



Neu bei Elasticsearch: Elastic Cloud Enterprise 1.0 GA
Wir freuen uns bekanntgeben zu können, dass Elastic Cloud Enterprise (ECE) 1.0 jetzt offiziell verfügbar und bereit für den Einsatz in der Praxis ist. Mit diesem neuen Produkt kannst du eine beliebige Anzahl an Elasticsearch-Clustern und Kibana-Instanzen bereitstellen, überwachen und bündeln – und zwar in der von dir ausgewählten Umgebung über eine einzige Konsole.
(Wenn du gleich loslegen möchtest, kannst du ECE ausprobieren und dich direkt selbst überzeugen. Und bestimmt sind auch unser Webinar und die Produktdemo von Interesse für dich.)
Bisher haben wir als Vorbereitung auf die Einführung vor allem über die Architektur des Produkts, die Vorteile für Unternehmen, und die Zielgruppe gesprochen. Heute hingegen möchten wir uns mit der Einführung des Produkts beschäftigen. Wie stellt man sicher, dass ein Produkt wie ECE bei den Benutzern auch Anklang findet? Welche Schritte unterstützen eine gelungene Einführung?
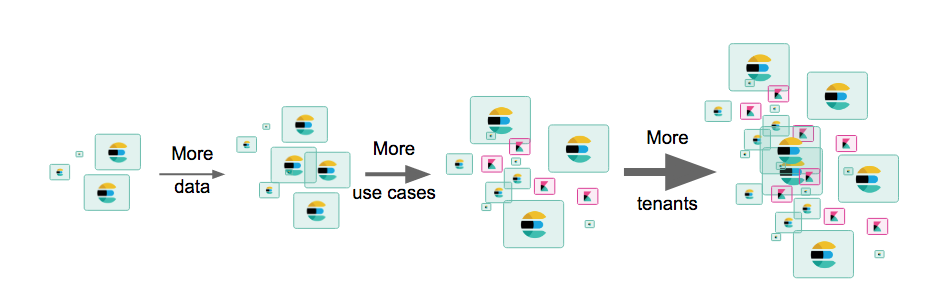
In den meisten Unternehmen unserer Nutzer läuft es so oder so ähnlich: Ein Entwickler in Firma X hat ein Problem mit Daten, stolpert über Elasticsearch, lädt es herunter, installiert einen Test-Cluster, importiert ein paar Daten und hat damit Erfolg. Das bekommt ein Kollege mit, der wiederum eigene Daten hinzufügt und seinen Teil dazu beiträgt, dass das Cluster wächst. Schon bald hat Firma X Dutzende Elasticsearch-Nodes in der Produktionsumgebung, die wichtige, geschäftsentscheidende Funktionen unterstützen.
Und das ist erst der Anfang.
Nehmen wir an, bei dieser Firma X handelt es sich um eine Bank. Der aus mehreren Knoten bestehende Cluster der Produktionsumgebung in dieser Bank unterstützt bisher nur einen einzigen Logging-Anwendungsfall für mehrere Applikationen. Doch nun kommt der Tag, an dem man neue Applikationen für Sicherheits- und Transaktionsanalysen unterstützen möchte. Außerdem haben andere Abteilungen wie Marketing, HR und SRE von Elastic gehört und ebenfalls Interesse angemeldet, dass sie das gerne testen oder es selbst zur Problemlösung einsetzen würden..
An dieser Stelle wird es interessant. Es gibt nun nicht mehr nur ein Problem, sondern viele verschiedene Probleme unterschiedlichster Facetten. Das ist völlig normal, wenn man versucht, die Skalierung in einem Cluster handzuhaben, denn man hat es schließlich mit unterschiedlichen Anwendungsfällen, mehreren Mandanten und immer mehr Daten zu tun.
Das ist zwar aufregend, allerdings auch eine ziemliche Herausforderung. Um genauer zu erklären, was es damit auf sich hat, sollten wir uns zunächst zwei (unabsichtlich existentielle) Fragen stellen: 1) Wer bist du? und 2) Was möchtest du machen?
Zur ersten Frage: Wer bist du?
Wenn du Mandant eines Clusters bist, geht es dir vor allem um die Zeit bis zur Analyse, schnelle Antworten und darum, dass deine Erwartungen erfüllt werden. Aber es wäre unklug, anzunehmen, dass alle Mandanten gleich sind. Sie haben unterschiedliche Wünsche, Gewohnheiten und Anforderungen – von denen jeder einzelne Faktor Frustrations- und Reibungspotenzial bietet.
- Unterschiedliche Zugriffsprofile. Jeder Mandant hat es mit anderen Anwendungsfällen zu tun. Einige nutzen die Volltextsuche oder wünschen sich Vorschläge und Empfehlungen. Andere hingegen müssen ein hohes Volumen an Sicherheitsdaten aggregieren, loggen oder per Scan-and-Scroll durchsuchen.
- Unterschiedliche SLAs. Sicherheitsteams, die Bedrohungen erkennen und aufdecken, können es sich nicht leisten, lange auf Antworten für ihre Analysen zu warten, aber durch ihre massiven Anfragen an das Cluster besteht die Gefahr, dass die SLA-Erwartungen anderer Mandanten negativ beeinflusst werden.
- Unterschiedliche Versionen. Nicht alle Mandanten nutzen die gleiche Version eines Elastic-Produkts. Einige entscheiden sich vielleicht sogar absichtlich aus bestimmten Gründen für eine konkrete Version. Würde man diese Leute z. B. zwingen, ein Upgrade vorzunehmen, ist ein schlechtes Nutzungserlebnis fast schon vorprogrammiert.
Es gibt auch noch andere Punkte, die man berücksichtigen sollte, wie zum Beispiel unterschiedliche Backup-Richtlinien, die zusätzliche Arbeit mit sich bringen oder die Infrastruktur belasten. Oder Mandanten entwickeln massive Benachrichtigungs-Workflows, bei denen massive Datenmengen, wie sie sonst nur in einem Jahr zusammenkommen, abgefragt werden, wodurch der Cluster für andere Mandanten langsam wird.
Wenn du zum Produktionsteam gehörst, das die Elastic-Produkte verwaltet, sind dir ganz andere Dinge wichtig: eine einfache Interaktion mit den Produkten, ein höherer ROI für Projekte oder ganze Abteilungen und die Behebung von kleinen Problemen, damit am Ende nicht das Chaos ausbricht. Aus dieser Perspektive spielen andere Variablen eine bedeutende Rolle.
- Wann werden Wartungsarbeiten durchgeführt? Die Frage wird seit Urzeiten gestellt: Wann sollte man Wartungsarbeiten durchführen, um die Auswirkungen auf das System und die Benutzer auf ein Minimum zu reduzieren? Wie koordiniert man das Ganze über mehrere Zeitzonen und unterschiedliche Nutzungsmuster hinweg?
- Durchführung von Upgrades. Another classic. Upgrading one tenant might impact performance on another tenant that might not need to upgrade (or can't).
- Ein Mandant überstrapaziert das System. Es kann sein, dass interne Kunden mit Zugriffsproblemen zu kämpfen haben, weil ein Mandant umfangreiche Abfragen stellt, die den ganzen Cluster beschäftigen.
- Compliance mit Sicherheitsrichtlinien. Einige Mandanten können ihre Daten aus Sicherheitsgründen nicht in demselben Cluster speichern wie andere Mandanten.s
- Alle lieben Kibana. Im Moment werden Multi-Tenancy-Umgebungen mit mehreren Mandanten von Kibana noch nicht unterstützt, weshalb Benutzer mehrere Kibana-Instanzen brauchen, was wiederum den Verwaltungsaufwand erhöht.
Was macht man also in diesen Fällen?
Die Software funktioniert hervorragend und verspricht Großartiges für die Organisation. Wie sollte das Produktionsteam fortfahren, bevor das Cluster (oder die Motivation) zu bröckeln beginnt?

Das ist jetzt deine Aufgabe…
Eine Option: Aufteilung des Clusters. Wenn du den Cluster in kleinere Teile aufsplittest, verhinderst du einige der von uns angesprochenen Schwierigkeiten, aber das hat seinen Preis.
Du solltest bedenken, dass du dich in diesem Fall um die Implementierung und die Bereitstellung kümmern musst, z. B. mithilfe von Tools für Konfigurationsmanagement und Orchestration. Außerdem müssen unterschiedliche Elastic-Versionen für jeden Cluster gemanagt werden (was sich für Versionen vor 5.x schwierig gestaltet), es müssen verschiedene SLAs unterstützt werden, vielleicht sogar unterschiedliche Infrastrukturarten usw.
Dieser Ansatz kann sich schnell als riskant herausstellen: Wenn der eine Mandant seinen eigenen Cluster bekommt, möchten andere auch einen. Was sich im kleinen Rahmen noch einfach handhaben lässt, wird mit zunehmender Anzahl immer komplexer. Bald läuft das Produktionsteam Gefahr, mehr Zeit mit dem Support von Clustern zu verbringen als mit der eigentlichen Arbeit.
Und hier kommen wir ins Spiel:
Diese Herausforderungen meistert ECE nämlich mit links. Denn all die angesprochenen Anforderungen lassen sich bei dieser Lösung über eine zentrale Konsole steuern und optimieren.
Einen neuen Cluster erstellen, bei Bedarf nach oben oder unten skalieren, mehrere Versionen hosten und Upgrades vornehmen, Kibana und X-Pack aktivieren – überhaupt kein Problem. Du musst nur einmal klicken oder einen API-Aufruf starten. Überwache die gesamte Implementierung über ein zentrales Dashboard, um sicherzustellen, dass alle zufrieden sind. Und dann kannst du dich ganz in Ruhe wieder den Projekten widmen, die für den Erfolg deines Unternehmens verantwortlich sind.
Wenn nun jemand Elastic ausprobieren oder gleich ganz in seiner Produktionsumgebung implementieren möchte, lässt sich das ganz leicht realisieren. Du möchtest einen Proof of Concept durchführen? Starte einen neuen Cluster. Du brauchst vorübergehend eine neue Umgebung? Kein Problem. Du machst dir Sorgen, ob die Hardware mit einem Sicherheitskonzept konform ist? Brauchst du nicht. (Man fragt nicht einfach nach einer neuen VM oder einer eigenen Maschine für Testzwecke…). ECE kümmert sich schon darum. Braucht dein Projekt mehrere Umgebungen für die Qualitätssicherung und die Vorproduktionsphase? Kriegen wir hin!
ECE wurde entwickelt, um diese Probleme zu lösen, und zwar nicht nur irgendwie, sondern gut. ECE basiert auf demselben Code wie unser Elastic Cloud Service, das seit einigen Jahren Abertausende Cluster verwaltet. Im Grunde genommen ist dieses Produkt ideal für alle, die zusammen mit Elastic wachsen möchten. Einer unserer ersten Kunden hat sogar nur 5 Cluster in der Produktionsumgebung und nutzt die vielen Vorteile der zentralisierten Verwaltung des Produkts für zukünftiges Wachstumspotenzial.
Worauf wartest du noch? Überzeug dich selbst und informiere dich mit der Schritt-für-Schritt-Dokumentation.