Attribution de scores d'anomalies pour Machine Learning et Elasticsearch - Comment ça marche ?
Remarque de l'éditeur (3 août 2021) : Cet article utilise des fonctionnalités obsolètes. Veuillez consulter la documentation sur le mappage de régions personnalisées avec le géocodage inverse pour obtenir des instructions en vigueur.
On nous pose souvent des questions à propos du système d'attribution de "scores d'anomalies" de la fonctionnalités Machine Learning d'Elastic (ML), et du rapport entre les divers scores présentés dans les tableaux de bord et le "caractère inhabituel" des occurrences individuelles dans l'ensemble de données. Il peut s'avérer très utile de comprendre comment les scores d'anomalies se manifestent, ce dont ils dépendent et comment ils peuvent servir d'indicateurs pour des alertes proactives. Ce blog, bien qu'il ne soit pas un guide exhaustif et définitif, vise à vous fournir des informations pratiques à propos de la façon dont Machine Learning (ML) attribue ces scores.
Il faut d'abord rappeler qu'il existe trois façons distinctes d'envisager (et donc d'évaluer) le "caractère inhabituel", à savoir l'attribution d'un score à une anomalie individuelle (un "enregistrement"), l'attribution d'un score à une entité, telle qu'un utilisateur ou une adresse IP (un "influenceur"), et l'attribution d'un score à un laps de temps (un "intervalle"). Nous verrons également quel est le lien entre ces différents scores dans une sorte de hiérarchie.
Attribution de scores d'enregistrements
Le premier type d'attribution de score, au niveau le plus bas de la hiérarchie, correspond au caractère absolument inhabituel d'une instance précise d'une chose se produisant. Par exemple :
- Le nombre d'échecs de connexion pour user=admin était de 300 échecs au cours de la dernière minute.
- La valeur du temps de réponse pour un appel d'intergiciel spécifique vient d'augmenter de 300 % par rapport à la valeur habituelle.
- Le nombre de commandes traitées cet après-midi est bien moins élevé que d'habitude pour un jeudi après-midi classique.
- Le volume de données transféré vers une adresse IP distante est bien plus élevé que le volume transféré vers d'autres adresses IP distantes.
Chacune des occurrences ci-dessus présente une probabilité calculée, soit une valeur calculée de façon très précise (pouvant être aussi petite que 1e-308, en fonction de son comportement passé observé, qui a permis d'établir un modèle de probabilité de référence pour cet élément. Cependant, cette valeur de probabilité brute, bien qu'utile, peut manquer d'informations contextuelles, par exemple :
- Comment peut-on comparer le comportement anormal actuel aux anciennes anomalies ? Est-il plus ou moins inhabituel que les anciennes anomalies ?
- Comment peut-on comparer le caractère anormal de cet élément aux autres éléments potentiellement anormaux (autres utilisateurs, autres adresses IP, etc.) ?
Par conséquent, pour permettre à l'utilisateur de mieux comprendre les anomalies et de les classer plus facilement par priorité, ML normalise la probabilité de telle manière qu'elle classe le caractère anormal d'un élément selon une échelle de 0 à 100. Cette valeur est présentée comme le "score d'anomalie" dans l'interface utilisateur.
Afin d'offrir davantage de contexte, l'interface utilisateur associe une des quatre étiquettes de "gravité" aux anomalies en fonction de leur score. La mention "critique" concerne les scores compris entre 75 et 100, la mention "majeure" les scores de 50 à 75, la mention "mineure" les scores de 25 à 50 et la mention "avertissement" les scores de 0 à 25 ; chaque gravité étant indiquée par une couleur différente.
