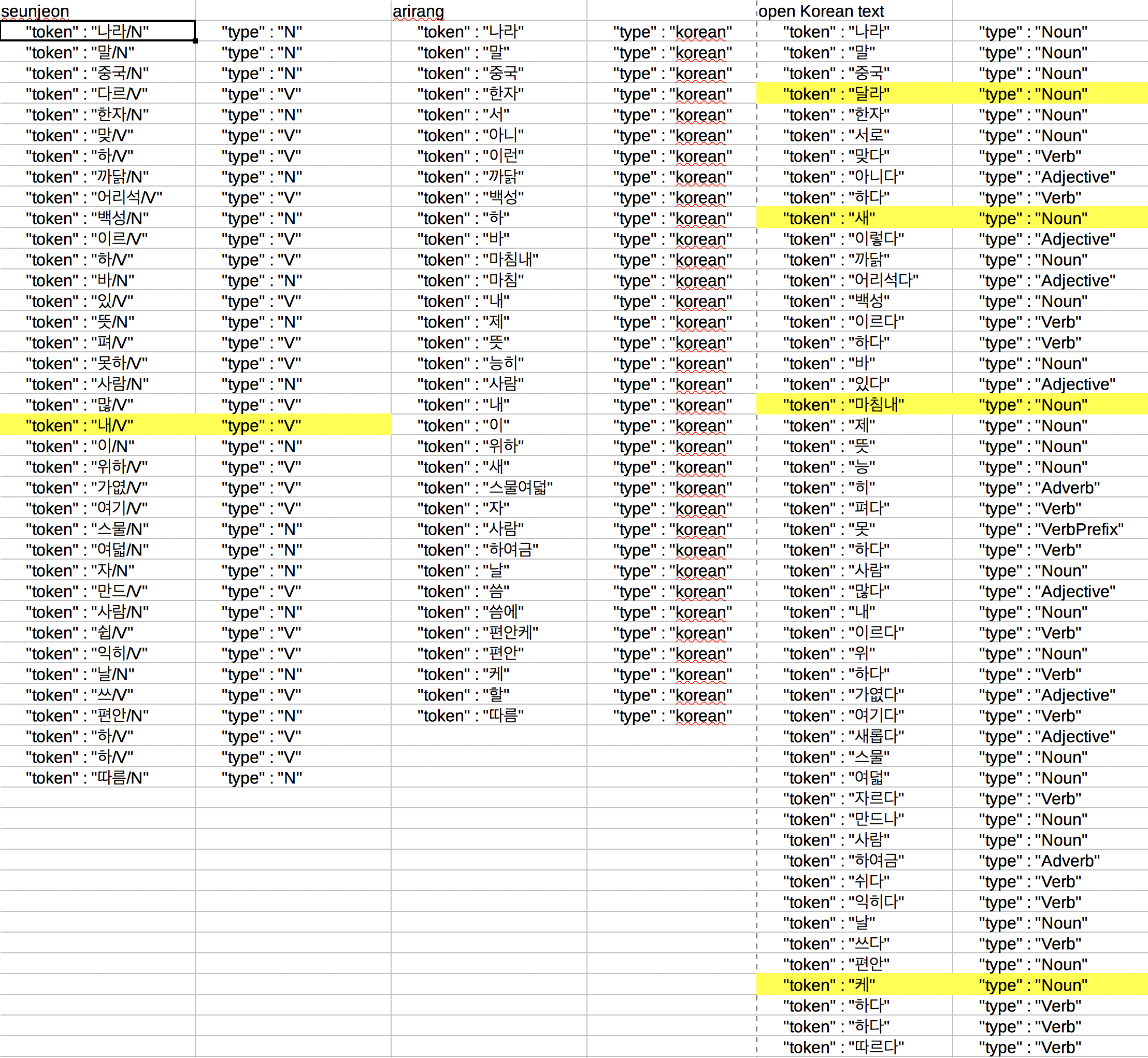
추출한 토큰의 수는 open-korean-text가 제일 많고 형용사와 동사를 구분해 줍니다만, ‘달라’, ‘새’, ‘마침내’, ‘케’를 모두 명사로 오분석하고 있습니다. Seunjeon의 경우에도 ‘내’를 동사로 오분석했습니다. Arirang은 품사 정보를 전혀 제공하지 않습니다.
그럼 형태소 분석기의 실행 시간과 메모리 사용량은 전체 인덱싱 실행 시간과 메모리 사용량에서 어느 정도의 비중을 차지할까요? Seunjeon으로 테스트해 보았습니다. 전체 인덱싱 시간은 첫번째 실행시 29.036초, 두번째 실행시 20.952초로, 형태소 분석 시간은 전체 인덱싱 시간 중 각각 47.83%와 26.67%를 차지했습니다. 실행 중 최대 메모리 사용량과 실행 전 메모리 사용량의 차이는 분석만 수행 시 802MB, 인덱싱 시 853MB로, 역시 형태소 분석기가 사용하는 메모리의 비중이 상당함을 알 수 있습니다. 참고로, 분석 시간은 검색보다는 인덱싱 시간에 더 많은 영향을 줍니다. 검색 시에는 이미 인덱스된 긴 문장은 분석하지 않고 짧은 키워드만을 분석하기 때문입니다.
지금까지 엘라스틱서치용 한국어 형태소 분석기들을 비교해 봤습니다. 속도, 자바 힙 메모리 사용량, 형태소 분석 결과를 살펴봤을 때 어느 하나가 압도적으로 좋다라고 말하기는 어려운 것 같습니다. 예를 들어 속도와 메모리 사용량이 중요한 경우에는 arirang이 좋은 솔루션이 될 수 있겠지만 품사 정보가 필요한 경우에는 seunjeon이나 open-korean-text를 사용해야 할 것입니다. 다만 총 인덱싱 시간과 메모리 사용량에 형태소 분석기가 차지하는 비중이 상당함을 생각하면, 엘라스틱서치 클러스터를 구성할 때 한국어 형태소 분석기의 선택이 중요함을 잊지 않아야 하겠습니다.
부록 (scripts.tar.bz2)
- seunjeon, arirang, open-korean-text 속도 측정 스크립트(st.sh, at.sh, and ot.sh)
- seunjeon, arirang, open-korean-text 메모리 사용량 측정 스크립트(sm.sh, am.sh, and om.sh)
- seunjeon 인덱싱 속도 측정 스크립트(sit.sh)
- seunjeon 인덱싱 중 메모리 사용량 측정 스크립트(sim.sh)