机器学习异常评分和 Elasticsearch —— 背后的原理
编者按(2021 年 8 月 3 日):这篇文章使用了已弃用的功能。有关当前说明,请参阅使用反向地理编码映射定制区域文档。
我们经常会收到关于 Elastic 的机器学习“异常分数”的问题,以及仪表板中显示的各种分数如何与数据集内个别事件的“异常”相关。了解异常评分是如何表现的,依赖因素是什么,以及如何使用该评分作为主动报警的指标,这将非常有帮助。虽然本博客可能不是完整的最终指南,但是本文的目的是解释尽可能多的关于机器学习( ML )评分方式的实用信息。
首先要认识到的是,有三种不同的方式来思考(并最终评分)“异常”——单个事件异常的评分(“记录”)、一个实体的评分(“影响因素”)如用户或 IP 地址等以及对一个时间窗口的评分(“时段”)。我们还将看到这些不同的分数在某种层次结构中是如何相互关联的。
记录评分
第一种类型的评分,是层级结构的最底层,是某个特定事件发生的绝对异常。例如:
- 在最后一分钟,观察到用户(即管理员)的登录失败率为 300 次
- 特定中间件调用的响应时间值比通常情况下增加了 300%
- 今天下午处理的订单数量远低于典型的周四下午处理量
- 传输到此远程 IP 地址的数据量远远超过传输到其他远程 IP 的数据量
上述每一种情形都有一个计算的概率,一个非常精确地计算出来的值(小到1e-308 )——基于观察到的过去的行为,我们基于此已经为该项目构建了一个基线概率模型。然而,这个原始概率值虽然肯定有用,但可能缺少一些上下文信息,如:
- 当前的异常行为与过去的异常相比如何?有比过去的异常情况更不寻常吗?
- 与其他潜在异常项(其他用户、其他 IP 地址等)相比,该项的异常性如何?
因此,为了让用户更容易理解和区分优先级,机器学习对概率进行了归一化,从而在 0-100 的范围内对项目的不规则性进行排序。此值在 UI 中显示为“异常分数”。
为了提供更多上下文,UI 按四个“严重程度”给异常分数挑选一个标签——“严重”标签用于 75 到 100 之间的分数,“重要”标签用于 50 到 75 之间的分数,“次要”标签用于 25 到 50 之间的分数,“警告”标签用于 0 到 25 之间的分数,每个严重程度用不同的颜色表示。
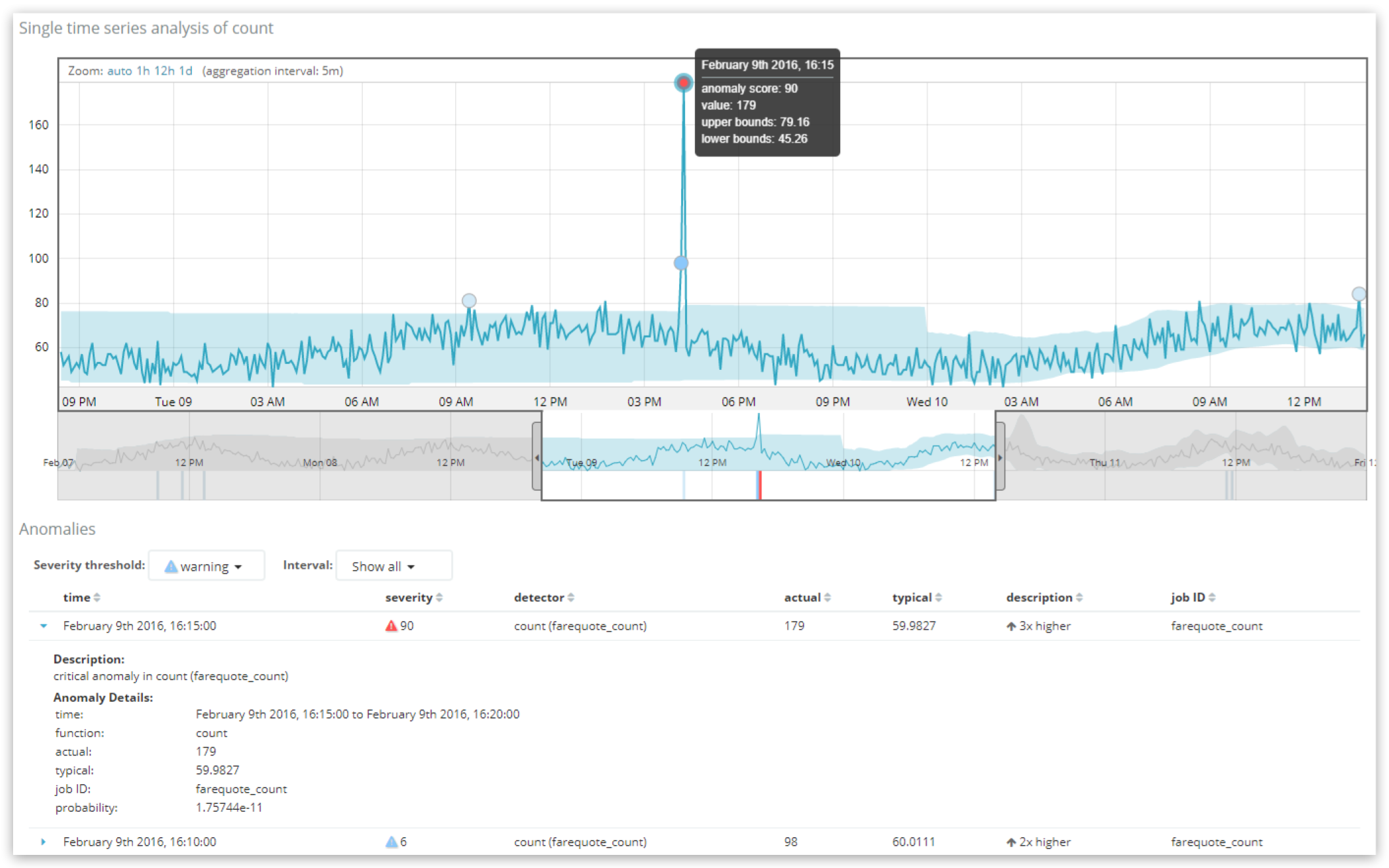
这里我们看到在单个度量查看器中显示的两个异常记录,其中最异常的记录是得分为 90 的“严重”异常。表格上方的“严重度阈值”控件可用于过滤表格中较高严重度的异常,而“间隔”控件可用于对记录进行分组,以显示每小时或每天最高的评分记录。
如果我们去查询记录结果在机器学习的 API 中询问关于特定 5 分钟时间段内异常情况的信息(其中“farequote_count”是作业的名称):