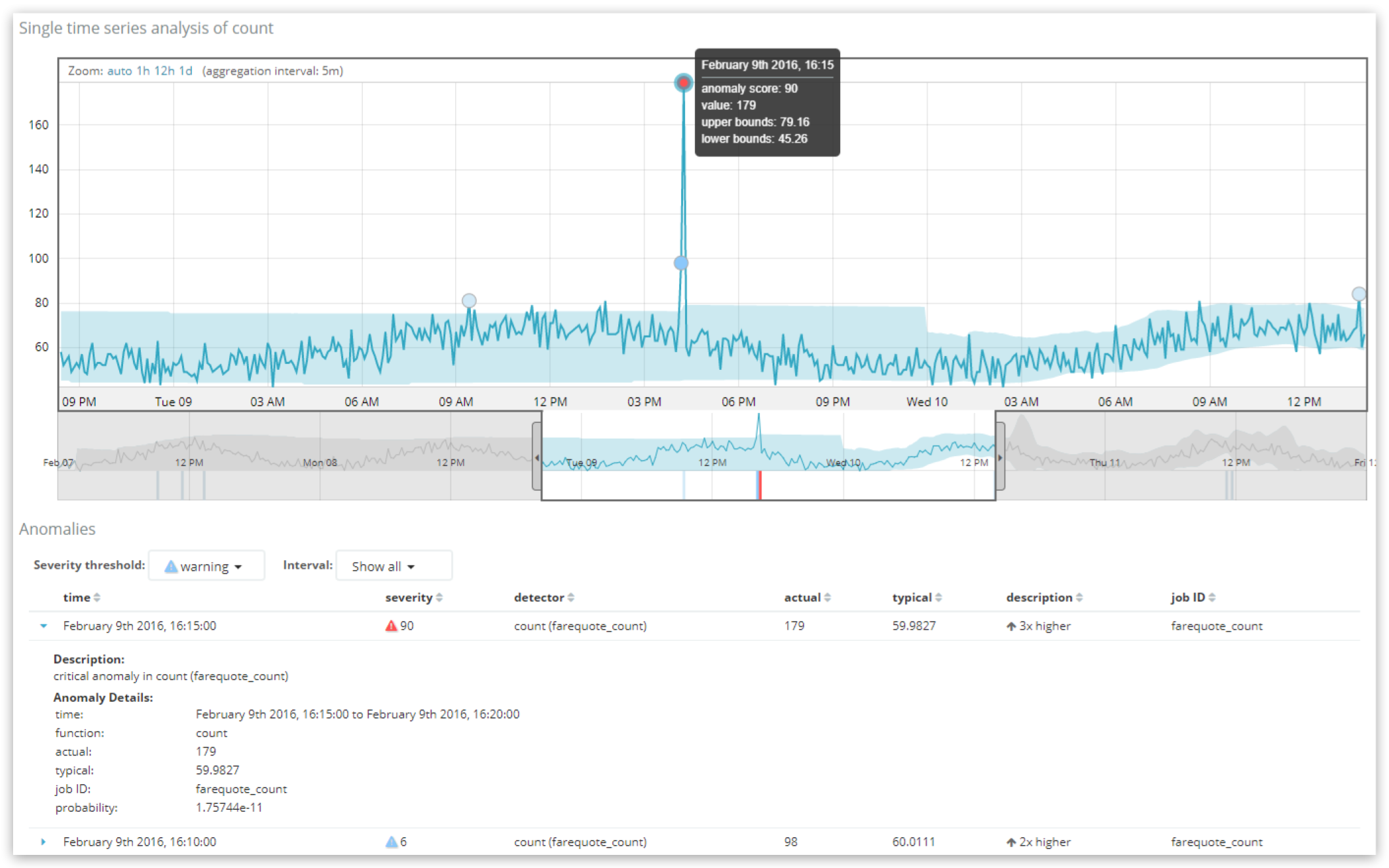
Dans notre cas, nous voyons deux enregistrements d'anomalies affichés dans la vue Single Metric Viewer, le plus anormal d'entre eux correspondant à une anomalie "critique" avec un score de 90. La commande "Severity threshold" (seuil de gravité) au-dessus du tableau peut servir à filtrer le tableau de façon à voir les anomalies les plus graves, tandis que la commande "Interval" (intervalle) peut servir à regrouper les enregistrements de manière à afficher l'enregistrement avec le score le plus élevé par heure ou par jour.
