머신 러닝 변칙 점수 평가와 Elasticsearch, 그 작동 방법
편집자 노트(2021년 8월 3일): 이 포스팅은 더 이상 사용되지 않고 앞으로는 사라지게 될 기능을 사용합니다. 현재 지침은 리버스 지오코딩을 통한 사용자 정의 리전 매핑 설명서를 참조하세요.
Elastic의 머신 러닝 “변칙 점수”와 대시보드에 표시되는 다양한 점수가 데이터 세트 내에 있는 각 발생 사건의 “비정상성”과 어떤 관련이 있는지에 대한 질문을 종종 받곤 합니다. 변칙 점수가 어떻게 계산되고 제시되는지, 그리고 사용자가 어떻게 그 점수를 사전예방적인 알림의 지표로 이용하게 되는지를 이해하는데 큰 도움이 될 수 있을 것입니다. 이 블로그가 완벽한 전체 가이드가 될 수는 없겠지만, 머신 러닝(ML)이 점수를 매기는 방법에 대해 실제적인 정보를 가능한 한 많이 설명해 드리고자 합니다.
제일 먼저 알아두어야 할 사항은 “비정상성"(및 궁극적으로는 점수)에 대해 생각해 볼 수 있는 세 가지의 각기 다른 방법이 있다는 점입니다. 바로 각 변칙(“레코드")에 대한 점수, 사용자 또는 IP 주소와 같은 엔티티(“인플루언서")에 대한 점수, 그리고 시간 창(“버킷")에 대한 점수입니다. 이 다른 점수들이 일종의 계층 구조 내에서 서로 어떻게 관련되는지도 살펴 보겠습니다.
레코드 점수 평가
첫 번째 유형의 점수는 계층 구조 중 제일 낮은 수준에 있는데, 발생한 특정 인스턴스가 완전히 비정상인 경우입니다. 예:
- 사용자에 대한 로그인 실패율=관리자가 지난 1분 동안 300회의 실패를 관찰했음
- 특정 미들웨어 호출에 대한 응답 시간 값이 보통 때보다 300% 급증했음
- 오늘 오후에 처리되고 있는 주문의 수가 통상적인 목요일 오후의 경우보다 훨씬 낮음
- 어느 원격 IP 주소로 전송되고 있는 데이터의 양이 다른 원격 IP로 전송되고 있는 양보다 훨씬 많음
위의 발생 사건은 각각 계산된 개연성을 갖는데, 이것은 해당 항목에 대해 기준선 개연성 모델을 구축한 과거의 관찰된 행동을 바탕으로 대단히 정교하게 계산된 값입니다(1e-308 정도로 작은 값까지 계산됩니다). 그러나, 이 원시 개연성 값은 확실히 유용하긴 하지만 다음과 같은 일부 상황 정보가 부족할 수 있습니다.
- 현재 변칙 행동이 과거의 변칙과 어떻게 비교되는가? 과거의 변칙보다 비정상성이 더 높은가, 아니면 더 낮은가?
- 이 항목의 변칙성은 잠재적으로 변칙적인 다른 항목(다른 사용자, 다른 IP 주소 등)과 어떻게 비교되는가?
그러므로 사용자가 좀더 쉽게 이해하고 우선순위를 정할 수 있도록 ML은 개연성을 정규화하여 0~100의 척도에서 항목의 변칙성 순위를 매깁니다. 이 값은 UI에서 “변칙 점수"로 제시됩니다.
추가적인 맥락을 제공하기 위해, UI는 그 점수에 따라 변칙에 네 개의 “심각도" 라벨 중 하나를 붙입니다. 75점에서 100점 사이이면 “심각함(critical)", 50점에서 75점 사이이면 “중대함(major)", 25점에서 50점 사이이면,“가벼움(minor)", 0점에서 25점 사이이면 “경고(warning)"에 해당되며, 각 심각도는 다른 색깔로 표시됩니다.