GET /_xpack/ml/anomaly_detectors/farequote_count/results/records?human
{
"sort": "record_score",
"desc": true,
"start": "2016-02-09T16:15:00.000Z",
"end" :"2016-02-09T16:20:00.000Z"
}
我们将看到以下输出:
{
"count": 1,
"records": [
{
"job_id": "farequote_count",
"result_type": "record",
"probability": 1.75744e-11,
"record_score": 90.6954,
"initial_record_score": 85.0643,
"bucket_span": 300,
"detector_index": 0,
"is_interim": false,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"function": "count",
"function_description": "count",
"typical": [
59.9827
],
"actual": [
179
]
}
]
}
这里我们可以看到,在这 5 分钟间隔内(作业的“buckspan”),recordscore为90.6954 (满分 100 分),原始“概率”为 1.75744e-11。这就是说,在这个特定的 5 分钟间隔内,数据量实际上不太可能达到 179 份文档,因为数量“通常”要低得多,接近 60 份。
注意这里的值如何映射到 UI 中显示给用户的内容。1.75744 e-11的“概率”值是一个非常小的数字,这意味着它不太可能发生,但是这个数字的规模是不直观的。这就是为什么将它投影到从 0 到 100 的刻度上更有用。进行这种标准化的过程是专有的,但大致是基于分位数分析,在分位数分析中,历史上在这项作业中看到的异常的概率值是相互比较的。简而言之,作业历史上最低的概率得到最高的异常分数。
一个常见的误解是,异常分数与 UI 的“描述”列中的偏差直接相关(此处为“3 倍高”)。异常分数完全由概率计算驱动。“描述”甚至“典型”值都是情景信息的简化部分,以便于理解异常。
影响因素评分
既然我们已经讨论了单个记录分数的概念,而考虑异常的第二种方法是对可能导致异常的实体进行排名或评分。在ML中,我们将这些贡献实体称为“影响因素”。在上面的例子中,分析太简单了,没有影响因素——因为它只是一个单一时间序列。在更复杂的分析中,可能有辅助字段会影响异常的存在。