Si nous voulions rechercher des résultats d'enregistrements dans l'API de ML pour demander plus d'informations sur les anomalies d'un intervalle spécifique d'une durée de 5 minutes (où farequote_count correspondait au nom de la tâche) :
GET /_xpack/ml/anomaly_detectors/farequote_count/results/records?human
{
"sort": "record_score",
"desc": true,
"start": "2016-02-09T16:15:00.000Z",
"end" :"2016-02-09T16:20:00.000Z"
}
Nous verrions ce qui suit :
{
"count": 1,
"records": [
{
"job_id": "farequote_count",
"result_type": "record",
"probability": 1.75744e-11,
"record_score": 90.6954,
"initial_record_score": 85.0643,
"bucket_span": 300,
"detector_index": 0,
"is_interim": false,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"function": "count",
"function_description": "count",
"typical": [
59.9827
],
"actual": [
179
]
}
]
}
Dans notre cas, nous pouvons voir que, durant cet intervalle de 5 minutes (bucket_span de la tâche), l'élément record_score est de 90,6954 (sur 100) et la probability brute est de 1,75744e-11. Ce résultat signifie qu'il est très peu probable que le volume de données de cet intervalle de 5 minutes précis présente un taux réel de 179 documents, car "en règle générale", il est bien moins élevé, et plus proche de 60.
Notez la façon dont les valeurs affichées renvoient à ce que l'utilisateur voit dans l'interface utilisateur. La valeur de probability de 1,75744e-11 est un très petit chiffre, ce qui signifie qu'il est très peu probable que la situation se soit produite, mais l'échelle du chiffre n'est pas intuitive. C'est pour cette raison que nous la projetons sur une échelle de 0 à 100, qui est plus utile. Le processus qui donne naissance à cette normalisation est propriétaire, mais il se fonde essentiellement sur une analyse en quantiles dans le cadre de laquelle les valeurs de probabilité observées préalablement pour les anomalies de cette tâche sont classées les unes par rapport aux autres. Autrement dit, les probabilités les plus faibles historiquement pour la tâche obtiennent les scores d'anomalies les plus élevés.
On pense souvent, à tort, que le score d'anomalie est directement lié à l'écart exprimé dans la colonne "description" de l'interface utilisateur (ici "3x plus élevé"). Or, le score d'anomalie est strictement déterminé par le calcul de probabilité. La "description" et même la valeur de typical sont des éléments simplifiés d'informations contextuelles, dont le but est de rendre l'anomalie plus facilement compréhensible.
Attribution de scores d'influenceurs
Maintenant que nous avons parlé du concept de score d'un enregistrement individuel, la deuxième façon d'examiner le caractère inhabituel consiste à classer ou à attribuer un score aux entités susceptibles d'avoir contribué à une anomalie. Dans ML, nous appelons ces entités contributrices des "influenceurs". Dans l'exemple ci-dessus, l'analyse était trop simple pour justifier l'utilisation d'influenceurs, étant donné qu'il ne s'agissait que d'une série temporelle unique. Dans le cadre d'analyses plus complexes, il existe des champs auxiliaires potentiels qui ont une incidence sur l'existence d'une anomalie.
Par exemple, lors d'une analyse de l'activité internet d'une population d'utilisateurs, dans le cadre de laquelle la tâche de ML vérifie les octets inhabituels envoyés et les domaines inhabituels visités, vous pourriez indiquer l'élément "utilisateur" en tant qu'influenceur potentiel, étant donné qu'il s'agit de l'entité "à l'origine" de l'existence de l'anomalie (quelque chose doit envoyer ces octets à un domaine de destination). Un score d'influenceur est alors envoyé à chaque utilisateur, selon le niveau d'anormalité déterminé dans l'un de ces domaines ou les deux (octets envoyés et domaines visités) au cours de chaque intervalle.
Plus le score d'influenceur est élevé et plus l'entité a contribué aux anomalies, ou en est responsable. Ce score donne davantage d'informations sur les résultats de ML, notamment pour les tâches présentant plusieurs détecteurs.
Notez que, pour toutes les tâches de ML, un influenceur intégré appelé bucket_time est systématiquement créé en plus des influenceurs potentiels ajoutés lors de la création de la tâche. Pour ce faire, on utilise une agrégation de tous les enregistrements de l'intervalle.
Pour présenter un exemple d'influenceur, une tâche de ML est créée avec deux détecteurs sur un ensemble de données d'appels présentant un temps de réponse d'API pour un moteur de soumission de tarifs de billets de compagnies aériennes :
count(nombre) des appels d'API, fractionné/partitionné en fonction deairline(compagnie aérienne) ;mean(responsetime)des appels d'API, fractionné/partitionné en fonction de laairline(compagnie aérienne).