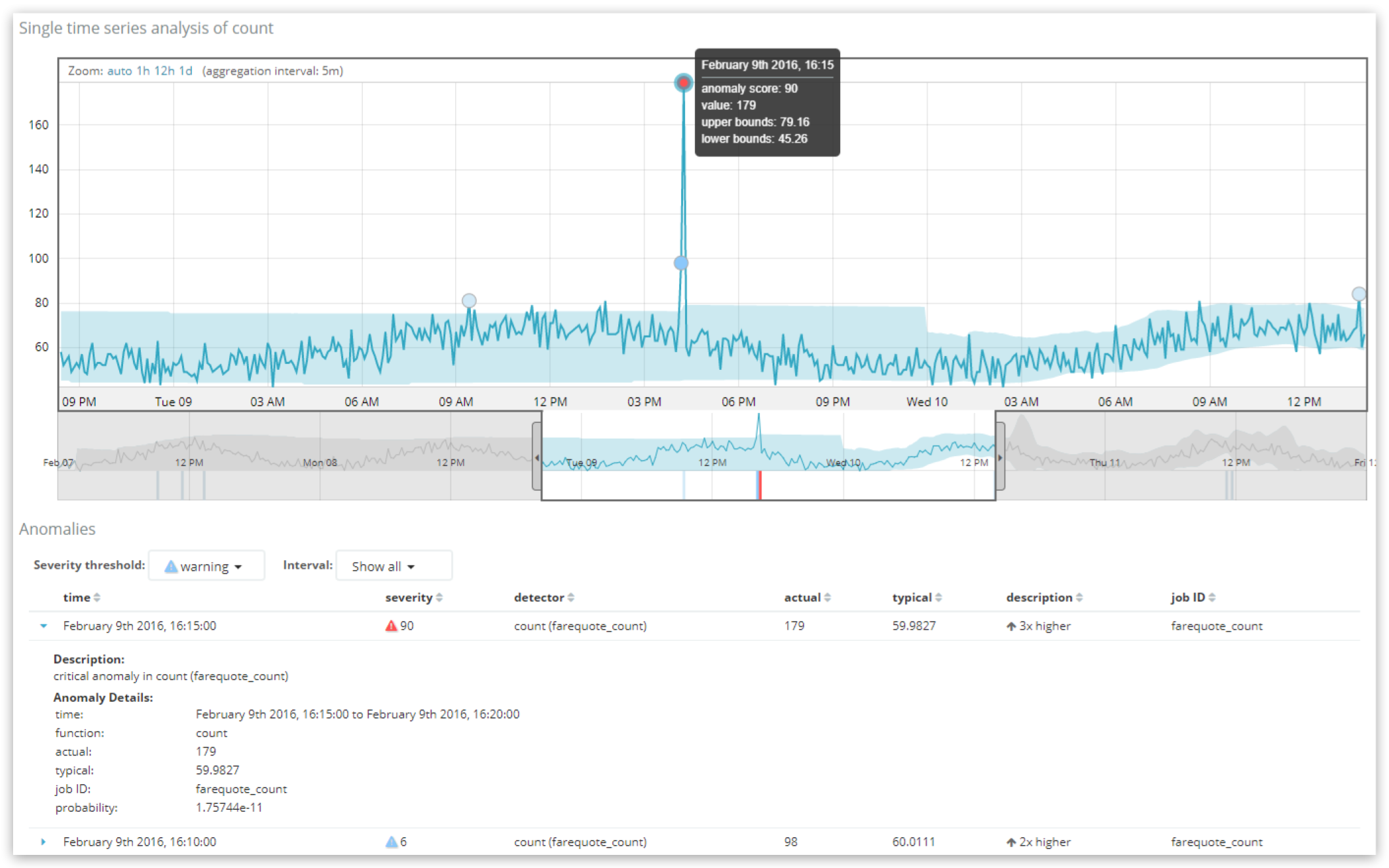
여기에서 단일 메트릭 탐색기에 표시되는 두 개의 변칙 기록을 볼 수 있습니다. 점수가 90점인 “심각한" 변칙으로 가장 변칙적인 레코드입니다. 표 위에 있는 “심각도 임계값(Severity threshold)" 컨트롤은 심각도가 더 높은 변칙 표를 필터링하는 데 사용할 수 있으며, “인터벌(Interval)" 컨트롤은 레코드를 그룹화하여 시간당 또는 하루당 최고 점수 레코드를 표시하는 데 사용할 수 있습니다.