例如,在对一群用户的互联网活动的分析中,机器学习作业查看发送的异常字节和访问的异常域,然后您可以将“用户”指定为可能的影响因素,因为这是“导致”异常存在的实体(某些实体必须将这些字节发送到目标域)。将根据每个时间间隔内在这些区域(发送的字节和访问的域)中的一个或两个区域中考虑的异常程度,为每个用户提供影响因素得分。
影响因素得分越高,该实体对异常做出的贡献或应对此负责的程度就越大。这为机器学习结果提供了一个强大的视角,特别是对于具有多个检测器的作业。
请注意,对于所有机器学习作业,除了在作业创建期间添加的任何影响因素之外,还会始终创建一个名为“bucket_time”的内置影响因素。这将使用存储体中所有记录的聚合。
为了展示影响因素的一个例子,我们在一个航空公司机票报价引擎的 API 响应时间调用数据集上设置了两个检测器的机器学习作业:
航空公司上分开/分区的 API 调用的计数航空公司上分开/分区的 API 调用的平均(响应时间)
此时“航空公司”被指定为影响因素。
看看“异常浏览器”中的结果:
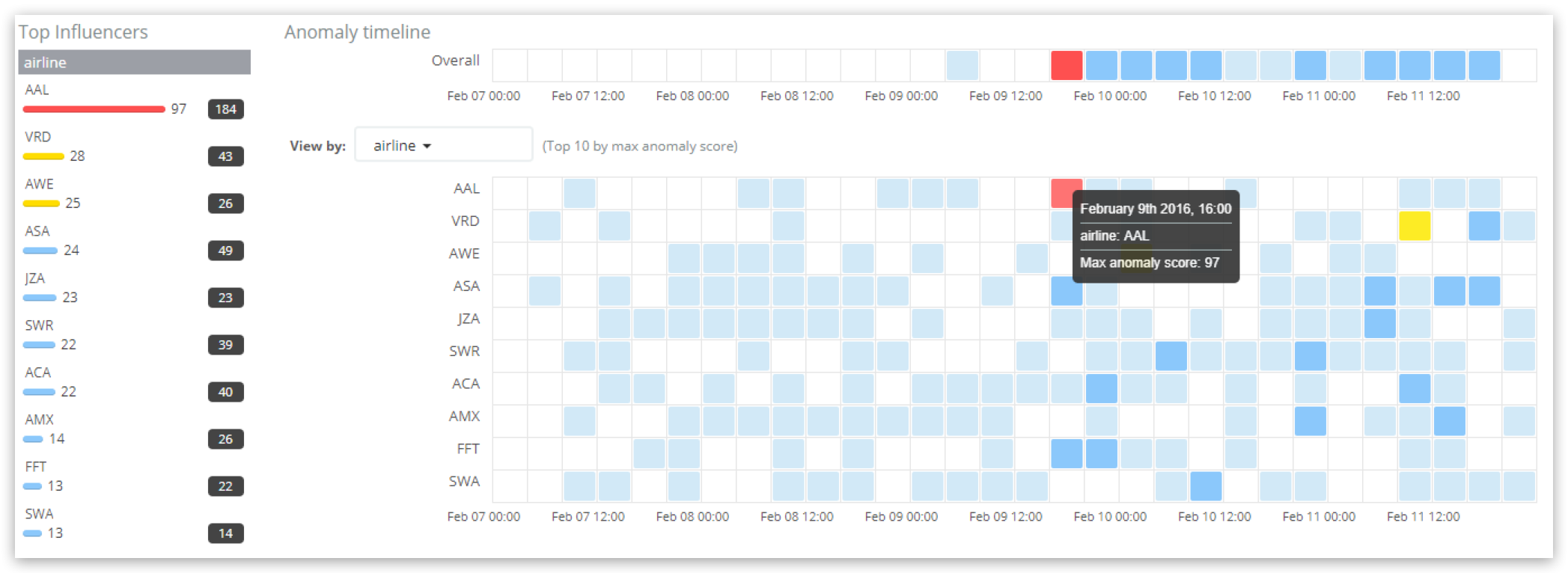
左侧的“顶级影响因素”部分列出了仪表板中选定时间段内的顶级得分影响因素。对于每个影响因素,将显示最大影响因素得分(在任何时段中),以及仪表板时间范围内的总影响因素得分(在所有时段中相加)。这里,航空公司“AAL”的影响因素得分最高,为 97 分,整个时间范围内影响因素得分总和为 184 分。主要时间线是查看影响因素的结果,最高得分的影响因素航空公司被突出显示,再次显示得分为 97 分。注意,航空公司 AAL 的“异常”图表和表格中显示的分数将与其影响因素的分数不同,因为它们显示了个别异常的“记录分数”。
在影响因素级别查询 API 时:
GET _xpack/ml/anomaly_detectors/farequote_count_and_responsetime_by_airline/results/influencers?human
{
"start": "2016-02-09T16:15:00.000Z",
"end" :"2016-02-09T16:20:00.000Z"
}
返回以下信息:
{
"count": 2,
"influencers": [
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "influencer",
"influencer_field_name": "airline",
"influencer_field_value": "AAL",
"airline": "AAL",