Dans cet exemple, la airline (compagnie aérienne) est indiquée comme étant un influenceur.
Analyse des résultats dans "Anomaly Explorer" :
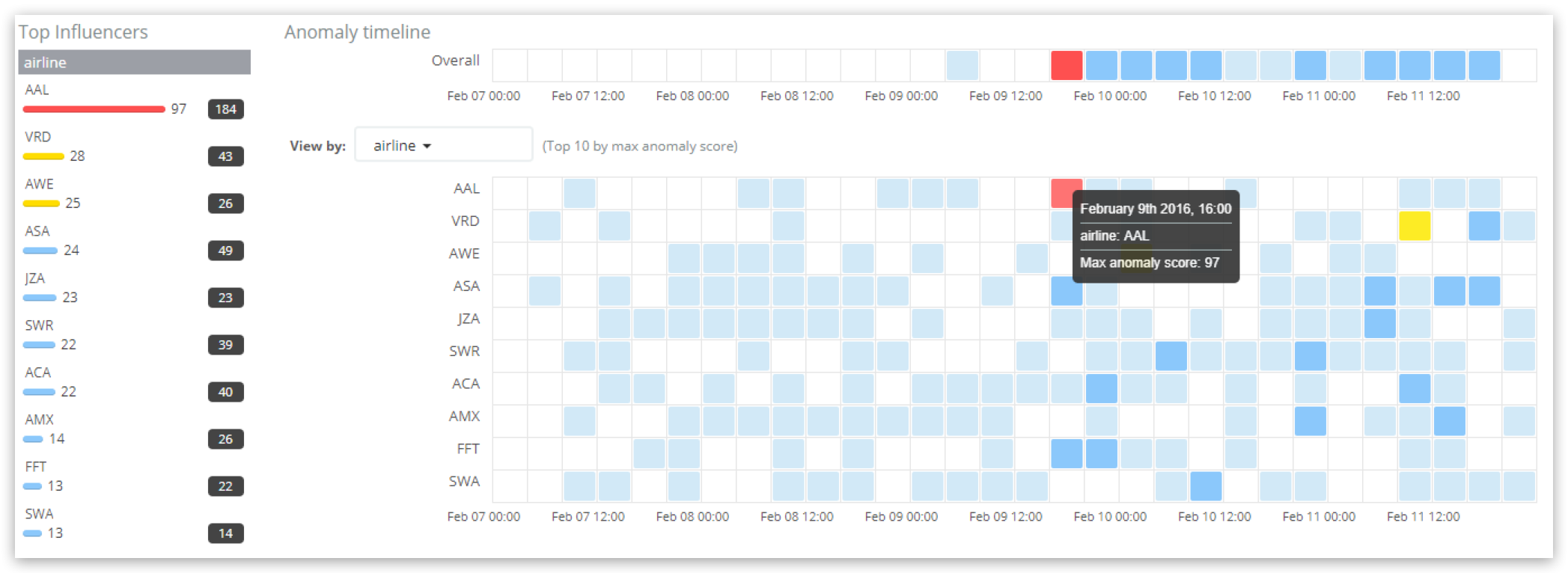
La section "Top Influencers" (principaux influenceurs) à gauche présente les principaux influenceurs des scores pour l'intervalle de temps sélectionné dans le tableau de bord. Pour chaque influenceur, on indique le score d'influenceur maximum (dans un intervalle), ainsi que le score d'influenceur total pour la période sélectionnée dans le tableau de bord (somme de tous les intervalles). Dans notre cas, la compagnie aérienne "AAL" présente le score d'influenceur le plus élevé, à savoir 97, ainsi qu'un score d'influenceur total de 184 sur l'ensemble de la période choisie. Le calendrier principal affiche les résultats par influenceur et la compagnie aérienne qui présente le score d'influenceur le plus élevé s'affiche ; le score de 97 est à nouveau renvoyé. Notez les scores indiqués dans les graphiques "Anomalies" et vous verrez que le tableau de la compagnie aérienne AAL n'indique pas la même chose que son score d'influenceur, étant donné qu'il affiche les "scores d'enregistrements" des anomalies individuelles.
Lorsque vous interrogez l'API au niveau des influenceurs :
GET _xpack/ml/anomaly_detectors/farequote_count_and_responsetime_by_airline/results/influencers?human
{
"start": "2016-02-09T16:15:00.000Z",
"end" :"2016-02-09T16:20:00.000Z"
}
les informations suivantes s'affichent :
{
"count": 2,
"influencers": [
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "influencer",
"influencer_field_name": "airline",
"influencer_field_value": "AAL",
"airline": "AAL",
"influencer_score": 97.1547,
"initial_influencer_score": 98.5096,
"probability": 6.56622e-40,
"bucket_span": 300,
"is_interim": false,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000
},
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "influencer",
"influencer_field_name": "airline",
"influencer_field_value": "AWE",
"airline": "AWE",
"influencer_score": 0,
"initial_influencer_score": 0,
"probability": 0.0499957,
"bucket_span": 300,
"is_interim": false,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000
}
]
}
La sortie contient un résultat correspondant à la compagnie aérienne AAL déterminante, l'élément influencer_score de 97,1547 reflétant la valeur affichée dans l'interface utilisateur "Anomaly Explorer" (arrondi à 97). La valeur de probability de 6,56622e-40 est de nouveau la base de l'élément influencer_score (avant sa normalisation). Elle tient compte des probabilités des anomalies individuelles sur lesquelles une compagnie aérienne précise a une influence, et du niveau d'influence que cette compagnie exerce dessus.
Notez que la sortie contient également un élément initial_influencer_score de 98,5096, qui était le score au moment du traitement du résultat, avant que les normalisations ultérieures l'ajustent légèrement à 97,1547. Ceci est dû au fait que la tâche de ML traite les données dans l'ordre chronologique et ne fait jamais machine arrière pour relire d'anciennes données brutes dans le but de les analyser/examiner une nouvelle fois. Notez également qu'un deuxième influenceur, la compagnie aérienne AWE, a été identifié, mais que son score d'influenceur est si faible (arrondi à 0) qu'il convient de l'ignorer sur le plan pratique.
Étant donné que l'élément influencer_score correspond à une vue globale sur plusieurs détecteurs, vous pouvez remarquer que l'API ne renvoie pas les valeurs réelles ou les valeurs types pour le nombre ou la moyenne des temps de réponse. Si vous avez besoin d'accéder à ces informations détaillées, elles restent disponibles au cours de la même période en tant que résultat d'enregistrement, comme illustré auparavant.
Attribution de scores d'intervalles
Le dernier moyen d'évaluer le caractère inhabituel (tout en haut de la hiérarchie) consiste à se concentrer sur la période, notamment l'élément bucket_span de la tâche de ML. Des choses inhabituelles se produisent à des moments précis et il est possible qu'un ou plusieurs (ou de nombreux) éléments puissent être inhabituels au même moment (dans le même intervalle).
Par conséquent, l'anormalité d'un intervalle de temps dépend de plusieurs choses :
- l'ampleur des anomalies individuelles (enregistrements) se produisant dans cet intervalle ;
- le nombre d'anomalies individuelles (enregistrements) se produisant dans cet intervalle ; elles peuvent être nombreuses si la tâche s'est "fractionnée" en utilisant des champs
by_fieldset/oupartition_fields, ou s'il existe plusieurs détecteurs dans cette tâche.
Notez que le calcul donnant lieu au score d'intervalle est plus complexe qu'une simple moyenne de tous les scores d'enregistrements d'anomalies individuels, mais que les scores d'influenceurs de chaque intervalle contribuent à celui-ci.
Reprenons notre tâche de ML de l'exemple précédent, avec les deux détecteurs :
count(nombre) des appels d'API, fractionné/partitionné en fonction deairline(compagnie aérienne) ;mean(responsetime)des appels d'API, fractionné/partitionné en fonction de laairline(compagnie aérienne).
Analyse des résultats dans "Anomaly Explorer" :
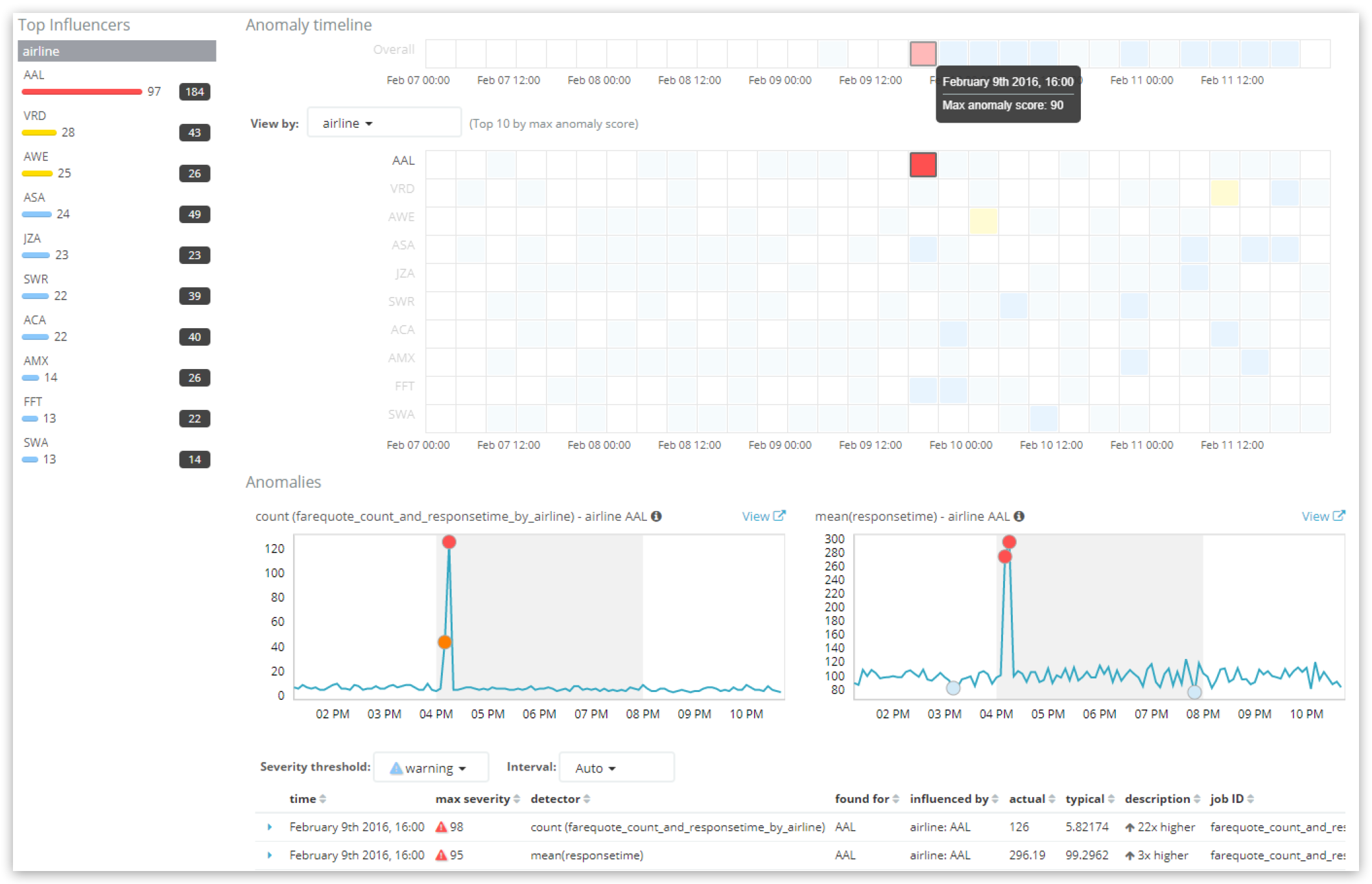
Notez que la ligne "overall" (global) de l'élément "Anomaly timeline" (calendrier des anomalies) en haut de la vue indique le score de l'intervalle. Toutefois, soyez prudent. Si la période sélectionnée dans l'interface utilisateur est vaste, mais que l'élément bucket_span de la tâche de ML est relativement court, une "vignette" de l'interface utilisateur peut alors correspondre à plusieurs intervalles regroupés.
La vignette sélectionnée affichée ci-dessus présente un score de 90 et il existe deux anomalies d'enregistrements critiques dans cet intervalle, à savoir un pour chaque détecteur présentant des scores d'enregistrement de 98 et 95.
Lorsque vous interrogez l'API au niveau des intervalles :
GET _xpack/ml/anomaly_detectors/farequote_count_and_responsetime_by_airline/results/buckets?human
{
"start": "2016-02-09T16:15:00.000Z",
"end" :"2016-02-09T16:20:00.000Z"
}
les informations suivantes apparaissent :
{
"count": 1,
"buckets": [
{
"job_id": "farequote_count_and_responsetime_by_airline",
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"anomaly_score": 90.7,
"bucket_span": 300,
"initial_anomaly_score": 85.08,
"event_count": 179,
"is_interim": false,
"bucket_influencers": [
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "bucket_influencer",
"influencer_field_name": "airline",
"initial_anomaly_score": 85.08,
"anomaly_score": 90.7,
"raw_anomaly_score": 37.3875,
"probability": 6.92338e-39,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"bucket_span": 300,
"is_interim": false
},
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "bucket_influencer",
"influencer_field_name": "bucket_time",
"initial_anomaly_score": 85.08,
"anomaly_score": 90.7,
"raw_anomaly_score": 37.3875,
"probability": 6.92338e-39,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"bucket_span": 300,
"is_interim": false
}
],
"processing_time_ms": 17,
"result_type": "bucket"
}
]
}
Dans la sortie, notez tout particulièrement ce qui suit :
anomaly_score, il s'agit du score normalisé agrégé (ici 90,7).initial_anomaly_score, il s'agit de l'élémentanomaly_scoreau moment du traitement de l'intervalle (à nouveau, si des normalisations ultérieures ont modifié l'élémentanomaly_scorepar rapport à sa valeur d'origine). L'élémentinitial_anomaly_scoren'est affiché nulle part dans l'interface utilisateur.bucket_influencers, il s'agit d'un éventail de types d'influenceurs présents dans cet intervalle. Comme nous le suspections, suite à notre discussion concernant les influenceurs ci-dessus, cet éventail contient des entrées pour les élémentsinfluencer_field_name:airlineetinfluencer_field_name:bucket_time(qui est toujours ajouté en tant qu'influenceur intégré). Vous avez accès à des informations détaillées concernant les valeurs d'influenceurs spécifiques (p. ex. quelle compagnie aérienne) lorsque vous interrogez spécifiquement l'API à propos des valeurs d'influenceurs ou d'enregistrements, comme illustré plus tôt.
Utilisation des scores d'anomalies pour les alertes
Donc, s'il existe trois scores fondamentaux (un pour les enregistrements individuels, un pour les influenceurs et un pour l'intervalle de temps), lequel est utile pour les alertes ? La réponse est que cela dépend de ce que vous essayez de faire et de la granularité, et donc du nombre d'alertes que vous voulez recevoir.
Si, d'un côté, vous essayez de détecter et de créer des alertes à propos d'écarts importants dans l'ensemble de données en fonction du temps, il est probable que le score d'anomalie dépendant de l'intervalle est plus utile dans votre situation. Si vous souhaitez être alerté des entités les plus inhabituelles au fil du temps, envisagez d'utiliser l'élément influencer_score. Ou encore, si vous essayez de détecter et de créer des alertes à propos de l'anomalie la plus inhabituelle au cours d'un laps de temps, l'utilisation de l'élément record_score pourrait s'avérer plus utile dans votre situation pour faire un signalement ou créer des alertes.
Afin d'éviter toute surcharge d'alertes, nous vous recommandons d'utiliser le score d'anomalie dépendant de l'intervalle, parce qu'il s'accompagne d'une limite en nombre, ce qui signifie que vous ne recevrez pas plus d'une alerte par bucket_span. D'un autre côté, si vous vous concentrez sur la création d'alertes avec l'élément record_score, le nombre d'enregistrements anormaux par unité de temps est arbitraire, et il se peut qu'il y en ait plusieurs. Souvenez-vous de cela lorsque vous créez des alertes en vous servant des scores d'enregistrements individuels.
Documentation complémentaire :