특정한 5분 시간 버킷의 변칙에 대한 정보를 요청하기 위해 ML의 API에서 레코드 결과에 대한 쿼리를 하려는 경우(작업 이름은 farequote_count),
GET /_xpack/ml/anomaly_detectors/farequote_count/results/records?human
{
"sort": "record_score",
"desc": true,
"start": "2016-02-09T16:15:00.000Z",
"end" :"2016-02-09T16:20:00.000Z"
}
다음과 같은 출력을 보게 됩니다.
{
"count": 1,
"records": [
{
"job_id": "farequote_count",
"result_type": "record",
"probability": 1.75744e-11,
"record_score": 90.6954,
"initial_record_score": 85.0643,
"bucket_span": 300,
"detector_index": 0,
"is_interim": false,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"function": "count",
"function_description": "count",
"typical": [
59.9827
],
"actual": [
179
]
}
]
}
여기서 이 5분 인터벌(작업의 bucket_span) 동안 record_score가 90.6954점(100점 만점)이고 원시 '개연성`은 1.75744e-11이라는 것을 볼 수 있습니다. 이 말은 이 특정한 5분 인터벌의 데이터 용량이 “통상적으로" 훨씬 낮으며, 60에 가깝기 때문에 179개 문서의 실제 비율을 가질 가능성이 거의 없다는 뜻입니다.
여기서 값이 UI에서 사용자에게 표시되는 것과 어떻게 매핑하는지 보세요. 개연성 값 1.75744e-11은 아주 작은 숫자이며, 발생했을 가능성이 대단히 낮다는 뜻이지만, 숫자의 척도가 직관적이 아닙니다. 0부터 100까지의 척도로 나타내는 것이 훨씬 유용한 것도 바로 이 때문입니다. 이 정규화를 처리하는 프로세스가 독점적이긴 하지만, 거의 분위수 분석을 기반으로 합니다. 이 분위수 분석에서는 이 작업에 대해 그동안 나타난 개연성 값들이 서로 순위가 매겨집니다. 간단히 말해, 기록상 해당 작업에 대해 가장 낮은 개연성이 가장 높은 변칙 점수를 갖습니다.
변칙 점수가 UI의 “설명" 열에서 얘기하는 편차(여기서는 “3배 이상”)와 직접 관련되어 있다고 흔히 오해하기도 합니다. 변칙 점수는 순전히 개연성 계산만 거친 것입니다. “설명"과 “통상적인" 값조차도 변칙을 좀더 이해하기 쉽게 하기 위해 상황 정보를 간소화한 것입니다.
인플루언서 점수
지금까지 개별 레코드의 점수에 대한 개념을 설명해 드렸습니다. 비정상성을 고려하는 두 번째 방법은 변칙에 영향을 미쳤을 수도 있는 엔티티의 순위나 점수를 매기는 것입니다. ML에서는 이렇게 영향을 미치는 엔티티를 “인플루언서"라고 합니다. 위의 예에서는, 분석이 너무 간단해서 인플루언서를 가질 수가 없습니다. 단일 시간 연속 밖에 없었죠. 좀더 복잡한 분석에서는, 변칙의 존재에 영향을 미치는 잠재적인 부수적 필드가 있습니다.
예를 들어, 사용자의 인터넷 활동 인구 분석에서, ML 작업은 전송된 비정상적인 바이트와 방문한 비정상적인 도메인을 살펴보는데, 변칙(무엇인가가 대상 도메인으로 해당 바이트를 전송하고 있어야 합니다)이 존재하는 “원인이 되는" 엔티티이기 때문에 “사용자"를 잠재적인 인플루언서로 지정할 수 있을 것입니다. 각 시간 인터벌 동안 각 사용자가 이 영역 중 하나 또는 양쪽 모두(전송된 바이트와 방문한 도메인)에서 얼마나 변칙적으로 여겨지는지에 따라, 인플루언서 점수가 각 사용자에게 주어지게 됩니다.
인플루언서 점수가 높을수록, 엔티티가 변칙에 영향을 미쳤거나 변칙의 원인일 가능성이 높습니다. 이것은 ML 결과를 해석할 수 있는 강력한 기능을 제공합니다. 특히, 하나 이상의 탐지자가 있는 작업의 경우에는 더욱 그렇습니다.