"influencer_score": 97.1547,
"initial_influencer_score": 98.5096,
"probability": 6.56622e-40,
"bucket_span": 300,
"is_interim": false,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000
},
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "influencer",
"influencer_field_name": "airline",
"influencer_field_value": "AWE",
"airline": "AWE",
"influencer_score": 0,
"initial_influencer_score": 0,
"probability": 0.0499957,
"bucket_span": 300,
"is_interim": false,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000
}
]
}
输出包含影响航空公司 AAL 的结果,其“影响因素分数”为97.1547,反映了异常浏览器 UI 中显示的值(四舍五入到97 )。6.56622 e-40 的“概率”值再次是“影响因素得分”的基础(在标准化之前)——它考虑了特定航空公司影响个别异常的概率,以及它影响这些异常的程度。
请注意,输出还包含 98.5096 的“initialinformaterscore”,这是处理结果时的分数,随后的标准化将该分数略微调整为 97.1547。出现这种情况的原因是,机器学习作业按时间顺序处理数据,并且再也不会回到重新读取旧的原始数据来再次分析/审核它。还要注意的是,第二个影响因素,航空公司 AWE,也被确定了,但是它的影响因素得分很低(四舍五入到 0 ),在实际意义上应该被忽略。
因为“influencer_score”是多个检测器之间的聚合视图,您会注意到 API 不会返回计数或响应时间平均值的实际值或典型值。如果您需要访问这些详细信息,那么它在记录结果的同一时间段内仍然可用,如前所示。
时段评分
评分异常的最后一个方法(在层次的顶端)是关注时间,特别是作业作业的 bucket_span。不寻常的事情发生在特定的时间,一个或多个(或多个)项目可能同时(在同一时段内)不寻常。
因此,时段的异常取决于几个因素:
- 该时段内出现的个别异常(记录)的幅度
- 该时段内出现的个别异常(记录)的数量。如果作业使用 byfields 和/或 partitionfields 进行“拆分”,或者如果作业中存在多个检测器,则可能会出现这种情况。