모든 ML 작업에서, 작업의 생성 중에 추가되는 모든 인플루언서에 더해 언제나 추가로 `bucket_time’이라고 부르는 기본 제공 인플루언서가 생성됩니다. 이것은 버킷의 모든 레코드 집계를 사용합니다.
인플루언서의 예를 직접 보여드리기 위해, ML 작업이 항공요금 견적 엔진에 대한 API 응답 시간 호출의 데이터 세트에서 두 개의 탐지자와 함께 설정되어 있습니다.
항공사’에서 분할되고/파티션된 API 호출수`항공사’에서 분할되고/파티션된 API 호출평균(응답 시간)`
항공사는 인플루언서로 지정되어 있습니다.
“변칙 탐색기”에서 결과를 살펴보면,
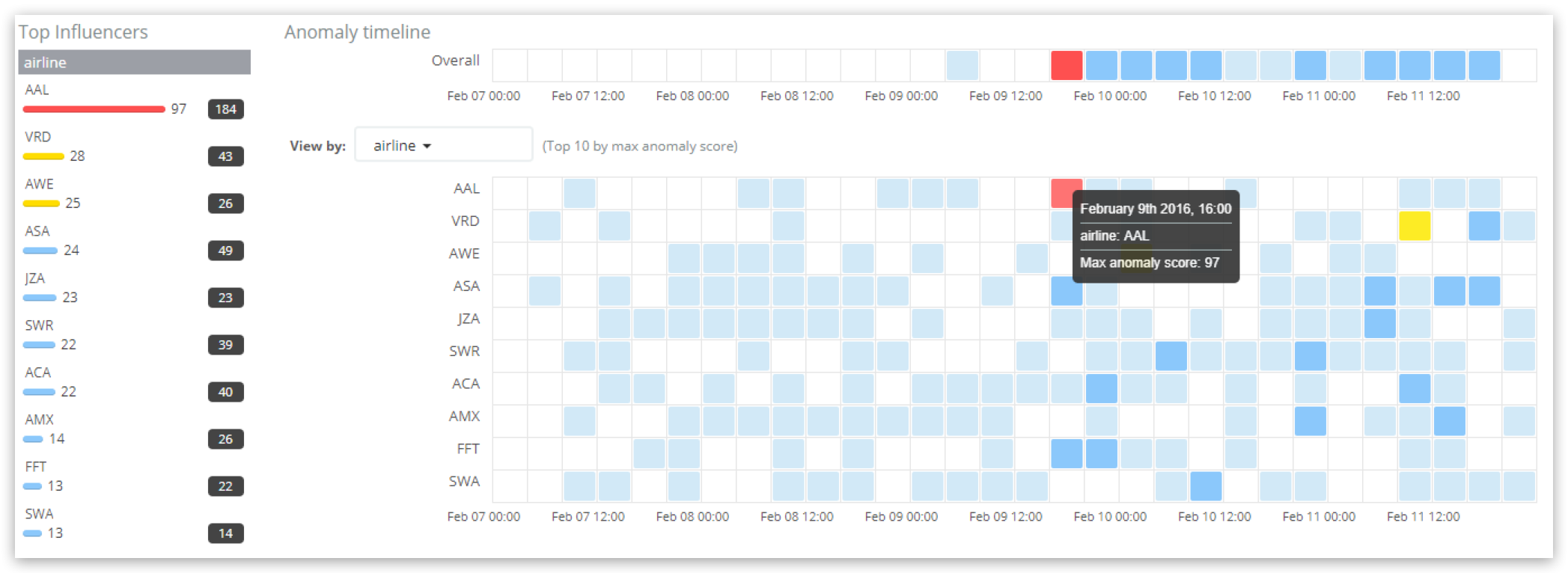
대시보드에서 선택한 시간이 경과하면서 가장 점수가 높은 인플루언서는 왼쪽의 “최고점 인플루언서(Top influencers)” 섹션에 목록이 나타납니다. 각 인플루언서마다, 대시보드 시간 범위에 걸쳐 인플루언서 총점과 함께 최대 인플루언서 점수(모든 버킷에서)가 표시됩니다(모든 버킷에 걸쳐 합산). 여기서는, “AAL” 항공사가 인플루언스 점수 97점으로 최고점이고, 전체 시간 범위에 걸쳐 인플루언서 총점 합계 184점입니다. 메인 타임라인에서 인플루언서별 결과를 보여주며, 최고점 인플루언서 항공사는 강조표시가 되어, 다시 97점을 보여줍니다. AAL 항공사의 “변칙" 차트와 표에서 표시되는 점수는 개별 변칙의 “레코드 점수"를 표시하기 때문에 그 인플루언서 점수와는 다릅니다.
인플루언서 수준에서 API 쿼리 작업을 할 때,
GET _xpack/ml/anomaly_detectors/farequote_count_and_responsetime_by_airline/results/influencers?human
{
"start": "2016-02-09T16:15:00.000Z",
"end" :"2016-02-09T16:20:00.000Z"
}
다음 정보가 반환됩니다.
{
"count": 2,
"influencers": [
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "influencer",
"influencer_field_name": "airline",
"influencer_field_value": "AAL",
"airline": "AAL",
"influencer_score": 97.1547,
"initial_influencer_score": 98.5096,
"probability": 6.56622e-40,
"bucket_span": 300,
"is_interim": false,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000
},
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "influencer",
"influencer_field_name": "airline",
"influencer_field_value": "AWE",
"airline": "AWE",
"influencer_score": 0,
"initial_influencer_score": 0,
"probability": 0.0499957,
"bucket_span": 300,
"is_interim": false,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000
}
]
}
출력에는 변칙 탐색기 UI에 표시되는 값을 반영하는 influencer_score 97.1547점(반올림해서 97점)과 함께 AAL 항공사에 영향을 미친 결과가 포함됩니다. 개연성 값 6.56622e-40은 이번에도 influencer_score (정규화되기 전)의 근거가 되며, 특정 항공사가 영향을 미치는 개별 변칙의 개연성과 그것이 영향을 미치는 정도를 고려합니다.
또한 결과에는 initial_influencer_score 98.5096점이 포함되어 있는데, 이 점수는 결과가 처리될 때 점수입니다. 차후에 정규화를 통해 이 점수는 97.1547점으로 약간 조정됩니다. 이것은 ML 작업이 시간 순으로 데이터를 처리하며 결코 이전의 원시 데이터로 돌아가 다시 읽고 분석/검토하지 않기 때문에 발생합니다. 또한 두 번째 인플루언서인 AWE 항공 또한 식별되었지만, 그 인플루언서 점수가 너무 낮아서(반올림해서 0) 실제적으로는 무시되어야 한다는 점을 눈여겨 보세요.
influencer_score가 여러 탐지자에 걸쳐 집계된 보기이기 때문에, API가 응답 시간의 수나 평균에 대해 실제적인 또는 통상적인 값을 반환하지 않는다는 점을 보게 됩니다. 이 상세 정보를 이용해야 하는 경우, 위에 나와 있는 대로, 동일한 시간대에 대해 레코드 결과로서 계속 이용할 수 있습니다.
버킷 점수
비정상성에 대해 점수를 매기는 마지막 방법은 계층 구조의 맨 위에 있으며, 시간, 특히 ML 작업의 bucket_span에 중점을 둡니다. 비정상적인 일들이 특정 시간에 발생하며 하나 이상의 (또는 많은) 항목들이 (동일한 버킷 내에서) 한꺼번에 동시에 비정상적일 수 있습니다.
그러므로, 시간 버킷의 변칙성은 여러 가지에 달려 있습니다.
- 해당 버킷 내에서 발생하는 개별 변칙(레코드)의 규모
- 해당 버킷 내에서 발생하는 개별 변칙(레코드)의 수 작업이 byfields 및/또는 partitionfields를 사용하여 “분할"되는 경우, 또는 작업에 여러 탐지자가 존재하는 경우 이것은 다수가 될 수 있습니다.
버킷 점수 이면의 계산은 모든 개별 변칙 레코드 점수의 간단한 평균보다 더 복잡하지만, 각 버킷의 인플루언스 점수로부터 영향을 받게 된다는 점에 주목해 주세요.
지난 예에서 살펴본, 탐지자가 두 개인 ML 작업으로 다시 돌아가 보면,
항공사’에서 분할되고/파티션된수`항공사’에서 분할되고/파티션된평균(응답 시간)`
“변칙 탐색기”에서 볼 때,
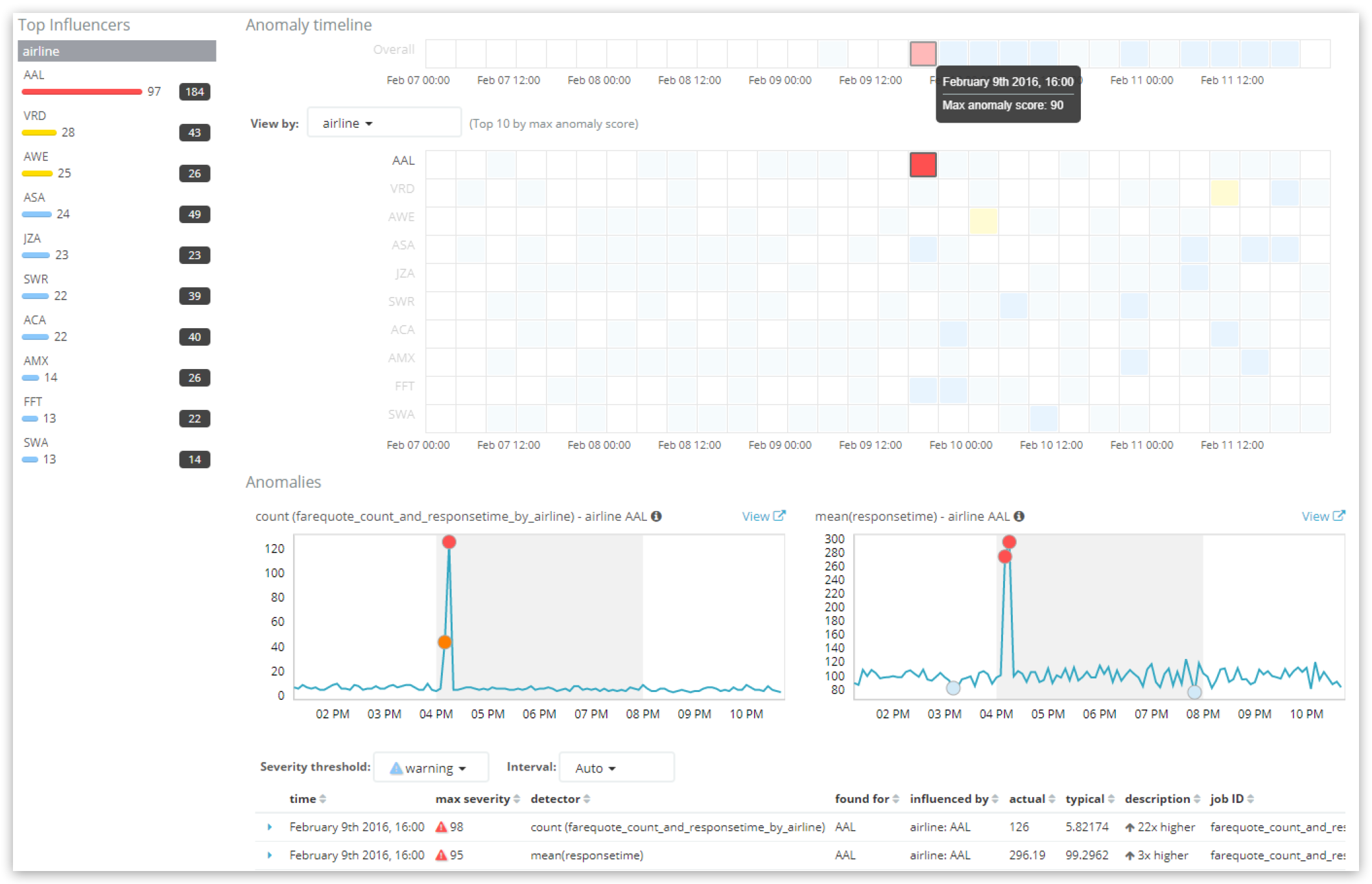
보기 맨 위에 있는 “변칙 타임라인”의 “전체" 래인이 버킷에 대한 점수를 표시한다는 것을 알 수 있습니다. 하지만 주의해야 합니다. UI에서 선택되는 시간 범위가 넓지만 ML 작업의 bucket_span이 상대적으로 짧다면, UI의 “타일" 한 개는 실제로 여러 버킷이 합쳐진 것일 수도 있습니다.
위에 표시된 선택된 타일의 점수는 90점이며, 이 버킷에는 각 탐지자 당 하나씩, 레코드 점수 98점과 95점인 두 개의 심각한 레코드 변칙이 있습니다.
버킷 수준에서 API 쿼리 작업을 할 때,
GET _xpack/ml/anomaly_detectors/farequote_count_and_responsetime_by_airline/results/buckets?human
{
"start": "2016-02-09T16:15:00.000Z",
"end" :"2016-02-09T16:20:00.000Z"
}
다음 정보가 표시됩니다.
{
"count": 1,
"buckets": [
{
"job_id": "farequote_count_and_responsetime_by_airline",
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"anomaly_score": 90.7,
"bucket_span": 300,
"initial_anomaly_score": 85.08,
"event_count": 179,
"is_interim": false,
"bucket_influencers": [
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "bucket_influencer",
"influencer_field_name": "airline",
"initial_anomaly_score": 85.08,
"anomaly_score": 90.7,
"raw_anomaly_score": 37.3875,
"probability": 6.92338e-39,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"bucket_span": 300,
"is_interim": false
},
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "bucket_influencer",
"influencer_field_name": "bucket_time",
"initial_anomaly_score": 85.08,
"anomaly_score": 90.7,
"raw_anomaly_score": 37.3875,
"probability": 6.92338e-39,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"bucket_span": 300,
"is_interim": false
}
],
"processing_time_ms": 17,
"result_type": "bucket"
}
]
}
특히, 다음 출력을 눈여겨 보세요.
anomaly_score- 전체적으로 집계된 정규화된 점수(여기서는 90.7점)initial_anomaly_score- 버킷이 처리된 시점의anomaly_score(역시, 나중에 정규화를 통해 원래 값에서anomaly_score를 변경한 경우).initial_anomaly_score는 UI 어디에도 표시되지 않습니다.bucket_influencers- 이 버킷에서 표시되는 다수의 인플루언서 유형. 위에서 인플루언서에 대해 얘기했듯이, 이 어레이에는influencer_field_name:airline과influencer_field_name:bucket_time(언제나 기본 제공 인플루언서로 추가됨) 양쪽 모두에 대한 입력사항이 포함되어 있습니다. 특정한 인플루언서 값의 세부사항(즉, 어느 항공사인지)은 앞서 표시된 대로, 구체적으로 인플루언서나 레코드 값에 대해 API를 쿼리 작업할 때 제공됩니다.
알림에 변칙 점수 사용하기
그렇다면 세 개의 기본 점수(개별 레코드 점수, 인플루언서 점수, 시간 버킷 점수) 중 어느 것이 알림에 유용할까요? 답은 사용자가 목표로 하는 것, 사용자가 받고자 하는 알림의 입도와 비율에 따라 달라진다는 것입니다.
한편으로는 사용자가 시간 기능으로서 전체적인 데이터 세트에서 현저한 편차에 대해 감지하고 알림을 받고자 한다면, 버킷 기반의 변칙 점수가 가장 유용할 것입니다. 시간이 흐르면서 가장 비정상적인 엔티티에 대해 알림을 받고자 하는 경우에는 influencer_score’를 사용하는 것을 고려해 봐야 합니다. 또는 시간 창 내에서 가장 비정상적인 변칙을 감지하고 알림을 받고자 한다면, 보고 또는 알림의 기반으로 개별record_score`를 사용하는 것이 가장 좋을 수 있습니다.
알림의 과부하를 피하려면, 버킷 기반 변칙 점수를 사용할 것을 권장합니다. 비율 제한이 있기 때문에, bucketspan 당 1개 이상의 알림을 받지 않을 것입니다. 반면, `recordscore’를 사용하는 알림에 중점을 둔다면,단위 시간 당 변칙 기록 수가 임의적이라서, 알림이 많아질 수도 있습니다. 개별 레코드 점수를 사용하여 알림을 하는 경우 염두에 두시기 바랍니다.
추가 자료:
Elasticsearch v5.5의 머신 러닝 작업 알림Elasticsearch 머신 러닝의 버킷 스팬 설명결과 리소스, 머신 러닝 문서