请注意,时段分数背后的计算比所有单个异常记录分数的简单平均值更复杂,但是每个时段中的影响因素分数会有贡献。
参考上一个示例中的机器学习作业,使用两个检测器:
技术,在航空公司上拆分/分区平均(响应时间),在航空公司上分开/分区
当查看“异常浏览器”时,
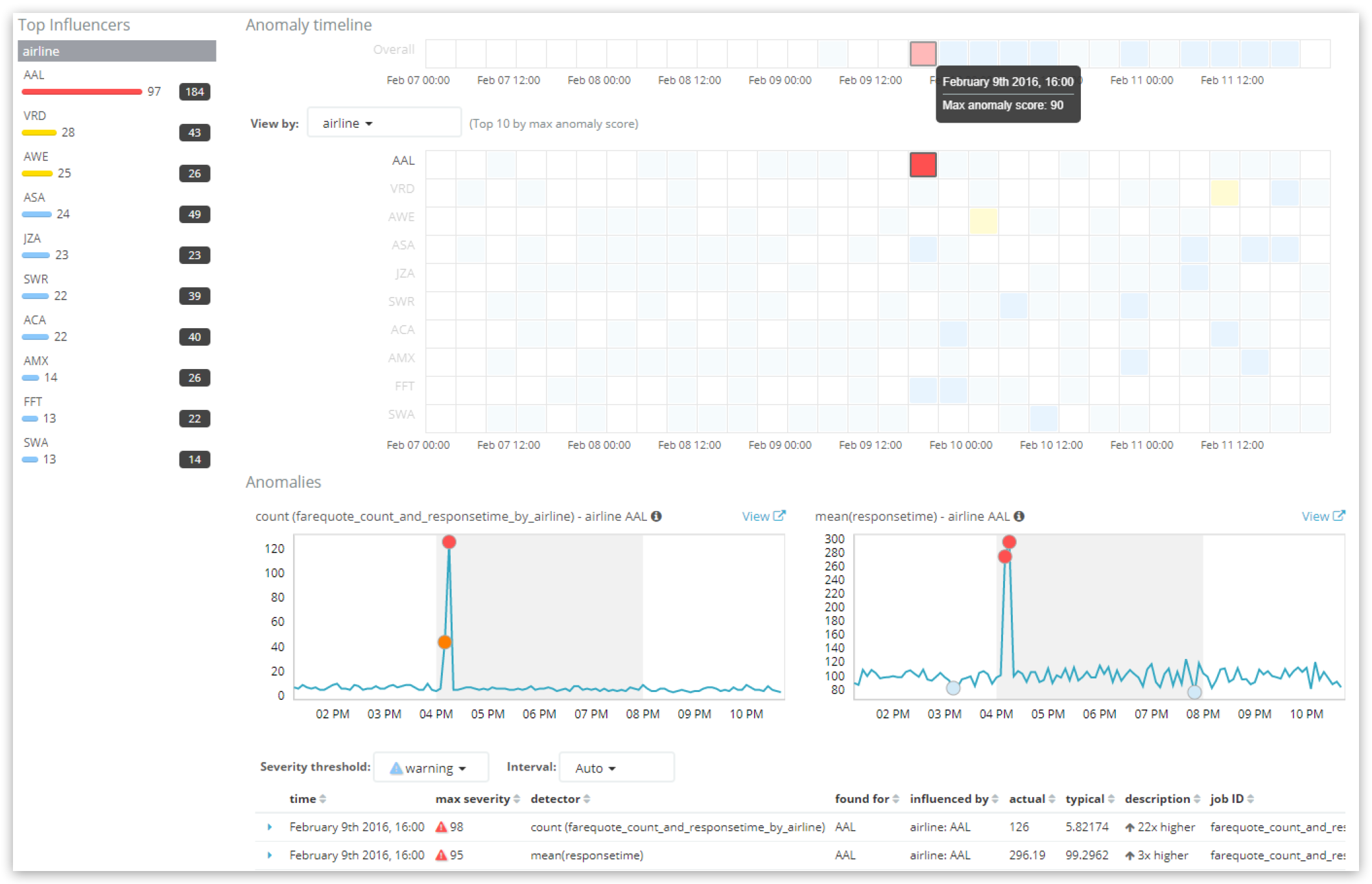
请注意,视图顶部“异常时间线”中的“整体”通道显示了时段的分数。然而,要注意。如果在 UI 中选择的时间范围很宽,但是机器学习作业的“bucket_span”相对较短,那么UI上的一个“标题”实际上可能是聚集在一起的多个存储体。
上面显示的所选切片的分数为 90,并且在这个时段中有两个关键的记录异常,每个检测器有一个记录分数为 98 和 95。
在时段级查询 API 时:
GET _xpack/ml/anomaly_detectors/farequote_count_and_responsetime_by_airline/results/buckets?human
{
"start": "2016-02-09T16:15:00.000Z",
"end" :"2016-02-09T16:20:00.000Z"
}
现提供以下信息:
{
"count": 1,
"buckets": [
{
"job_id": "farequote_count_and_responsetime_by_airline",
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"anomaly_score": 90.7,
"bucket_span": 300,
"initial_anomaly_score": 85.08,
"event_count": 179,
"is_interim": false,
"bucket_influencers": [
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "bucket_influencer",
"influencer_field_name": "airline",
"initial_anomaly_score": 85.08,
"anomaly_score": 90.7,
"raw_anomaly_score": 37.3875,
"probability": 6.92338e-39,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"bucket_span": 300,
"is_interim": false
},
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "bucket_influencer",
"influencer_field_name": "bucket_time",
"initial_anomaly_score": 85.08,
"anomaly_score": 90.7,
"raw_anomaly_score": 37.3875,
"probability": 6.92338e-39,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"bucket_span": 300,
"is_interim": false
}
],
"processing_time_ms": 17,
"result_type": "bucket"
}
]
}
请特别注意,在输出中的下列项目:
异常分数- 总的、标准化的分数(此处为90.7 )initial_anomaly_score- 时段被处理时的anomaly_score(再次,以防以后的标准化改变了anomaly_score的原始值)。UI 中的任何地方都不会显示 “initialanomalyscore”。bucket_informater- 此时段中存在的一系列影响因素类型。正如我们所猜测的那样,鉴于我们上面对影响因素的讨论,这个数组包含了 “influencerfieldname:航空公司” 和 “influencerfieldname:bucket_time” 的条目(总是作为内置影响因素添加)。如前所述,当人们专门针对影响因素或记录值查询 API 时,哪些特定影响因素值(即哪家航空公司)可用的详细信息。
使用异常分数进行警报
因此,如果有三个基本分数(一个是针对个人记录的,一个是针对影响因素的,一个是针对时段的),那么哪一个对警报有用?答案是,这取决于您试图实现的目标,以及您希望接收的警报的间隔和等级。
如果一方面,您试图检测和警告总体数据集随着时间的变化而出现的重大偏差,那么基于时段的异常评分可能对您最有用。如果您想在一段时间内对最不寻常的实体发出警告,那么您应该考虑使用 “influencerscore”。或者,如果您试图在一段时间内发现最不寻常的异常并发出警报,那么使用个人“recordscore” 作为报告或警报的基础可能会更好。
为了避免警报过载,我们建议使用基于时段的异常评分,因为它受速率限制,这意味着每个时段跨度您最多只会收到 1 个警报。另一方面,如果您只是于使用 “record_score” 发出警报,单位时间内异常记录的数量是任意的——可能有很多。如果使用个人记录分数发出警报,请记住这一点。
补充阅读: